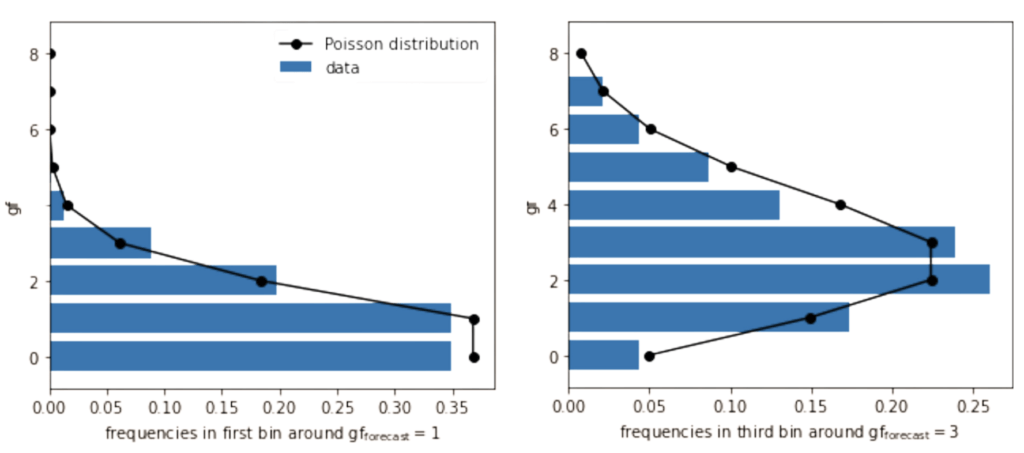
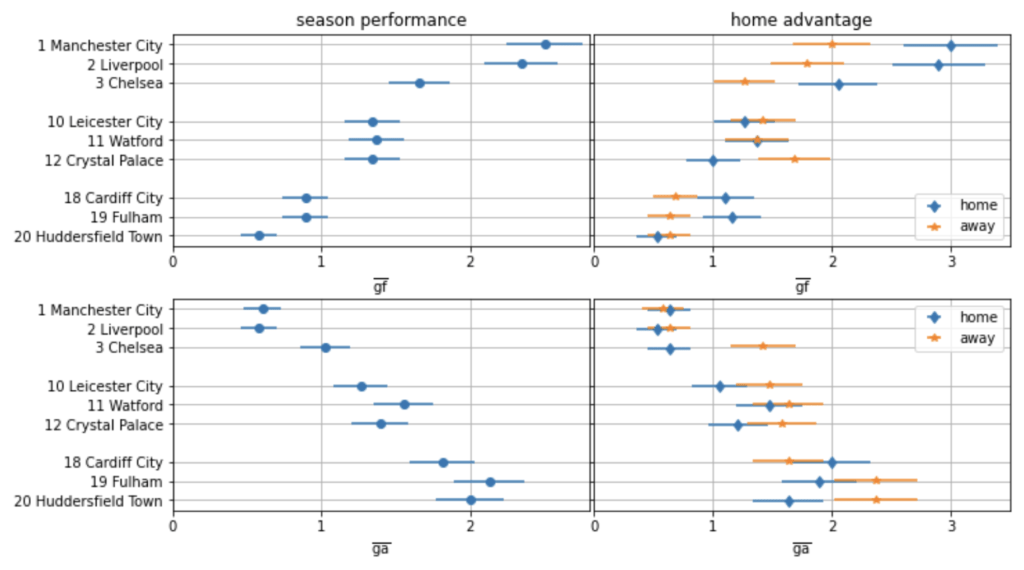
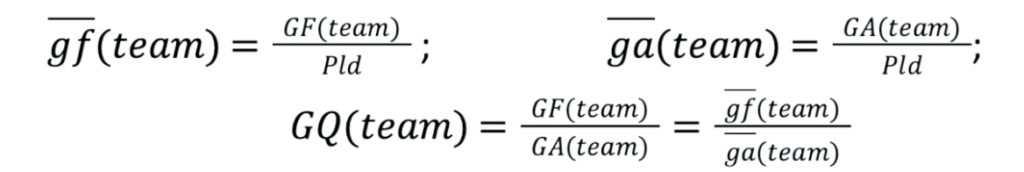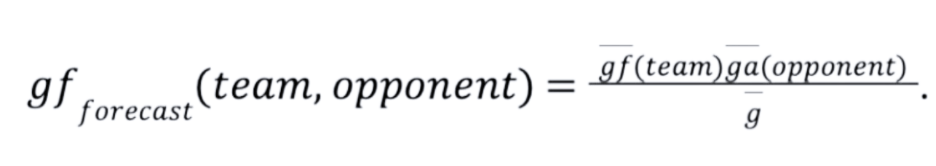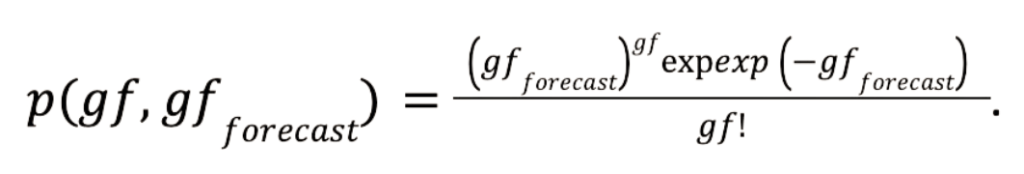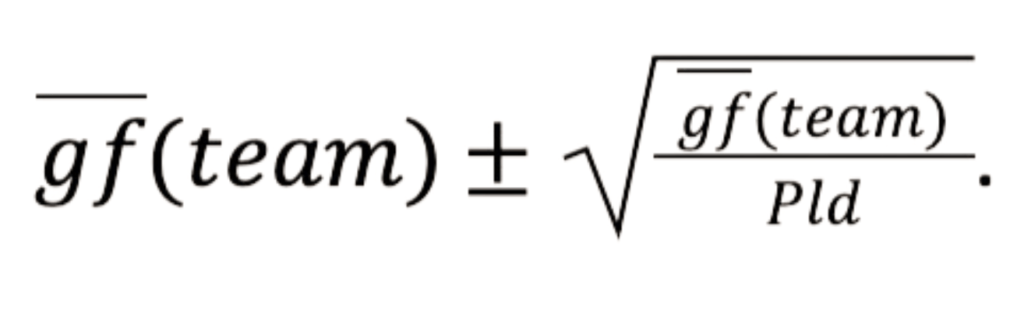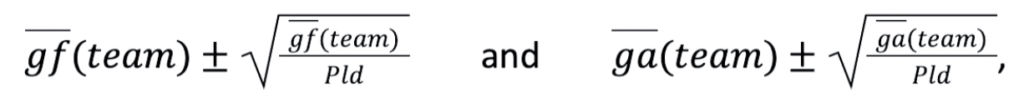Most fans know that football teams often face strong performance fluctuations. One season, a Champions League qualification could seem possible, implying visits to some of Europe’s most legendary football arenas and millions of euros of extra earnings. The next season, there may be a serious risk of relegation, a financial shock which many clubs struggle to overcome. In such a season, the manager might be replaced several times. These fluctuations pose the question of whether it is really possible to judge performance from a few matches. Here, we discuss one of the simplest possible models to forecast the outcome of matches and a whole season. We base our modelling on two features only, the goals for (GF) and against (GA) each team during one season. These features are usually listed in football results tables.
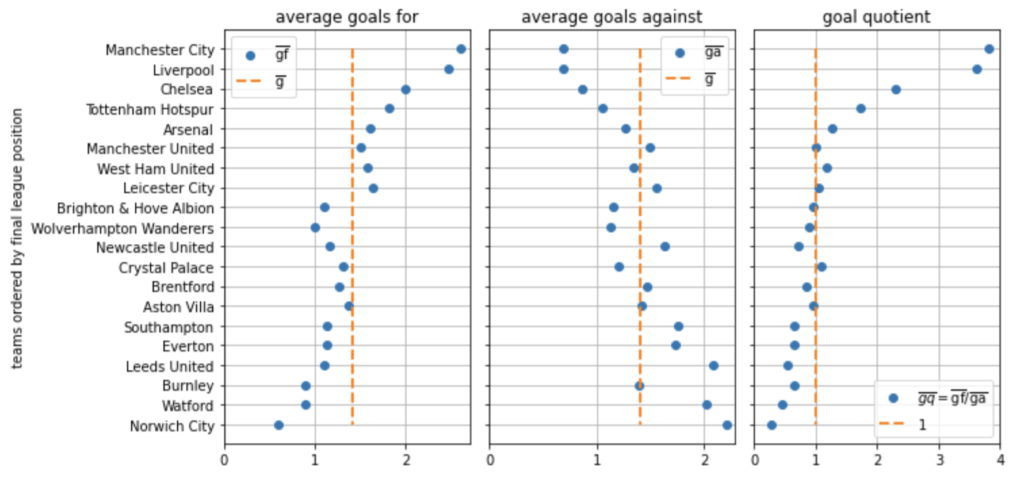
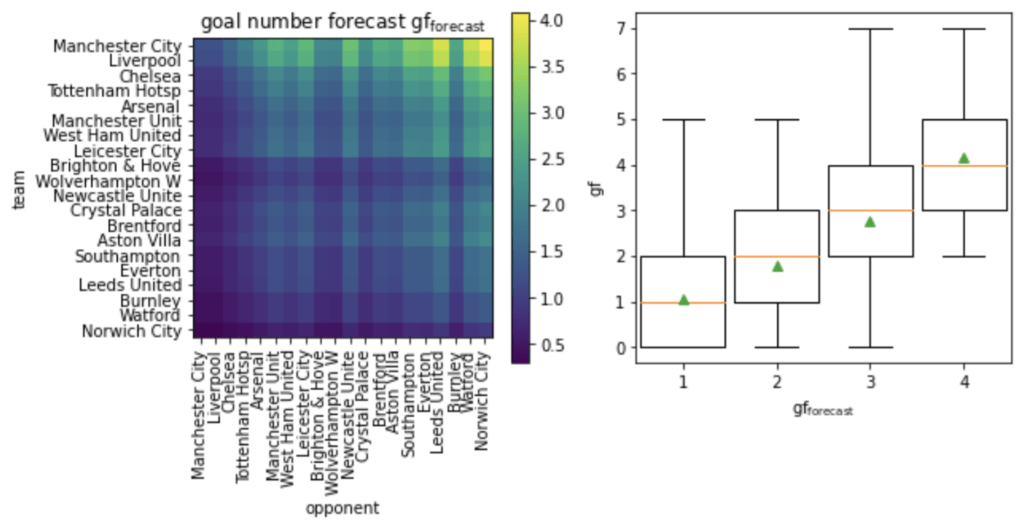
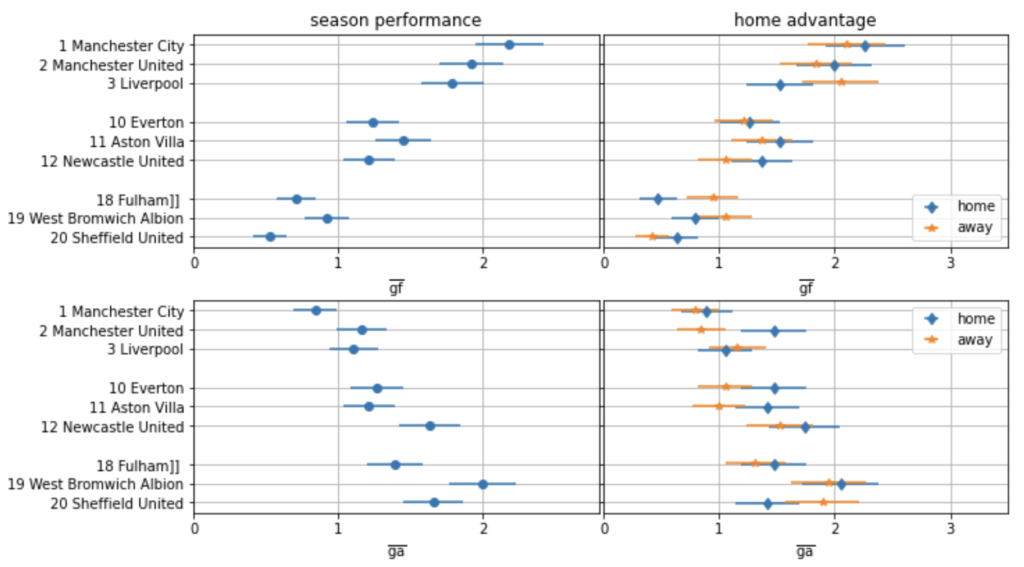
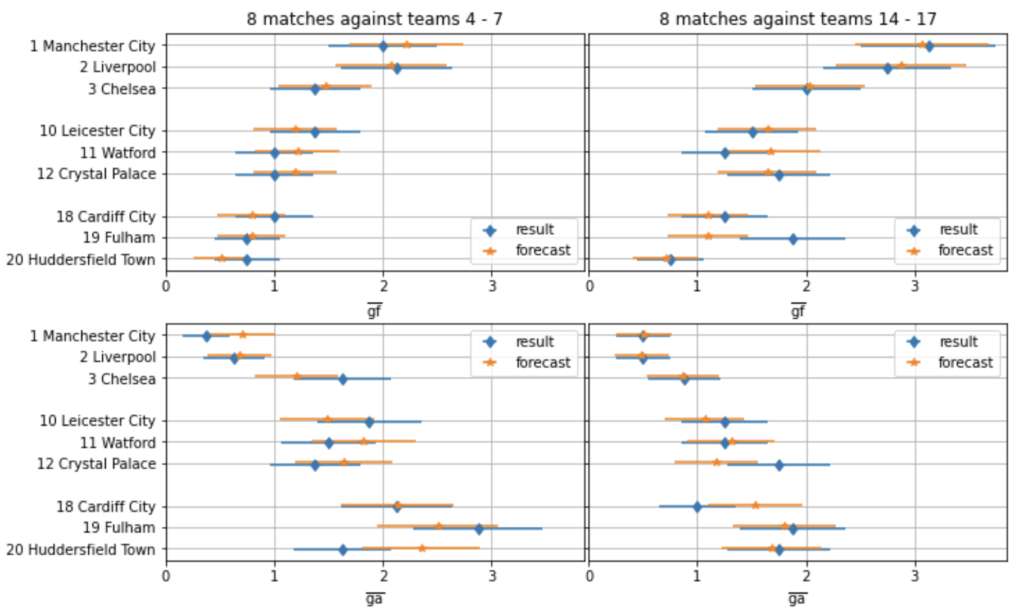
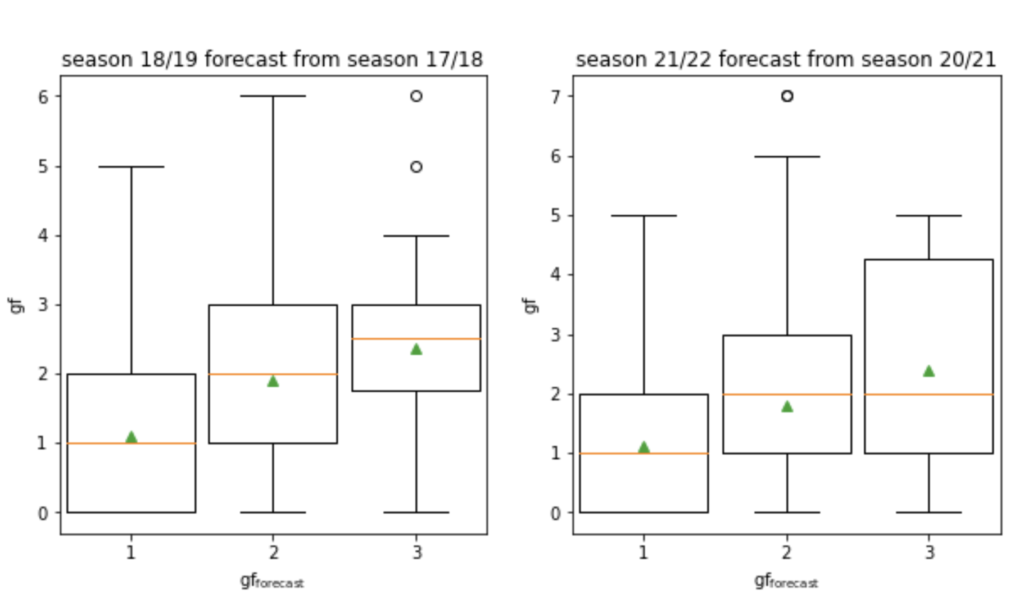
The exemplary table on the left of the following figure covers the 2021/22 Premier League season when twenty teams took part. The model will allow us to judge whether a team under- or over-performed over several matches by predicting the scoring probabilities for each team over all matches played.
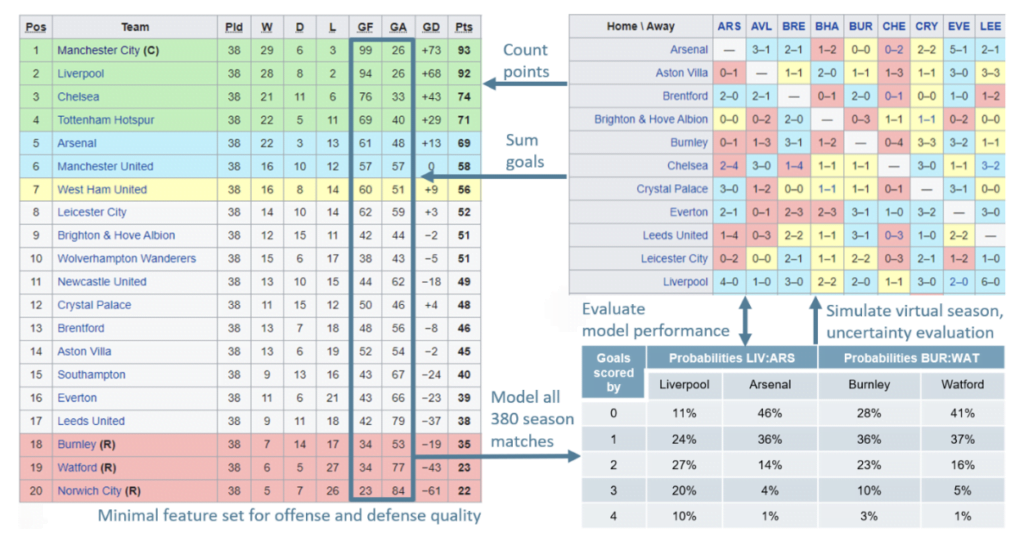
Data preparation and modeling logic
Before we start with our modelling efforts, let us first prepare the input data. The model should work for any league, regardless of the number of matches played. Therefore, we construct scalable metrics such as average goals for (gf) and against a team (ga) per match and a goal quotient, GQ, the ratio of goals scored to goals conceded by each team. These features are comparable across leagues and samples (i.e. over a few games or across multiple seasons):