Data can be harnessed to create value, says Dirk Hofmann. But a data asset isn’t quite like a financial asset, so it can get passed around without changing owners – which is good.
Finland’s co-operative banking group OP Financial is proud of its digital service that allows any customer of a Finnish bank to opt for an installment-payment plan when shopping online at participating retailers. Key to “OP Lasku” is OP’s ability to crunch its own and shoppers’ data to decide creditworthiness in seconds. For the bank, the service is a prime example of turning available “data capital” into “data assets” – products, services and processes that are driven by data. Data is no longer just information that has to be stored at some cost, it is a resource that can be worked to create revenues.
To reinforce the point that it treats data as an asset, OP Financial publishes an annual “Data Balance Sheet”. In 2021, its 3.6 million customers logged into the “OP-mobile” service 40.1 million times a month, up 19 percent, and home-loan applications processed automatically hit 92,000, a jump of 62 percent. Interestingly, the number of so-called APIs connecting OP Financial’s computers with those of external data customers and partners rose by a quarter to 63 – and the real-time data transferred through them rose six-fold to 3,200 terabytes, or 3,200,000 gigabytes, to put it in more everyday units.

These last two numbers highlight something that is too often ignored when we talk about treating something “as an asset”. Assets create economic value, as everyone agrees. But many people forget that because of this, assets have an inherent value, which means they can change hands. OP Financial’s Data Balance Sheet shows that data assets create value and get passed around. The infinite reproducibility of data means that ownership rarely passes from one party to the next, as it does with a financial asset. Rather than sold, data assets are shared (either in return for a fee or access to the other party’s data).
Sharing is an essential part of turning mere data capital into data assets. In a first step, companies harness their own data resources, bringing together the data they already hold in various silos. Different departments share “their” data to optimize the entire business and enable the company to make new offerings. Companies can then increase the value of these assets by allowing fee-paying third parties to access them – so-called data marketplaces, for example, are online stores in which companies can sell their data. In parallel, companies might buy in external data to further boost in-house data assets.
In a final stage, a company can enter data partnerships with one or more external partners, as OP Financial did to make OP Lasku work. Companies exchange data and analytics to create products, services or business models which they could have created on their own. It’s a proposition that already makes sense to many people in different industry sectors. The MIT Technology Review’s 2020 Insights Survey found 81% of respondents in manufacturing were “somewhat” or “very willing” to share data with partners – and still every second respondent in the last-placed financial services sector.
One reason for this is that the opportunities created by sharing are rising constantly as data capital accumulates. The research firm IDC reckons the amount of data created, used and stored will almost double from an estimated 97 zettabytes in 2022 – that’s 97,000 billion gigabytes – to 181 zettabytes by 2030. Huge amounts of data will come from new internet-connected devices, machines and vehicles. McKinsey reckons the number of connected devices in manufacturing, construction and mining, supply chain and agriculture alone will rise from 1.2 million in 2022 to 22.3 million in 2030.
Acknowledging that data is a core asset to a company only goes so far. Companies that can collect and usefully combine data shared by them and different partners will create the most economic value – and increase the value of their data assets in parallel. Connected products, for one, can deliver a company unprecedented data on their status, maintenance needs and overall efficiency. The trick is to combine that and third-party data with the more traditional data streams depicting revenues, costs and profitability. This throws up all sorts of challenges – data comes in different schemas and formats, observe different conventions, be stored and accessed in different ways.
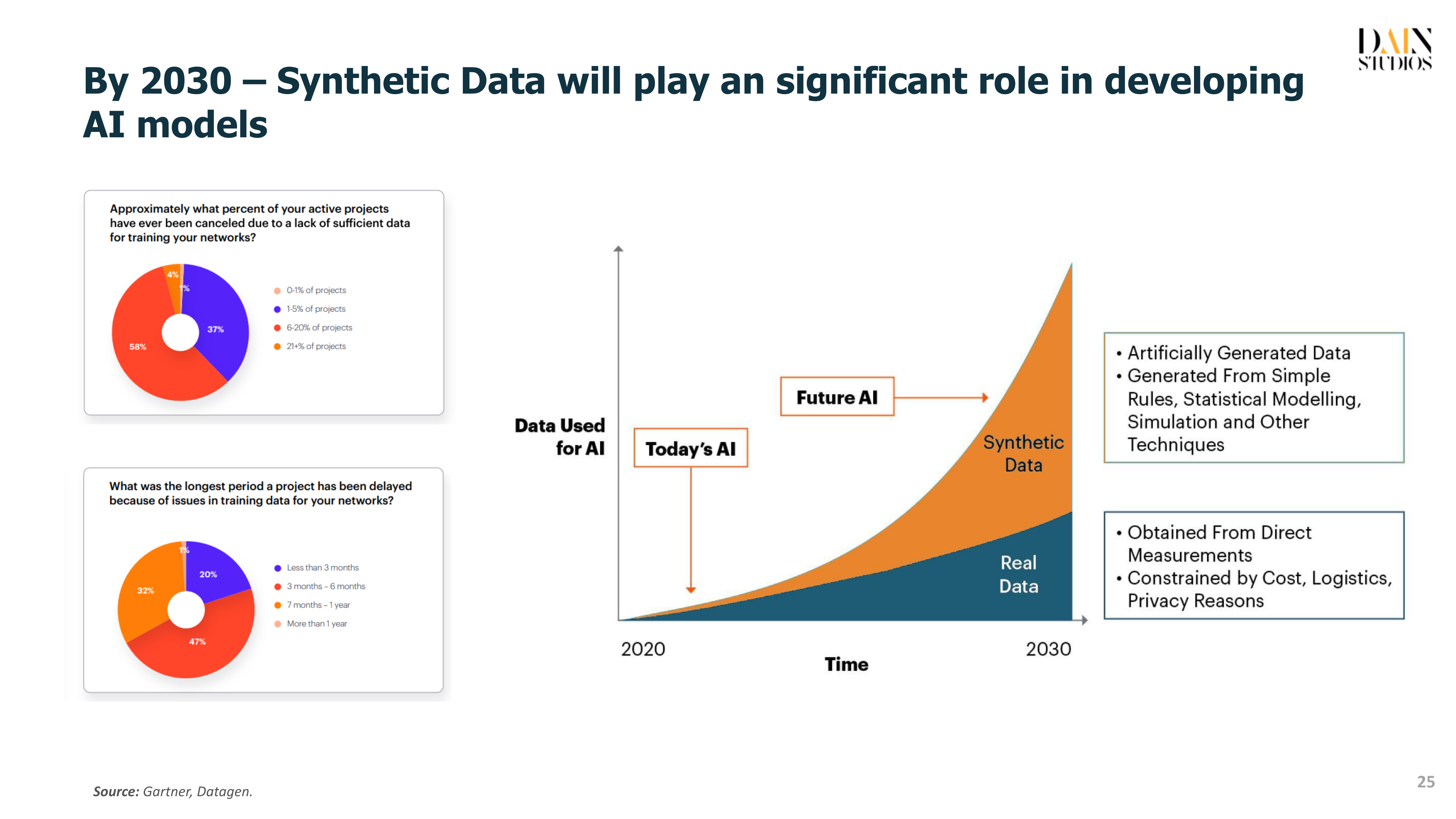
As data volumes and the number of data sources rise, this problem of data dispersion will, ironically, see a shift from big data to something best described as “smaller data”. As ensuring a consistent quality of data becomes ever more important, AI will shift from model-centric to data-centric thinking. AI will no longer be mainly about developing a reliable model with an optimized algorithm that can deal with noise in the data. It will also focus on creating quality data with less noise.
Improving the quality of a company’s underlying data capital will help make it easier to transform into a data asset.