Technology stands at the core of any data & AI transformation. While we have been discussing strategic and human factors so far in previous articles, it is time to turn our attention to the technology itself. It enables today’s organizations to turn data into insights. Technology in the context of data & AI does not only mean the algorithms and functions that generate model output but fundamentally include the associated data assets and the overall architecture that the solution is embedded in. The interplay between these three elements is essential in making data & AI work for you.
This is Part 4 of our four-part article series explaining how we approach and advise our clients on their data & AI transformation journeys, introducing the DAIN Data & AI Maturity Model.
- Part 1 gives an overview of the DAIN Data & AI Maturity Model (DAMM).
- Part 2 dives deeper into the strategic impact drivers.
- Part 3 details the organisational and human enablers.
- Part 4 (this article) gets to the core technologies of data & AI transformations.
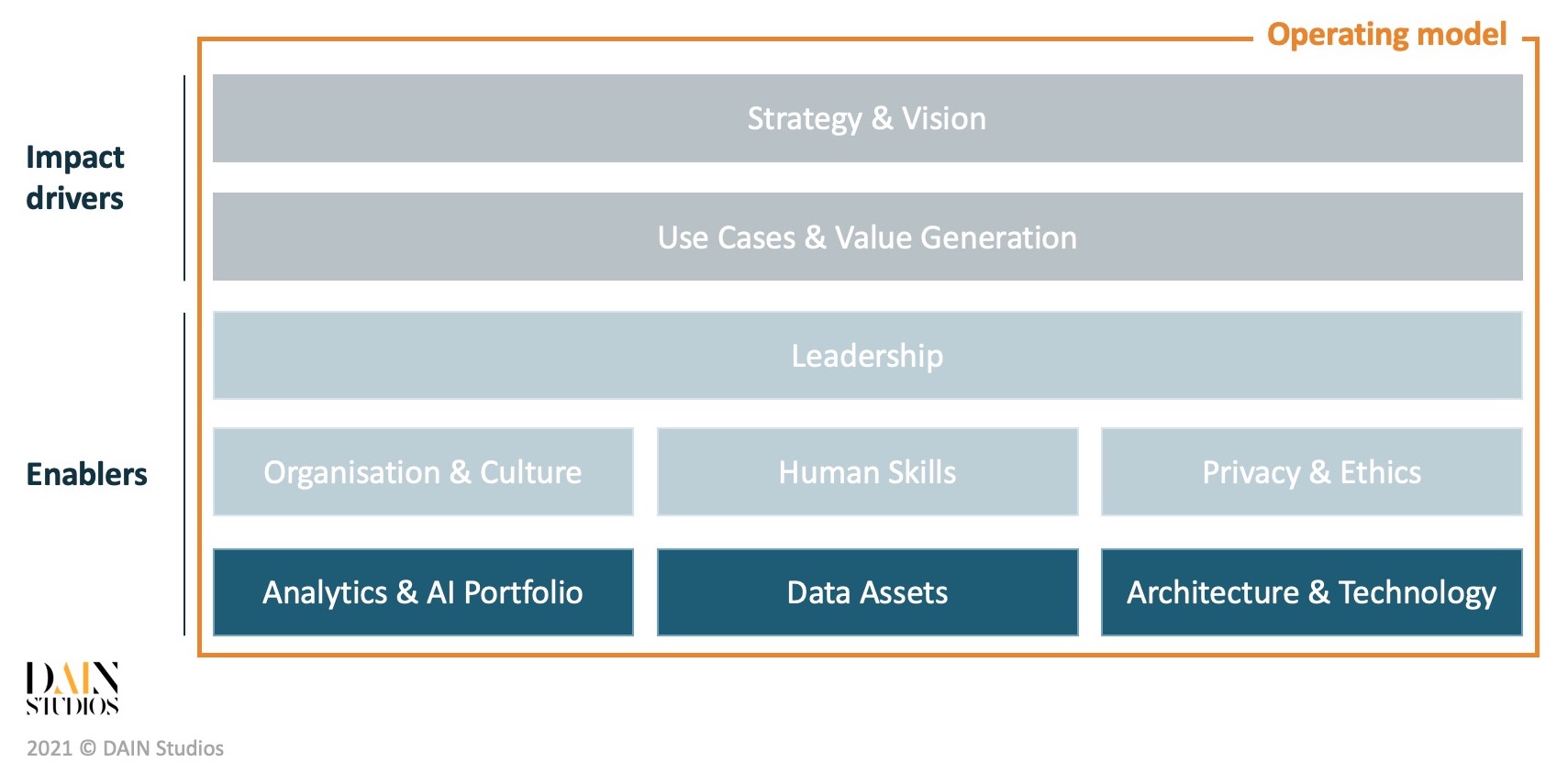
All companies already have data and databases, and many do have data warehouses where data is processed and stored for reports and analysis. So what is so different about working with big data requiring new approaches to data assets, architecture and technology? We start by understanding what an Analytics & AI Portfolio is, before diving into how the underlying Data Assets are to be managed, and finally, take a look at the common Architecture and Technology components that are used to support data & AI use cases.
What does a mature analytics & AI portfolio look like?
The analytics and AI portfolio comprises a wide set of analytics solutions, starting from simple reports, visualisations through automated dashboards all the way to applied machine learning solutions providing predictions and decisions to various business problems.
Traditionally business analysts have focused on reporting what has happened, and commonly having a view of one or a few business functions at a time. Modern analytics aims much further than reporting what is known and attempts to predict unknown attributes (be it future or simply undiscovered values), using data that goes far into the history and often spans across various business domains. To enable the use of data across silos, organisations should broaden the scope of analytics, aiming to use a wide range of different data sources and develop a comprehensive picture of what is happening in the business.
Maturity means that the organisation is capable of using advanced techniques if the problem requires, not that deep learning is applied to any problem they face. Having a systematic approach to understanding, selecting and evaluating the right solution is more likely to result in value creation for the business than forcing state-of-the-art algorithms on simple problem sets.
Another important indicator of maturity is how the analytics & AI portfolio moves beyond deployment. Monitoring, testing and upgrading the analytics solutions are necessary to maintain model performance (due to data and model drift). Leading organisations are capable of incorporating the latest functions smoothly, timely and reliably into their existing solutions, not only maintaining but continuously testing and tweaking the models to perform better. Similarly to the widely applied, life-cycle-oriented software development practice DevOps, MLOps is a guided methodology extending the principles of continuous integration/continuous delivery (CI/CD) to re-training and deploying machine learning solutions.
One of the core aspects that differentiates software and hardware development is reusability. Similarly, many analytics solutions can and should be reused within the organisation – at least partially. This requires that the analytics teams maintain a portfolio mindset, creating well-packaged solutions internally, with the ambition that they themselves or other parts of the organisation with similar capabilities can re-use them. Reusability creates benefits by speeding up development that reduces cost and time-to-market and also improves reliability as already tested methods are utilised. To improve reusability organisations should store developed algorithms and create a culture of reusing the methods from the portfolio if they see fit. Analytics teams can use common package libraries, shared development notebooks, feature repositories and many other tools and practices to boost this knowledge sharing.
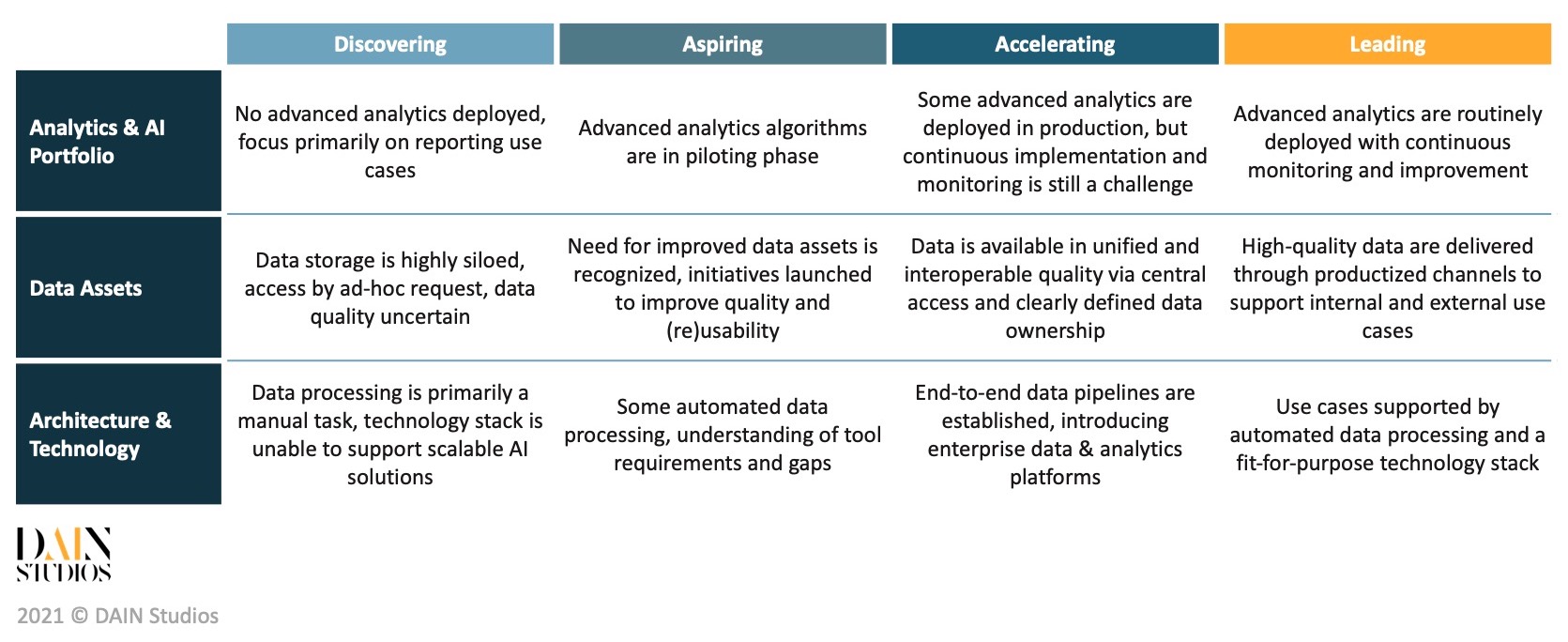
Acknowledge and treat your data as a core asset
Any analytics solution is as good as the data behind it. As a first step, acknowledging that data is a core asset to your company will raise the level of ambition you have with treating this new asset. Ensuring data quality and usability is a real challenge that many organisations struggle with today.
Data quality issues might be easy to spot but the overall quality is a combination of multiple factors. As an example, for a successful marketing campaign, customer data needs to be unique, accurate, and timely. Data quality dimensions capture the attributes that are specific to your business context. In general, there are six traits that you’ll find within data quality: data needs to be accurate, complete, consistent, timely, valid, and unique.
Overall, data assets have more dimensions than the aforementioned quality attributes, as they also need to demonstrate usability. We often evaluate the usability of the data assets according to the FAIR principles (https://www.go-fair.org/fair-principles/). Is the data Findable, meaning does the data have sufficient documentation and metadata supporting it? Can the data be easily Accessed, are access and authentication processes transparent and efficient? Is the data Interoperable, can it be combined with other data sources and integrated into data pipelines effortlessly? And is the data Reusable, is it presented in a format that allows wide usage without significant data wrangling and reformatting? Using the aforementioned dimensions can give you an objective view of the quality and usability of your existing data assets.
The breadth of new data capture is the next important aspect. Most organisations are primarily capturing data generated internally by their core activities, and they are not very systematic in doing so. Many embark on their data journey saying “we first need to make sure that we collect all possible data, later we will figure out what to do with it”. While it is true that not collecting data is a foregone opportunity, collecting large amounts of data without a purpose can introduce significant headaches and storage costs. It is easy to slip into aimless data collection at an early maturity phase, and the longer this practice continues the more likely it is that the data will never be used to generate value for the business. We consistently advise our clients to think through their most important data entities (e.g., customers, products, suppliers) at an early stage and build their data collection around these entities. Leading organisations are able to establish so-called 360 views around their key entities with data captured both from internal activities and external sources in a unified, consistent manner. This is what will make data assets truly rich and useful for analytics purposes.
Collecting, maintaining and orchestrating data of sufficient quality to analytics users and applications are the primary goals of data management. Setting up the data governance principles and practices, assigning clear data responsibilities (ownership, stewardship, etc.) and establishing the decision bodies are fundamental steps in creating a well-functioning data management organisation. A good indicator for data management maturity is a well-defined data ontology, a transparent data catalog, metadata consistently shared across the company, and clearly layered data stored in appropriate solutions. Leading organisations take a data-first approach and aim to productise their data assets such that they could be shared outside the company at any time (if need be) via standardised protocols, such as documented APIs.
Data mesh is a newly arising paradigm that benefits large organisations with disparate datasets serving many applications and end-users. As opposed to common belief, data mesh is not a technology. It is a set of principles that help you organise and govern your data assets in a federated manner. What that means is dividing your data into respective data domains and delegating responsibility to dedicated data product owners, who are responsible for bringing their own data product to their consumers within or outside the company. The main responsibility of the central data infrastructure team becomes setting up and maintaining the technology that enables data product owners and their teams to serve productised data assets to their stakeholders.
Zalando, a highly data-driven European fashion retailer, is one of the leading examples for adopting data mesh to organise their data assets. Their analytics journey goes from having fundamentally centralised data assets in data warehouse(s) to later on establishing a data lake. However, their central data infrastructure team realised that they are facing two fundamental shortcomings: (1) they were becoming the bottleneck in scaling their data assets sufficiently, and (2) there was unclear ownership of the data being served. Creating business domain ownership of the data helped Zalando resolve both problems. The central data infrastructure team’s new responsibility became to maintain the platform that the data product owners use to make their data available through productised channels. Having ownership placed closer to the business puts the responsibility for data assets in the hands of people having the most understanding and influence on the quality of the data.
Designing future proof technology environments for analytics
The role of data architecture is to establish the technological backbone to adequately capture, process and serve data to reporting views, dashboards, end-user applications, models in production, as well as a sandbox to data scientists and analysts for exploratory work and model development. When an organisation is still in early maturity, most data I/O processes are manual or semi-manual tasks. At this point, increasing the level of automation and establishing the first data pipelines should become the primary ambition. If done right, this will eliminate tedious human labor, improve reliability and enable the first analytics use cases to enter production. The first data pipelines will begin to emerge, together with the need to maintain them.
As the vendor landscape is evolving quickly and predicting the future is difficult, it will become paramount to address the constant change in requirements and the technologies serving these needs. Evolutionary architectures are built with this constant change in mind and many leading organisations are now able to design modular, flexible systems, where data pipelines are easier to upgrade, test, rerun without negatively impacting the rest of the architecture.
Next up is the technology stack, serving the data architecture and analytics needs of the organisation. Adequate storage and data processing solutions will fit current and future needs to collect, store and serve the data in various outlets. Today’s cloud providers offer a plethora of services that make it easy to scale and introduce new functionality as needed. Yet, in reality, many organisations will need to combine a mix of local storage, own private cloud or hybrid cloud solutions due to legacy systems and out of information security concerns.
With the rise of modern data and machine learning platforms, data professionals can have access to integrated development environments and deployment services on top of the storage and computation resources provided. Organizations that invest in setting up and maintaining these platforms will see positive effects ripple through their data organisations. They will enable new use cases, attract best-in-class data talent and overall reduce the time-to-production of their analytics solutions. However, to live up to the ambition of becoming data-driven, companies need to focus on bringing analytics closer to every employee, not only data professionals. Self-service business intelligence (BI) applications allow any user with basic knowledge to leverage data in their decision-making process.
Finally, analytics solutions should not live in isolation. Data (or information) architecture is part of the overall IT architecture. One common pitfall in data & AI projects is to solely focus on delivering prediction results from data, not considering how those results will be consumed by other downstream applications. Deploying an analytical solution into other applications usually requires additional work from the application side, requiring collaboration and preparations, as source applications often have their own development teams with separate backlogs and development priorities. Thus, thinking the deployment stage very late can put development on hold for a significant amount of time, which can be particularly frustrating as the organisation has already spent time and effort on solution development. Regardless, tangible business impact will only be achieved with a fully integrated end-to-end solution. To prevent this, time and time again we encourage our clients to consider the end-to-end solution architecture from the early stages of any analytics solution development process. The best approach is to close the loop first, meaning that the development team should focus on creating a simple end-to-end working prototype, before delving further into the development and performance tweaking of the analytics model.
The DAIN Data & AI Maturity Model
This article concludes our series introducing the DAIN Data & AI Maturity Model (DAMM). We started out by giving an overview of the model and subsequently diving into the strategic, human and technology elements.
To quote our first post on the topic: Starting to use Data and AI in an organisation is hard. We have seen many organisations fail in their data transformation and have become aware of the common pitfalls. To get your organisation on the right track, you first need to understand where you are. To help you with assessing your current state we are publishing a Data & AI Maturity Model.
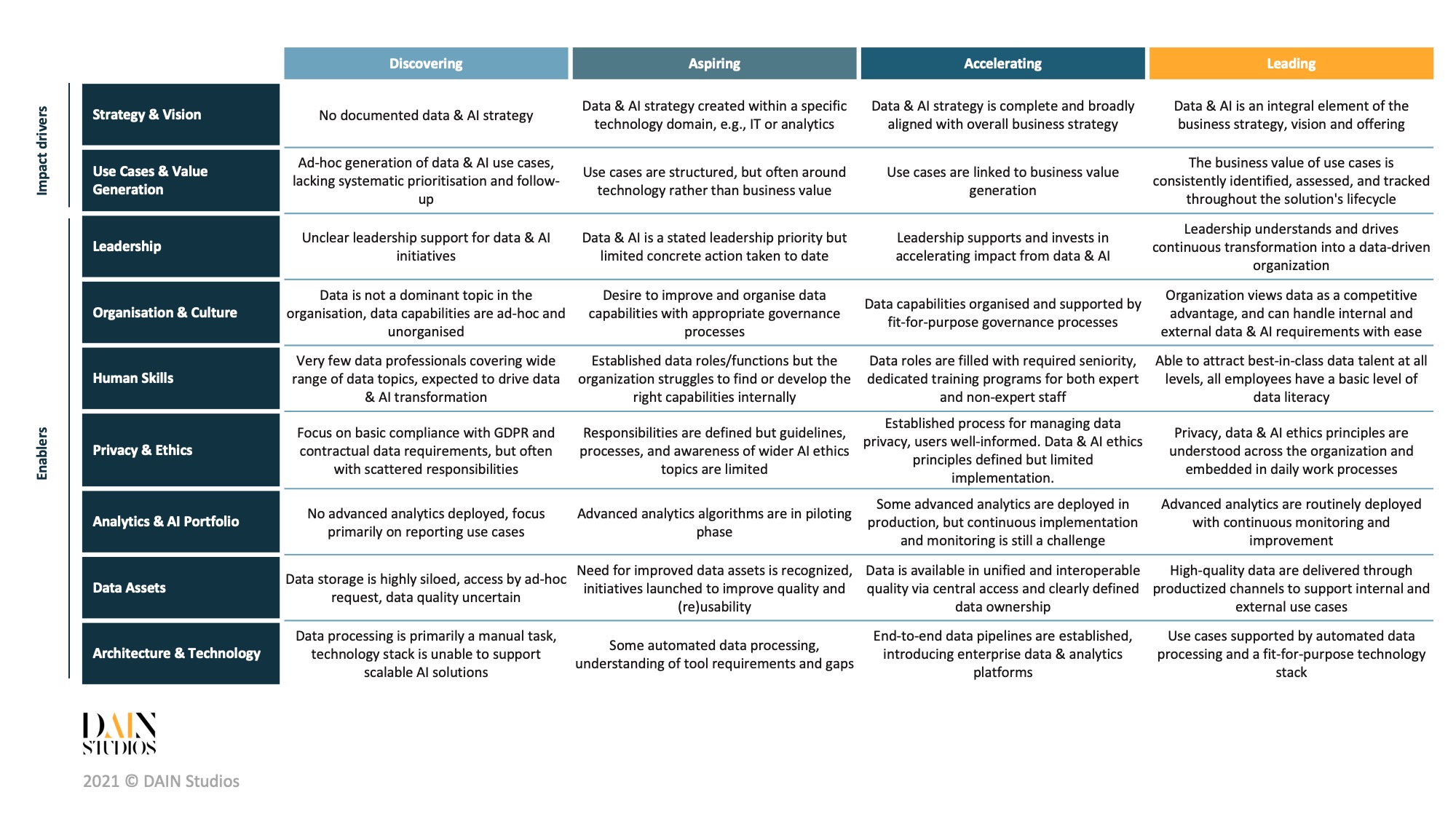
You can use this model as a framework that guides you through your data & AI journey. It highlights the most important elements you should pay attention to, and helps you orient where your organisation stands at the moment. This will in turn help you set a target ambition, so you can derive some consequent actions and form a roadmap to achieve this target state.
This concludes our series describing the elements of our DAIN Data & AI Maturity Model. Be sure to check out our other articles in our DAIN Insights section, where we regularly share our thinking on both strategic and technical topics related to all things data and artificial intelligence.