In the third of four articles about fairness and explainable AI, Sinem Unal describes some methods companies can use to reduce the bias in the ML models.
Applications of AI and machine learning (ML) have been increasingly visible in our lives. An essential component of that rise in popularity is their ability to produce astonishingly accurate results with high performance. An important question however remains on whether ML systems are fair or biased, especially because decisions based on them could have serious impacts on individuals, whether it be in recruiting, banking, or healthcare. Anyone can relate to an anxious wait for a decision on a job or a loan application. ML systems should not make these processes much harder by making them biased.
In the first article of this series, the focus was on the question of fairness and discussion on how companies can ensure their automated decision-making is fair. Of course, fairness can be defined in many ways and therefore companies need to carefully and objectively choose their definition. Once that decision is made, the data science team can get back into the game to build and test their models on this playbook.
Now suppose that you as a data scientist followed those procedures and found out that you have a biased model at hand. What course of action do you have then? Luckily, there are several methods to reduce algorithmic bias and this blogpost will go over those. These techniques can be grouped into three categories based on at which stage they are applied: pre-processing, in-processing and post-processing. Briefly, pre-processing techniques are applied on the data itself, whereas in-processing techniques modify the model. Post-processing techniques, on the other hand, focus on the output of the ML model.
Using tools developed by DAIN Studios, the application of bias mitigation techniques and their implications will be demonstrated on the German Credit Dataset.
Decision on Loan Applications as Example
The dataset consists of a thousand samples from bank account holders which includes information about their account details, financial status and personal information such as age and sex. It also includes whether the person is eligible for a credit or not. A machine learning model is applied to predict whether a given person is eligible for a credit. At the same time the fairness of the model is checked, ie. whether it treats females and males equally. For this problem, statistical parity is selected as the fairness metric. It measures whether the protected (female) and unprotected groups (male) have equal chance of a positive outcome according to the model, in this case getting a loan. The ratio of correct decisions to all decisions was also logged to track the model’s accuracy.
The model is applied on the credit-score data and produced the following measurements:
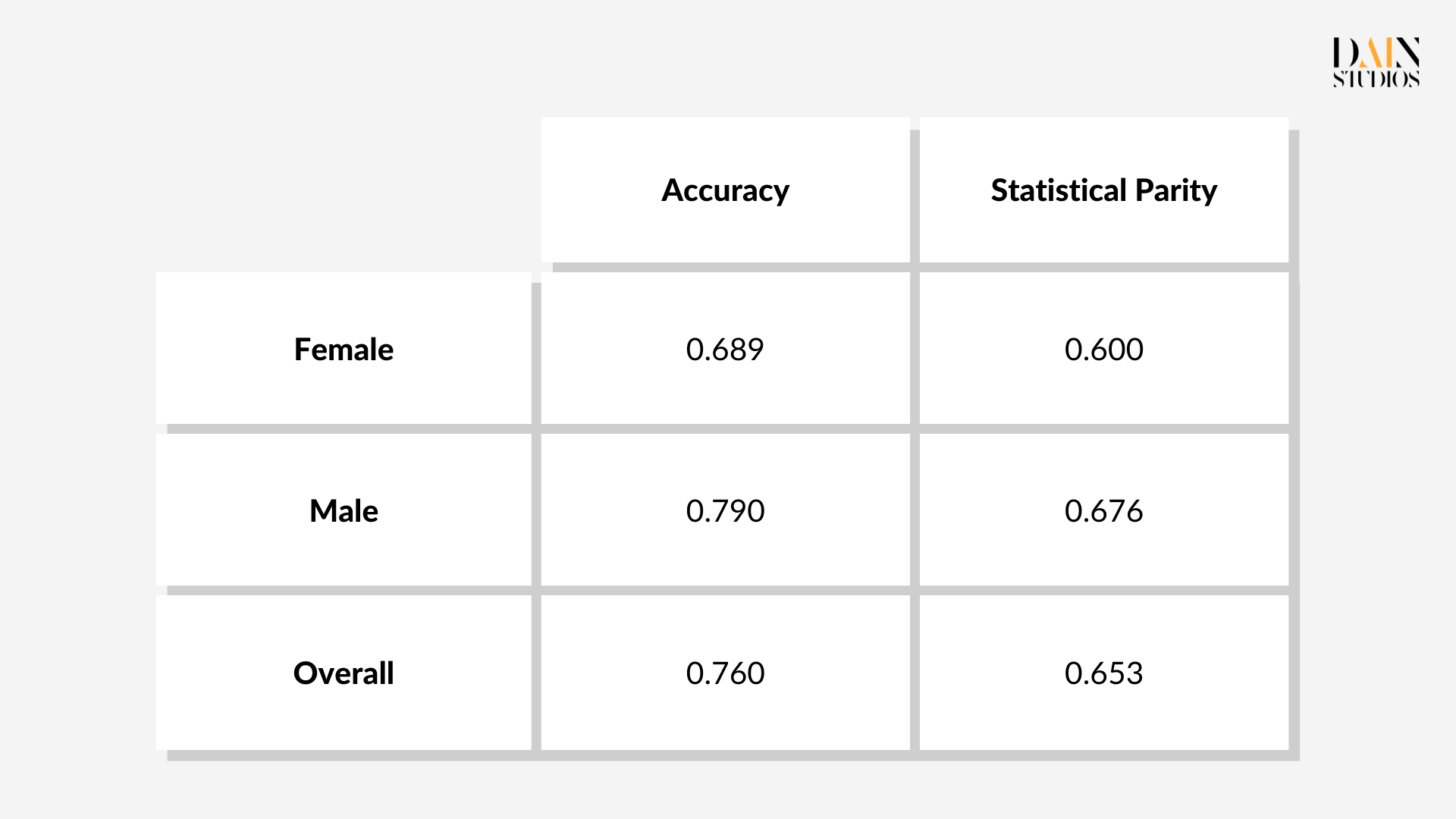
According to the fairness metric Statistical Parity (STP) 68% of males in the dataset are granted a loan, while only 60% of females applied successfully. This 8 percentage-point difference suggests that the ML model can be improved from a fairness standpoint and that “unfairness mitigation” techniques can be applied in order to reduce the difference. As already touched upon above, there are three ways to proceed: change the way the underlying dataset is used to teach the model, revise the ML model’s algorithm, or alter the thresholds that distinguish positive from negative decisions.
Bias reduction techniques: pre-processing
There are several pre-processing techniques that can be applied to the training data. Here the “resampling” of the ML model’s training data is used. Segments of data are under- or oversampled with the aim of balancing out biases. In the German Credit Dataset, for example, 64% of females and 73% of males (the so-called protected and unprotected groups respectively) are actually eligible for credit. What the model will learn from this raw sample is that men are more likely to be eligible for loans than women.
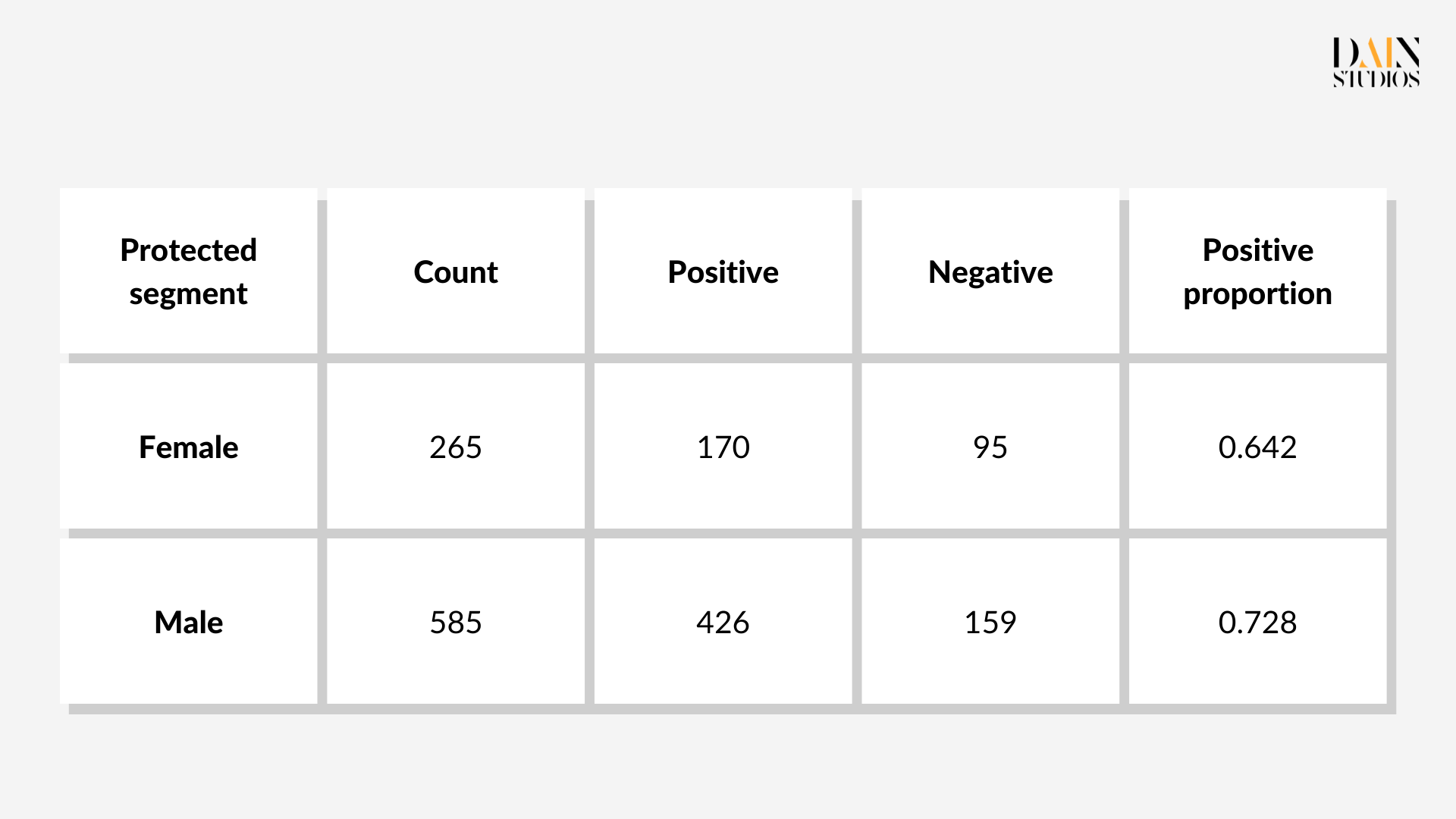
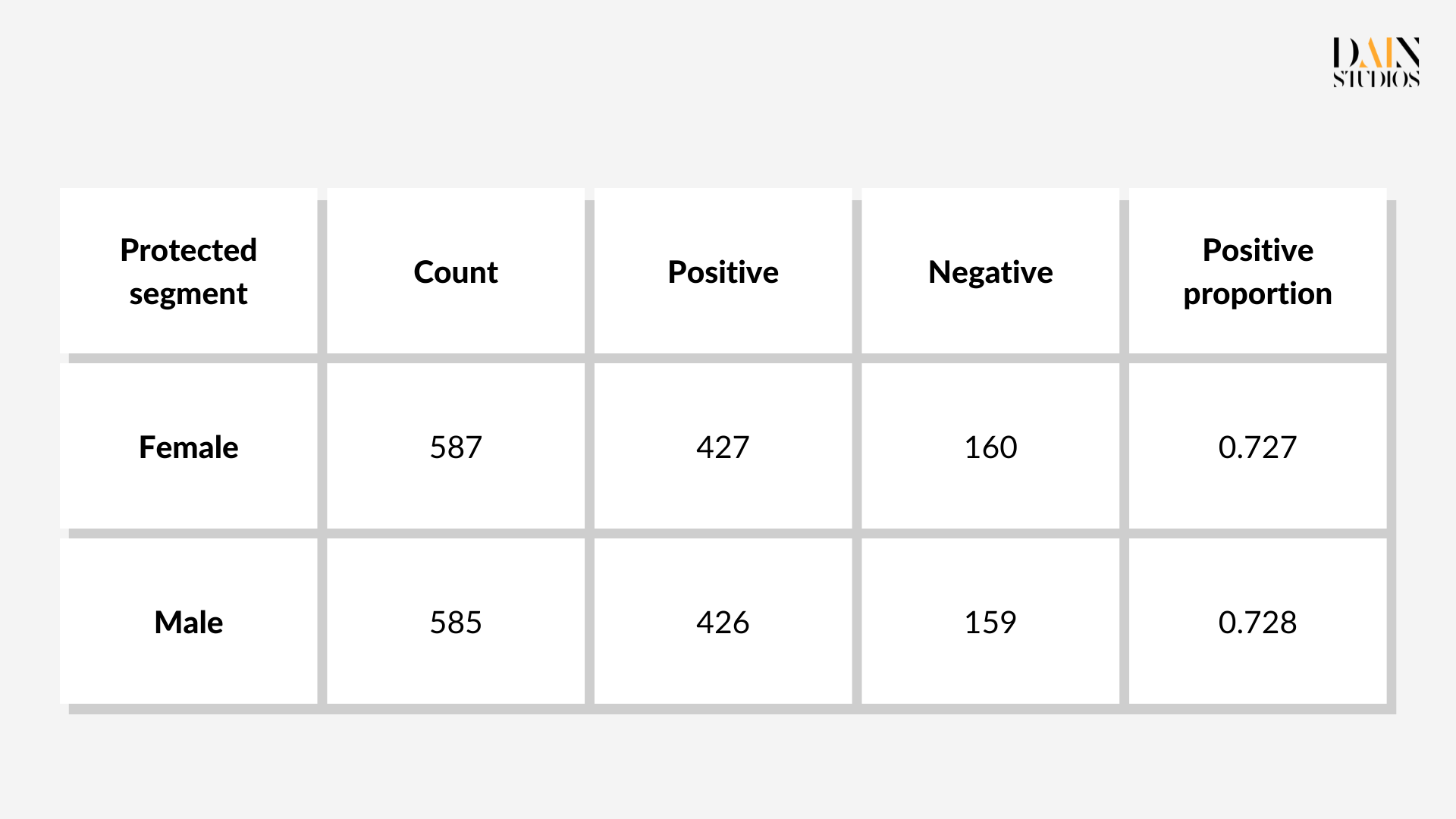
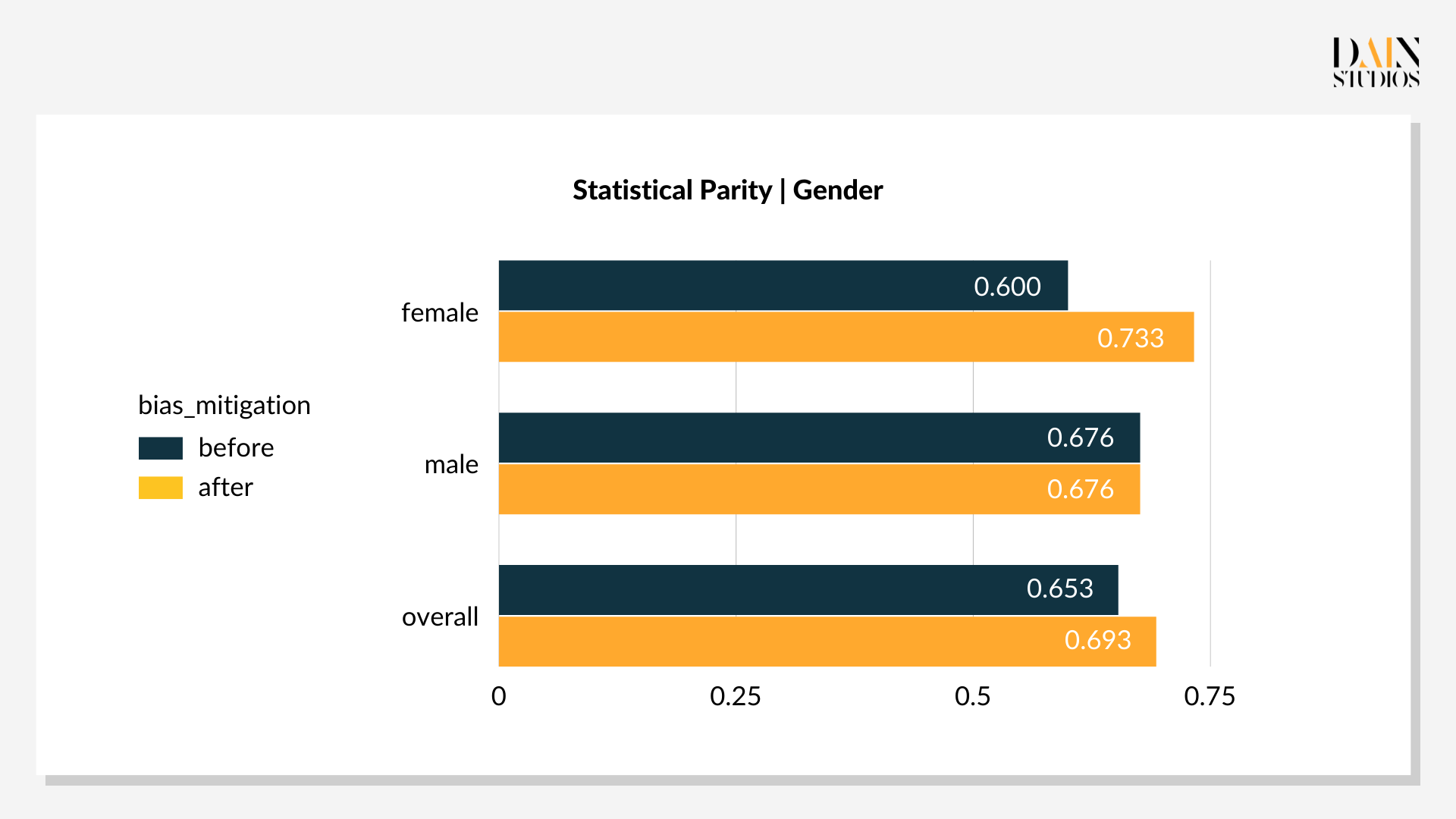
Bias reduction techniques: in-processing
In-processing bias-reduction techniques modify the ML model that makes the loan decisions. Instead of resampling the training data, models can be tweaked to take into account biases it comes across during this learning stage, allowing fair(er) outcomes despite biased data. Among several available methods, Grid Search is applied. This involves creating a sequence of tweaked versions of the initial problem. For details, one can refer to Agarwal et al.
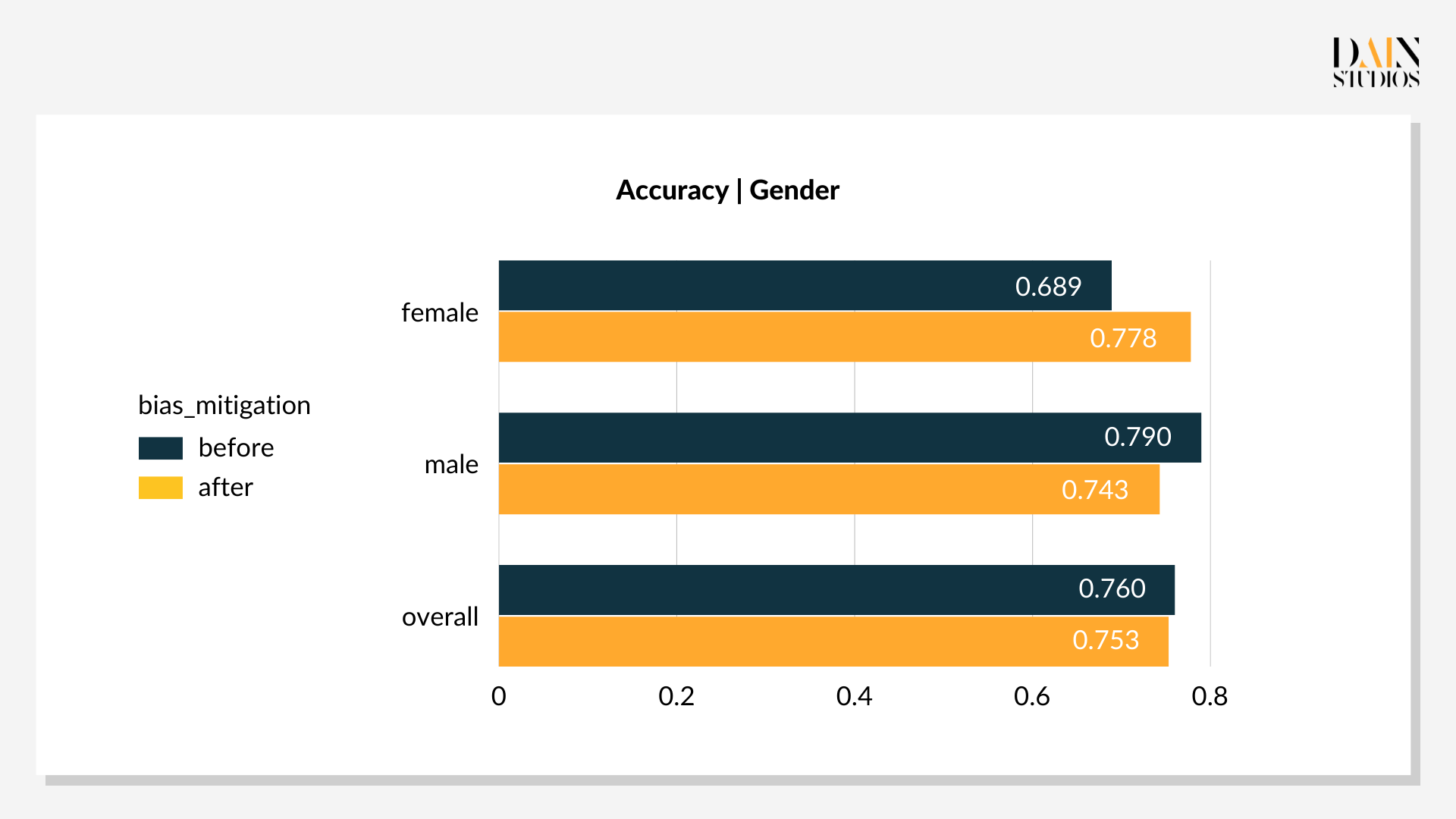
Bias reduction techniques: post-processing
Post-processing techniques target the results of the trained model. As they do not concern themselves with the underlying dataset or the ML model, these methods ignore the inner workings of a model to focus on the result it comes up with.
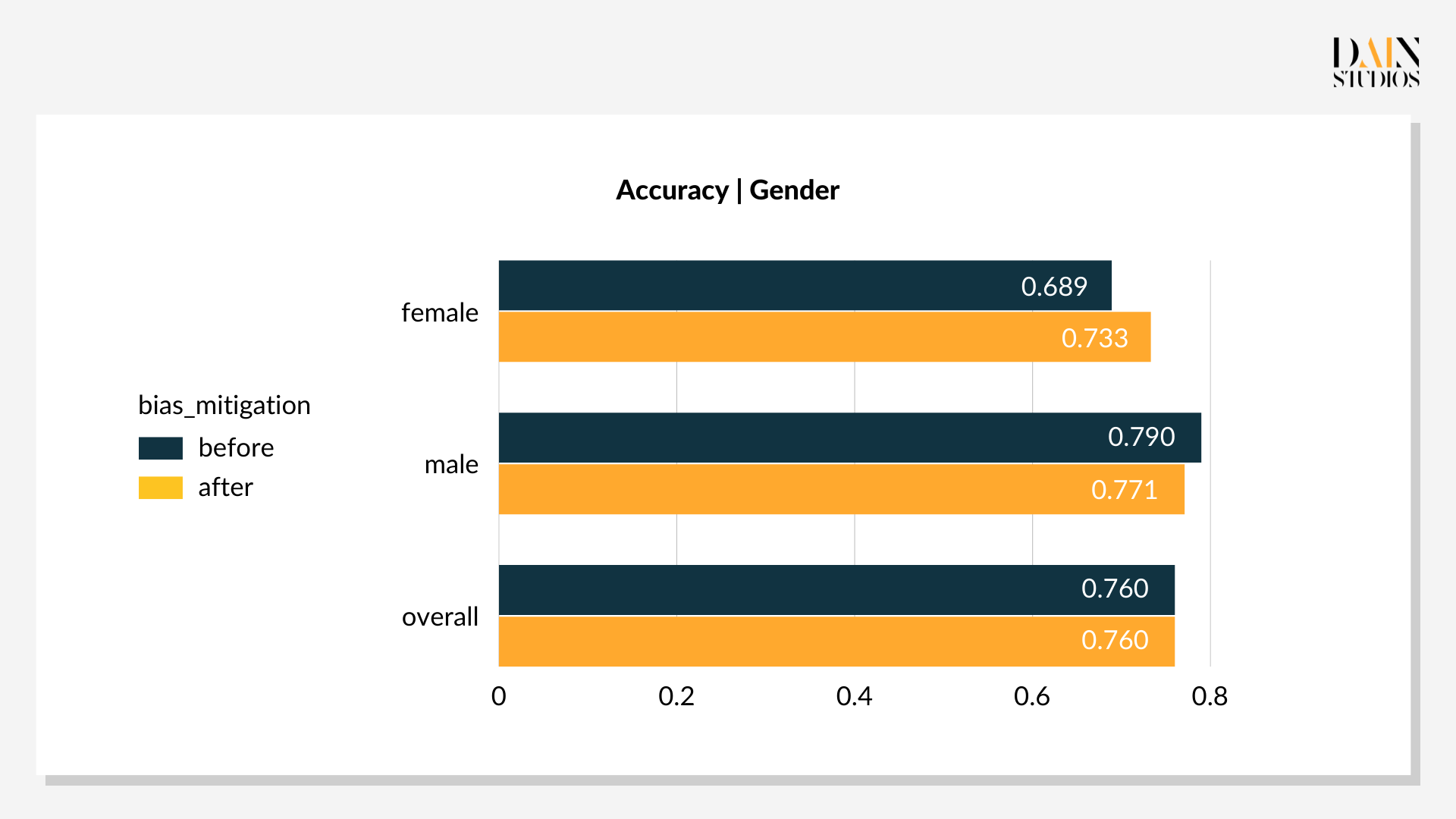
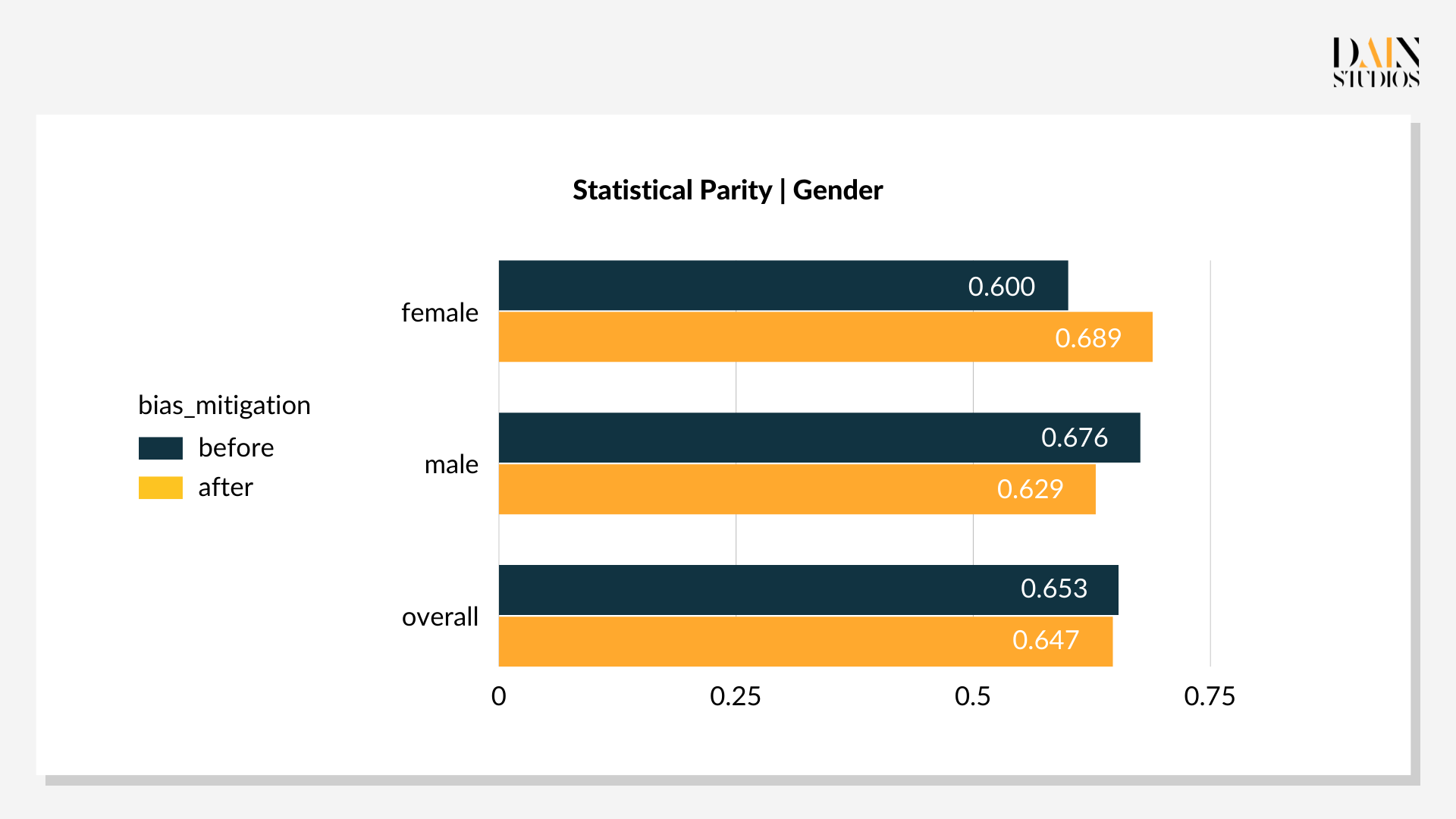
In this example, the model first calculates how likely it is that a certain person is capable of paying back a loan, e.g. person A can pay back the loan with 0.9 probability. Then the model classifies the individual as having good credit risk if their probability is above a certain threshold. By default, the model applies the same threshold value of 0.5 for all applicants when making a decision. However, one can apply different threshold values for certain groups, for example a lower threshold for women to drive more positive loan outcomes. So revising threshold values for female and male applicants in the German Credit Dataset can optimize Statistical Parity.
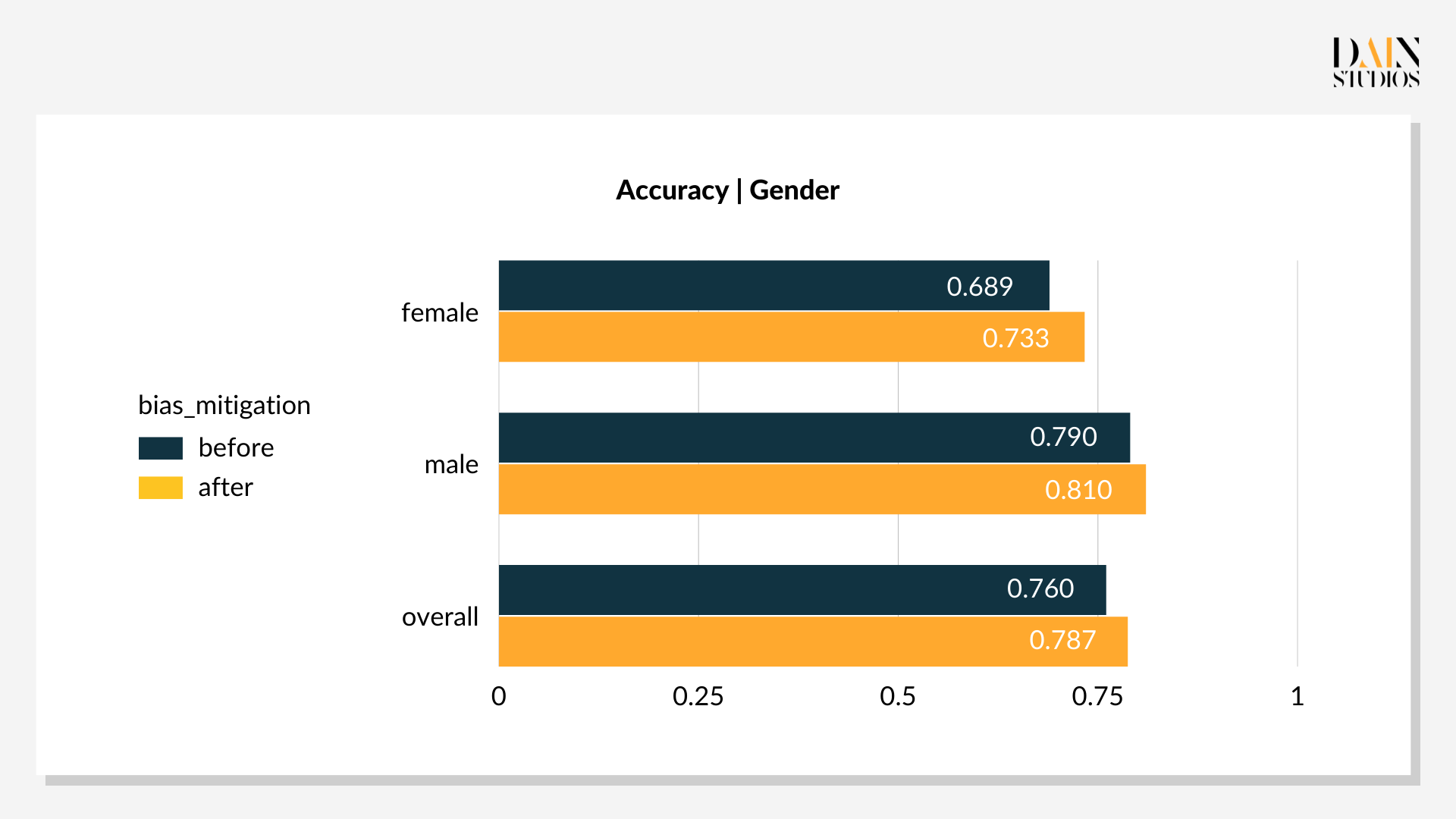
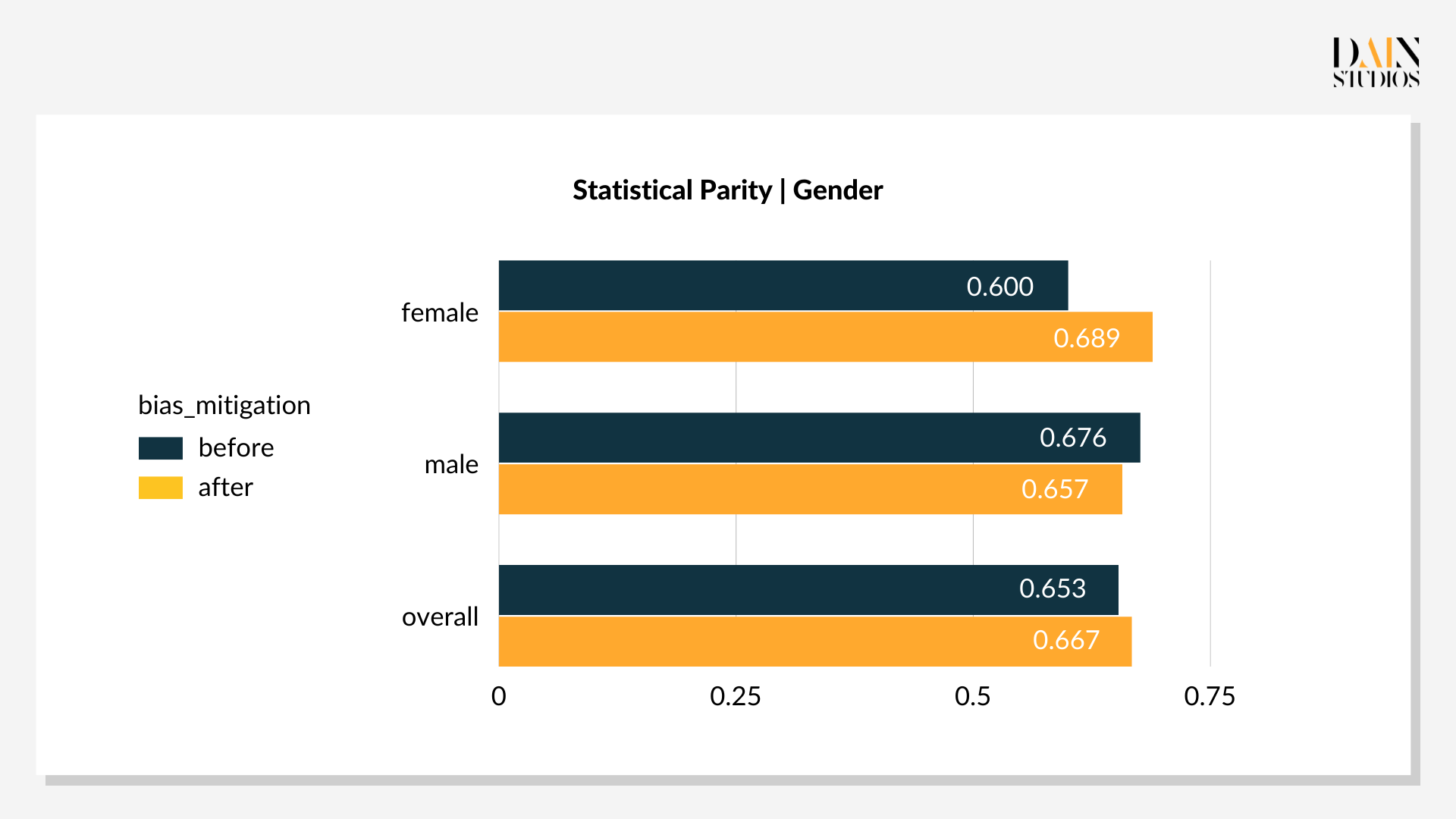
The optimal threshold values are 0.29 for females and 0.59 for males. This lower threshold for female loan applicants and slightly higher one for males results in 69% of women and 66% of men being deemed a good credit risk. The outcome’s three-percentage-point bias towards women is more acceptable than the default result with its eight-point bias towards men. Also, its overall accuracy – the ratio of correct decisions to all decisions – improved by three points to 79%. This demonstrates that post-processing tweaks can not only reduce bias, but also improve the performance of an ML-driven system, benefiting everyone.
Bias reduction and its applicability
The methods show that data scientists have a number of options to tackle biases if they detect a machine learning model is unfair. Each technique can also be seen as a response to the time and resources available. If datasets and models are readily accessible, one can set about identifying suitable pre-processing and in-processing techniques; in their absence, post-processing techniques can be leveraged. It is also worth remembering that the model’s performance is not necessarily impaired.