In the second of four articles about fairness in AI, Paolo Fantinel says understanding ML-driven choices can help companies and their customers.
More and more businesses are relying on artificial intelligence (AI) and machine learning (ML) to make – or help make – decisions more quickly and efficiently. The previous article considered how companies can ensure that such automated decision-making is fair, this one looks at the connected issue of “explainability”, or the ability to understand ML-driven choices that might seem odd. It enables businesses to identify and remove biases lurking in their algorithms and helps people on the receiving end of unwelcome decisions to potentially remedy the situation.
Take a person deemed creditworthy, but refused a loan. Using tools developed by DAIN Studios, an ML model crunched through the German Credit Dataset of 1,000 loan applicants to award them good (1) or bad (0) credit scores. One woman received a score of 1, but was not given a loan in real life. A closer look shows that the model calculated the probability of her repaying the loan at 54%, putting her on the right side of the model’s 50% threshold for rounding scores up to 1, although her underlying score was obviously still deemed too risky.

What-if analysis
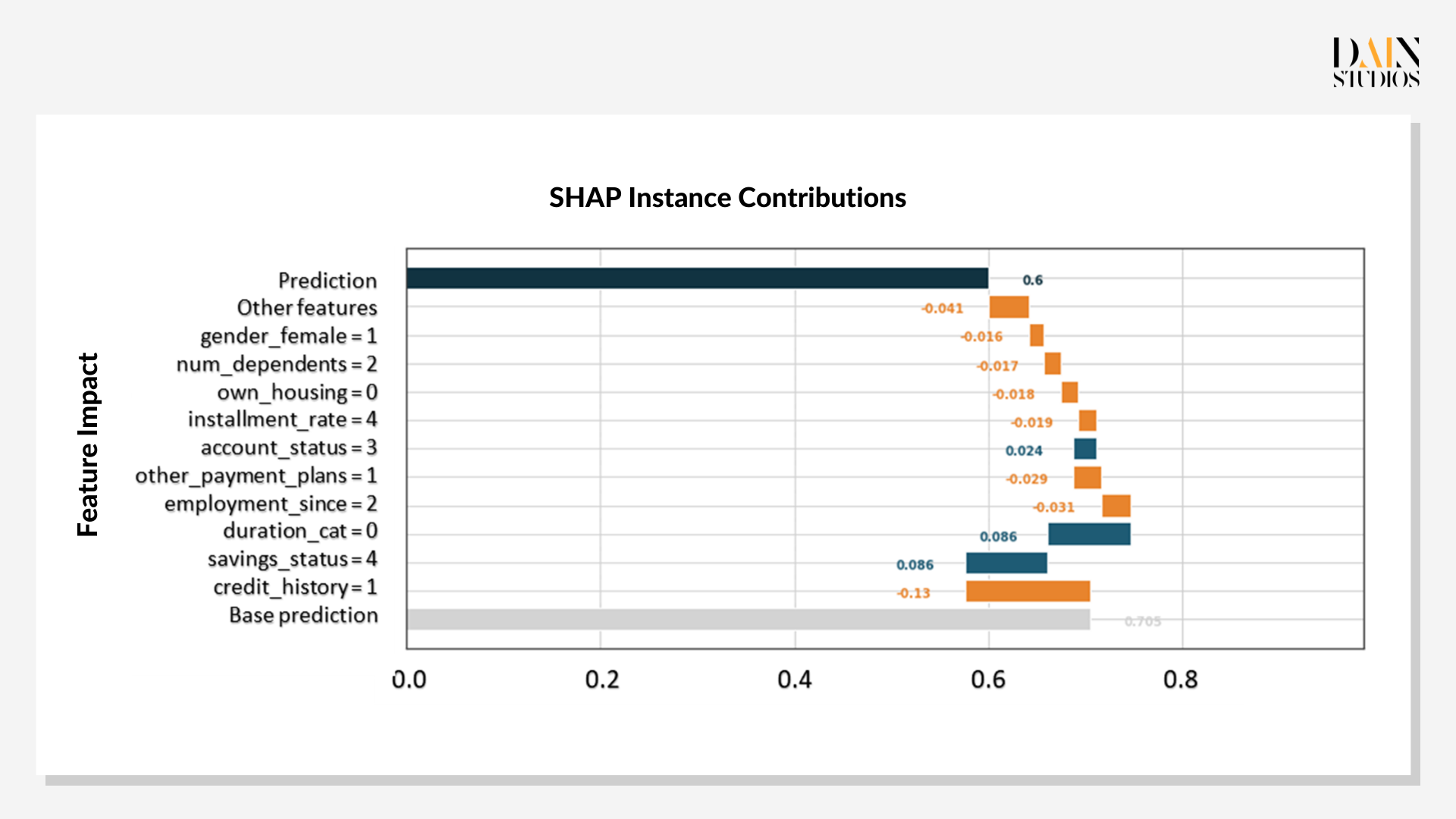
“Explainable AI” (XAI) in this case also allows the bank or the loan applicant to see how the ML model calculated this probability of loan repayment. Shapley values – named after the Nobel Prize-winning economist and game-theory pioneer Lloyd Shapely – show how each of the loan applicant’s characteristics contributed to the model’s final outcome. Each calculation begins by assigning the applicant a base prediction, the average prediction for the dataset. It then looks at a range of individual features that add to or take away from the initial probability score.
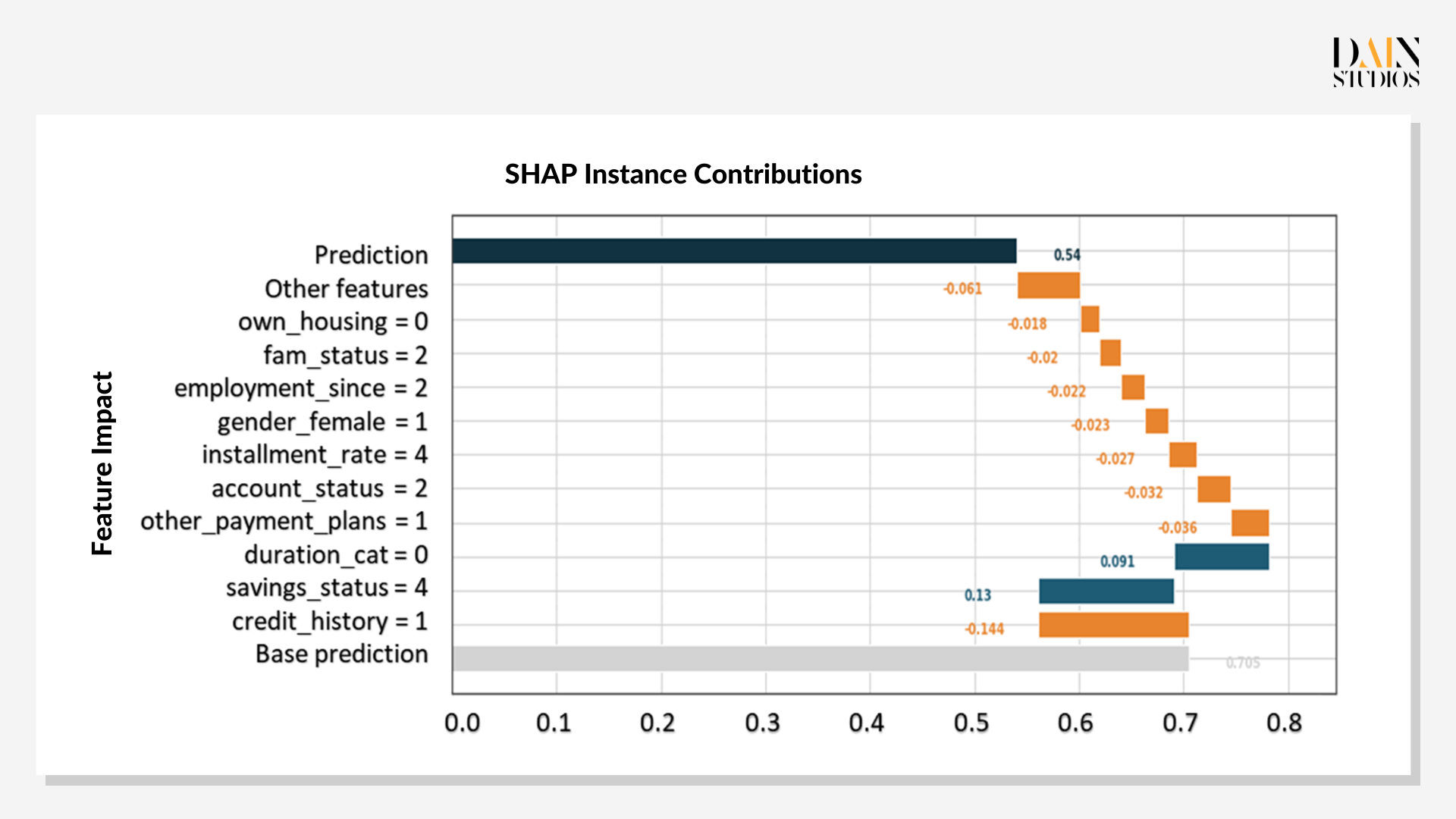
In the case of the loan application, the chart shows blue bars for features that improved her chance of getting a loan and orange bars for those that decreased her credit score, relative to the grey bar of the base prediction. It shows that the applicant’s credit history is the biggest factor that speaks against a loan, single-handedly reducing her score from the 0.7 base to 0.56. While her savings and the duration of the loan would more than counterbalance this first hit to her credit score, all the other features combine to bring the score down again, to 0.54.
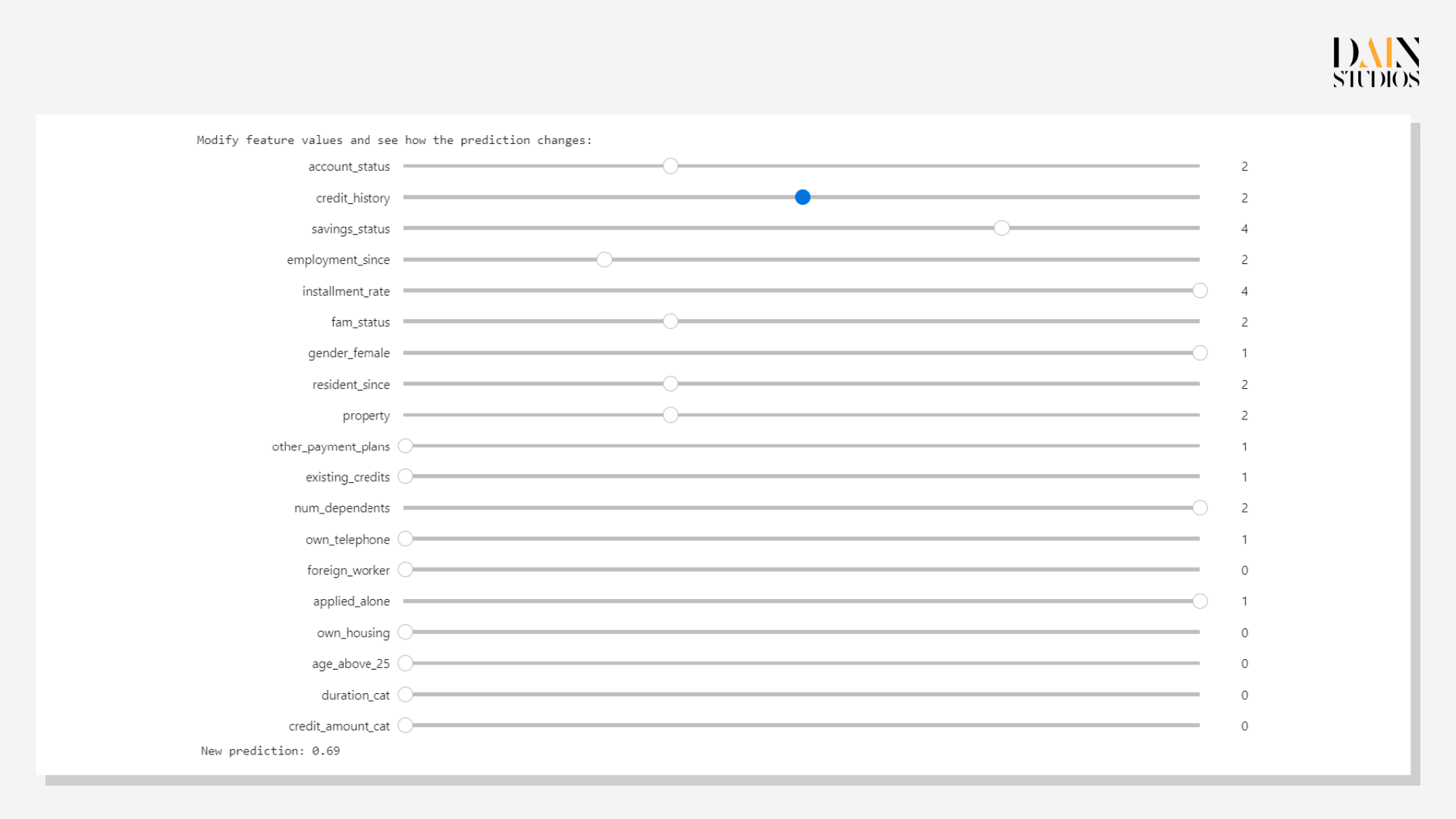
The applicant’s many negative Shapley values suggest the bank was justified in deciding against giving her a loan. But the model can also be used to help her in the form of a what-if analysis that shows how changes in her characteristics would change the prediction. Improving her credit history by one class increases the probability of her paying back the loan 0.69. She could also change other factors more readily – applying with a partner or parent (“applied alone=1”) or increasing her income (“account status” 3 instead of 2) would increase her chances to 0.6.
Rather than this approach of trial and error, it is often more efficient to ask what factors should best be changed to flip the model’s prediction or raise it to the desired level. In XAI, these are called counterfactual explanations, as they consider what would have been the result had facts been different. The most straightforward method is to look for prototypes, or other instances in the data that are similar to the case under examination, but different in outcome – the other exploits a genetic algorithm to generate data points and results based on that case.
Counterfactual explanations
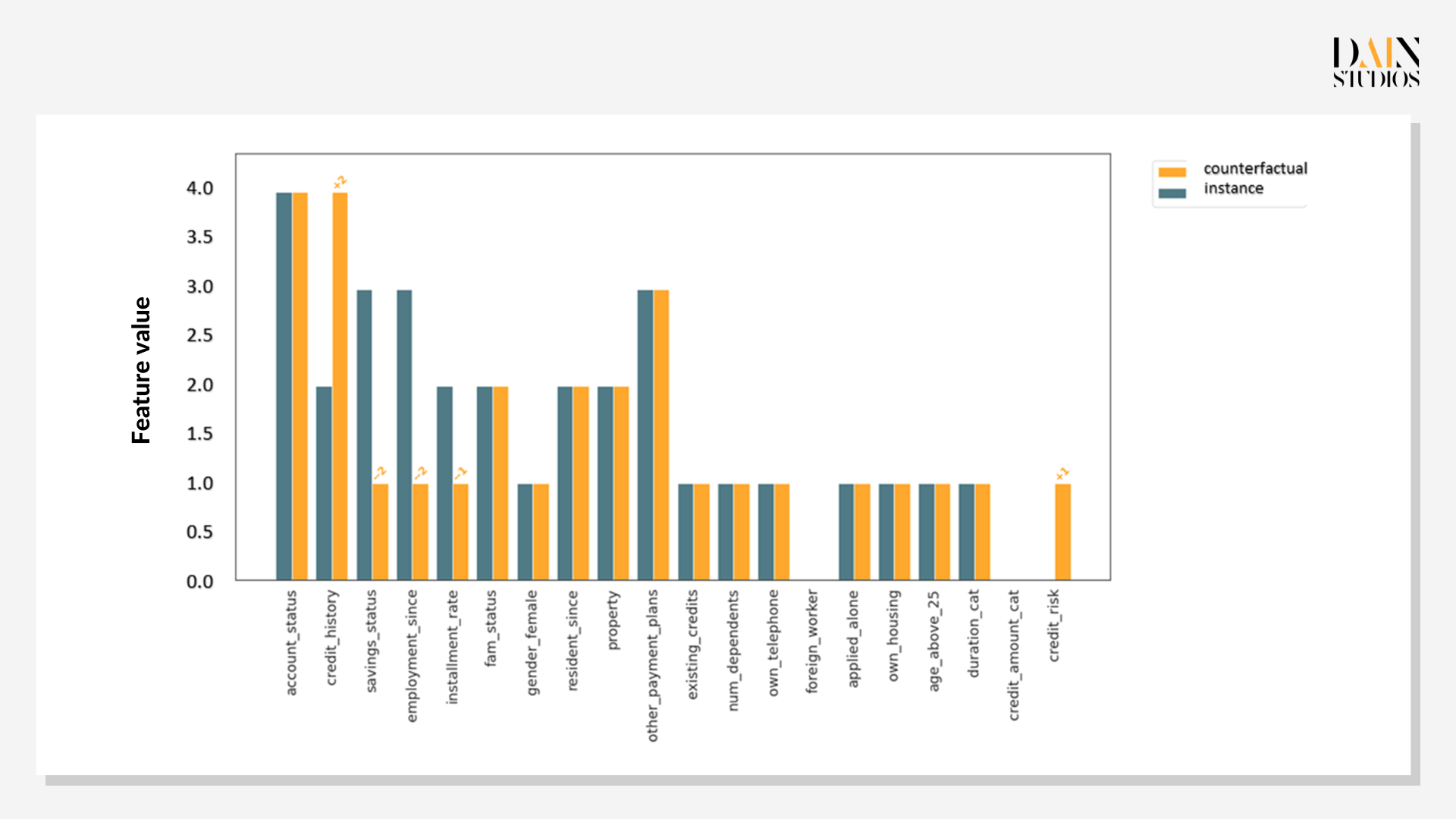
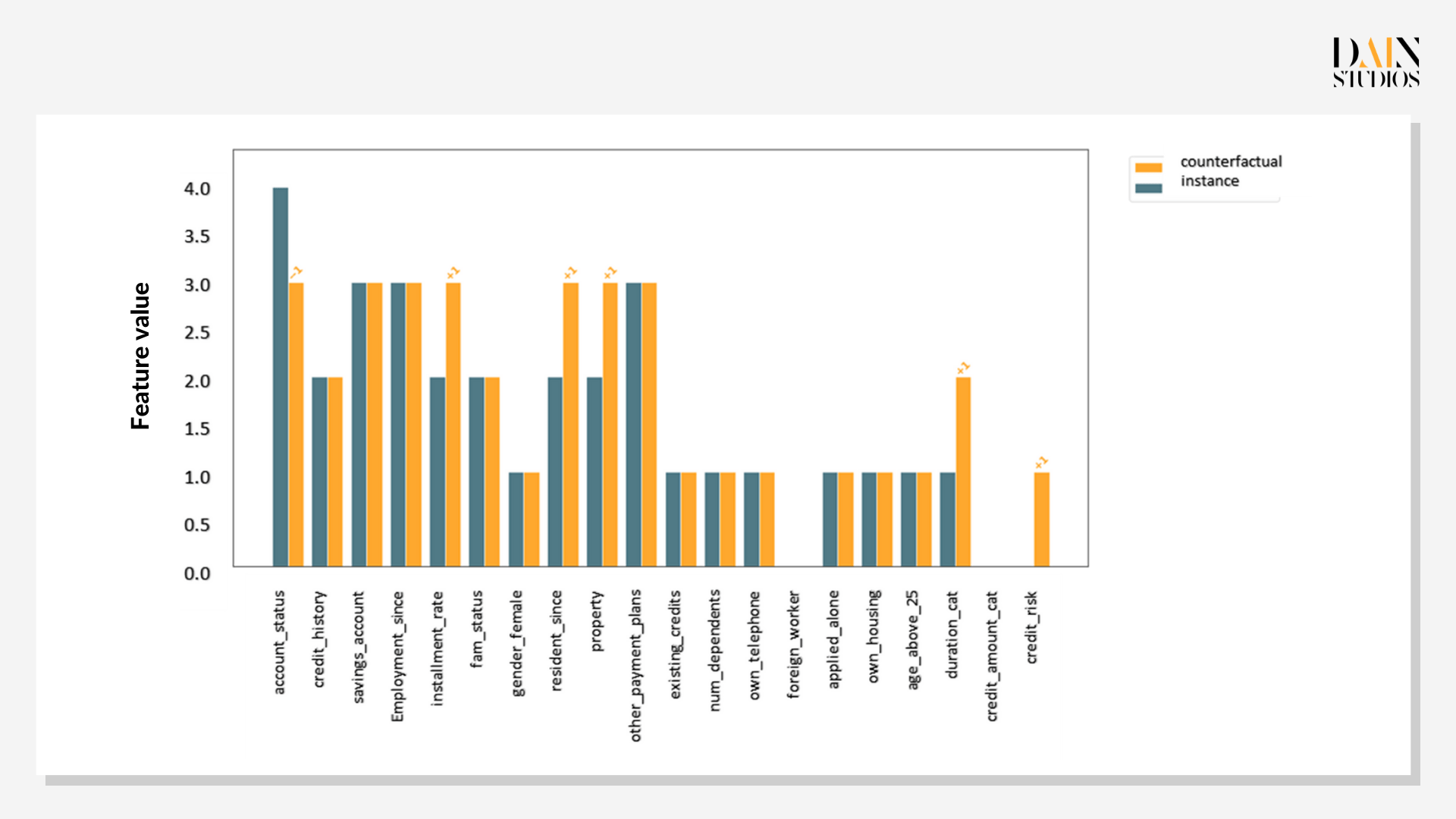
Prototype counterfactuals are useful when confronted by fairness issues. This applicant did not get a loan, but is there one with similar characteristics that did? If so, what features did the other person have that the first one didn’t? It turns out there are two instances in our dataset that have characteristics very similar to our loan applicant – except that loans were given in these cases. Comparing each to the case under examination offers insights on whether the decision-criteria make sense. The Shapley values show credit history is the single most important factor.
Genetic counterfactuals
If no prototype counterfactual can be found, XAI adopts the genetic approach. Using mutation, crossover and other methods known from biology, it generates synthetic data and calculates outcomes. It relies on simultaneous optimization of multiple functions, which place constraints on the outcomes resulting from predicting synthetic data. This ensures generated data are similar to the original instance, lie within its data distribution, differ in features as little as possible and produce a predicted value that is in a desired range close to the original value.
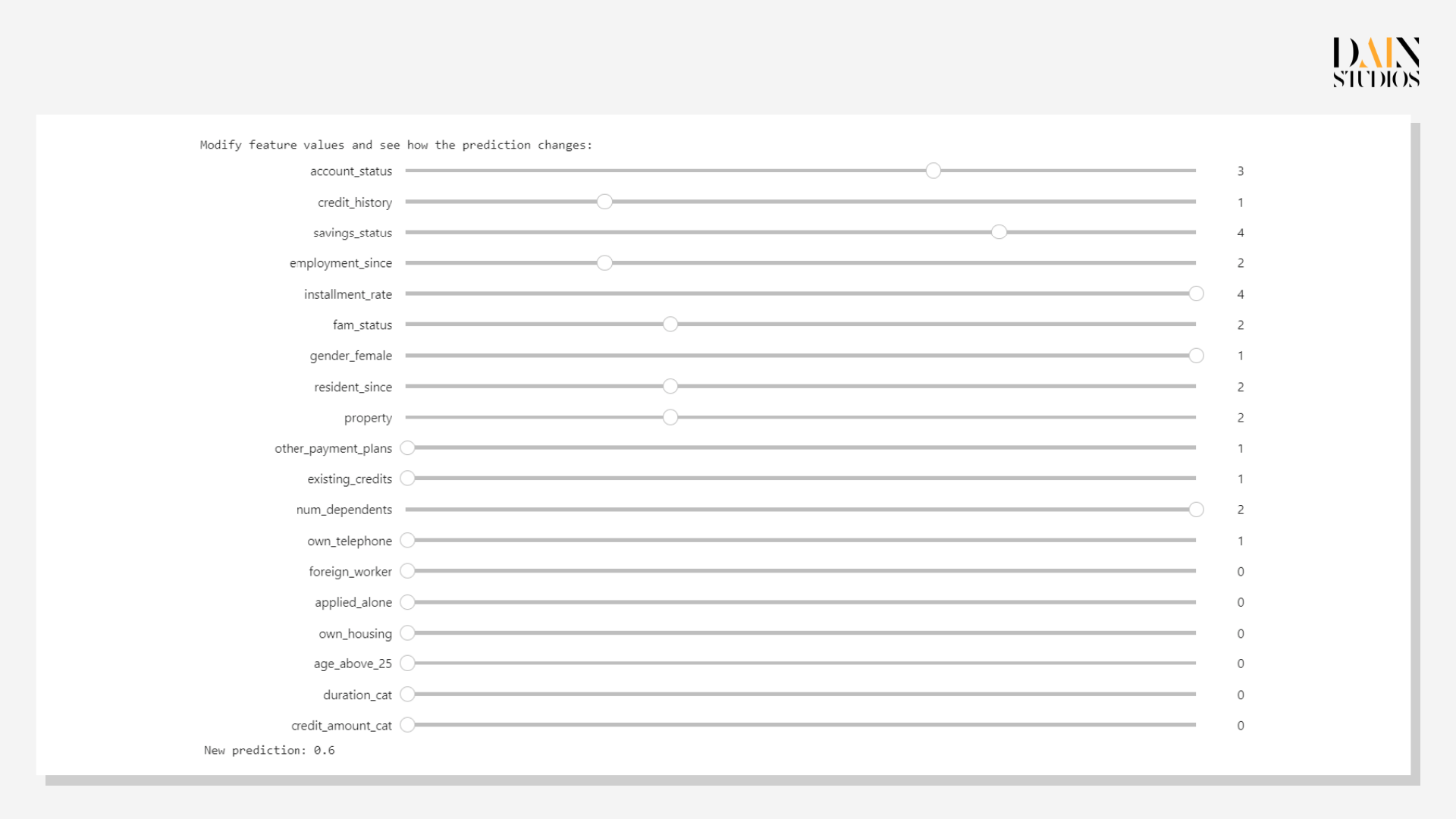
The first genetic counterfactual for the customer under examination shows that improving her credit history by one class would improve the probability of her getting a loan to 0.7. But, as has been shown previously, credit history is not all. The second counterfactual shows that more savings, being employed longer and providing for fewer people would increase her chances to 0.6. While credit histories change only slowly, the applicant could in the space of a year build up her savings and arrange to care for one less person, improving her chances for a loan.
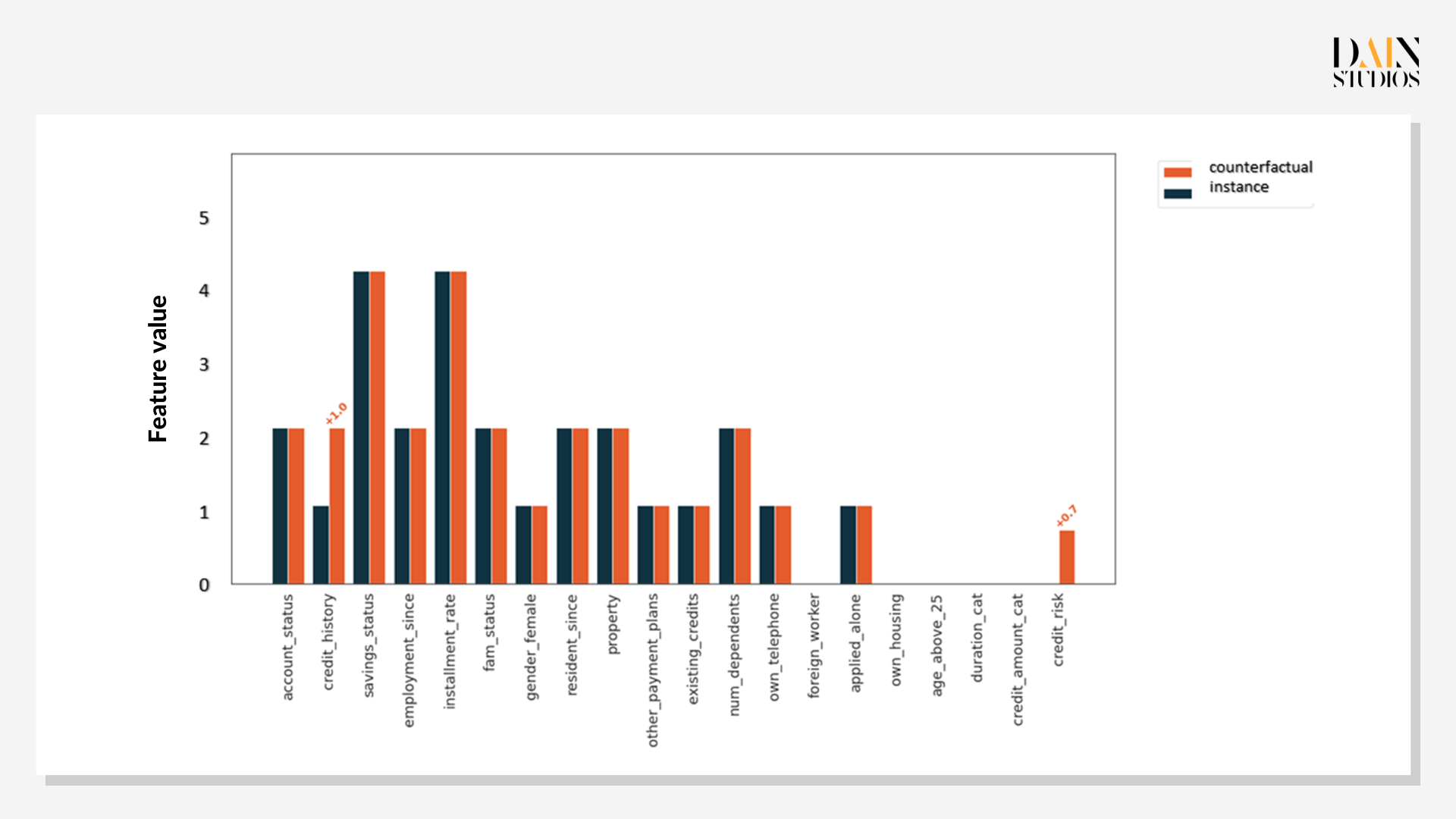

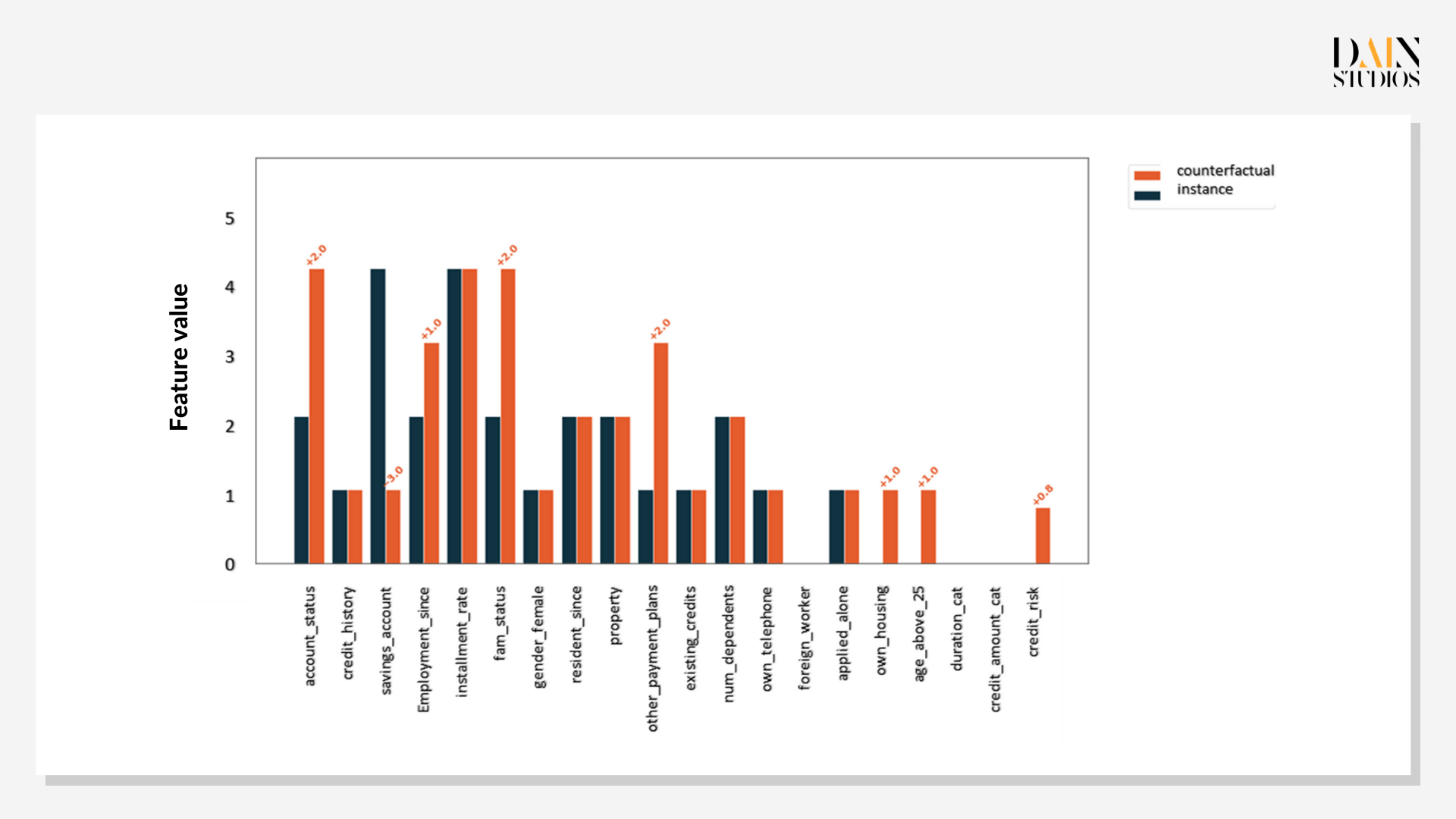
As not all paths are equally feasible, working with multiple genetic counterfactuals is useful. In this instance, the first example suggested an improvement in credit history, which can be done relatively easily (say, by reducing her debt) and would be enough to make her a stronger candidate. The latter two examples would require a lot more time and things to happen that aren’t wholly in anyone’s control, like starting a family. But they would still be invaluable for the bank to explain clearly to the loan applicant why it had decided not to give her any credit.
The ability to explain ML models benefits the people who use them and those the computer decides about. It allows businesses to better explain their decisions, improving communication with customers and avoiding lawsuits about choices that appear odd. People analyzed can improve their outcomes – even finding within the AI “black box” winning patterns and strategies in certain feature-combinations. Lastly, data scientists can test hypotheses and debug their models, ensuring that fairer and more accurate solutions enter commercial use in the first place.

{kind=link}
{kind=link}
{kind=link}
{kind=link}