
Let’s use stand-up comedy TV specials transcripts and NLP techniques to compare comedians. In this article, I will show that text analysis and visualization can be easy and fun and that with modern publicly available tools, everyone can do it, even without much programming experience.
To make this article a bit of fun, I chose open need open source data that is amusing to analyze. The idea of using stand-up comedy TV specials transcripts and NLP techniques to compare different comedians was inspired by this tutorial.
When this article was written (03/2020), the following stand-up comedy TV specials were among most popular in IMDB:
- Dave Chappelle: Sticks & Stones
- Hannah Gadsby: Nanette
- John Mulaney: New in Town
Preprocessing
I scrape the scripts for the above mentioned programs from Scraps From The Loft, a digital magazine featuring movie reviews, stand-up comedy transcripts, interviews, etc. making them available for non-profit and educational purposes. Using publicly available tools, I try to first understand stage personas, words that are most characteristic of each comedian, and differences in word usage between comedians.
In the preprocessing step, I delete text within brackets that indicates interruptions by the audience (e.g. ‘[audience laughs]’).
data_df['transcript'] = [re.sub(r'([\(\[]).*?([\)\]])','', str(x)) for x in data_df['transcript']]
!pip install scattertext
import scattertext as st
Visualizing corpora differences with Scattertext
To generate our first visualization, I follow the steps from the original tutorial.
# chose the comedians to compare
pair1 = 'Hannah Gadsby', 'John Mulaney'
df_pair1 = data_df[data_df['comedian'].isin(pair1)]
# parse speech text using spaCy
nlp = spacy.load('en')
df_pair1['parsed'] = df_pair1.transcript.apply(nlp)
# convert dataframe into Scattertext corpus
corpus_pair1 = st.CorpusFromParsedDocuments(df_pair1, category_col='comedian', parsed_col='parsed').build()
# visualize term associations
html = produce_scattertext_explorer(corpus_pair1,
category='Hannah Gadsby',
category_name='Hannah Gadsby',
not_category_name='John Mulaney',
width_in_pixels=1000,
minimum_term_frequency=5
)
file_name = 'terms_pair1.html'
open(file_name, 'wb').write(html.encode('utf-8'))
IPython.display.HTML(filename=file_name)
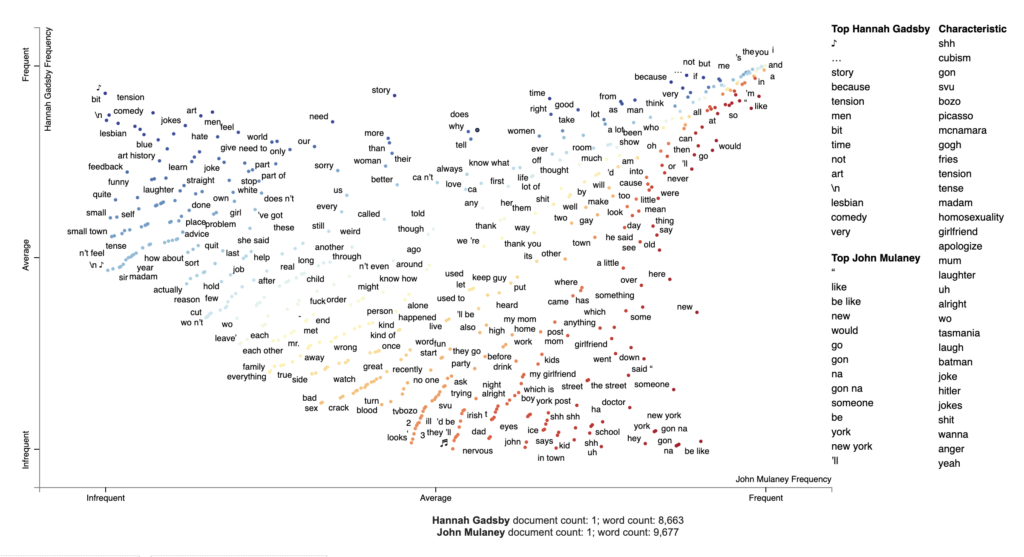


Visualizing topics using Empath
I use Chappelle’s transcript in the next example to visualize Empath topics. Empath (Fast et al., 2016) is a tool to analyze text across lexical categories (or topics) that can also generate new categories from text (e.g. “bleed” and “punch” terms generate the category violence). To visualize Empath topics with Scattertext, I install Empath, an open source Python library, and create a Corpus of extracted topics. I use the source code adjusting it for our data. The result is shown in the Figure 3.
!pip install empath
# chose the comedians to compare
pair2 = 'Dave Chappelle', 'Hannah Gadsby'
df_pair2 = data_df[data_df['comedian'].isin(pair2)]
# parse speech text using spaCy
nlp = spacy.load('en')
df_pair2['parsed'] = df_pair2.transcript.apply(nlp)
# create a corpus of extracted topics
feat_builder = st.FeatsFromOnlyEmpath()
empath_corpus_pair2 = st.CorpusFromParsedDocuments(df_pair2,
category_col='comedian',
feats_from_spacy_doc=feat_builder,
parsed_col='parsed').build()
# visualize Empath topics
html = produce_scattertext_explorer(empath_corpus_pair2,
category='Dave Chappelle',
category_name='Dave Chappelle',
not_category_name='Hannah Gadsby',
width_in_pixels=1000,
use_non_text_features=True,
use_full_doc=True, topic_model_term_lists=feat_builder.get_top_model_term_lists())
file_name = 'empath_pair2.html'
open(file_name, 'wb').write(html.encode('utf-8'))
IPython.display.HTML(filename=file_name)
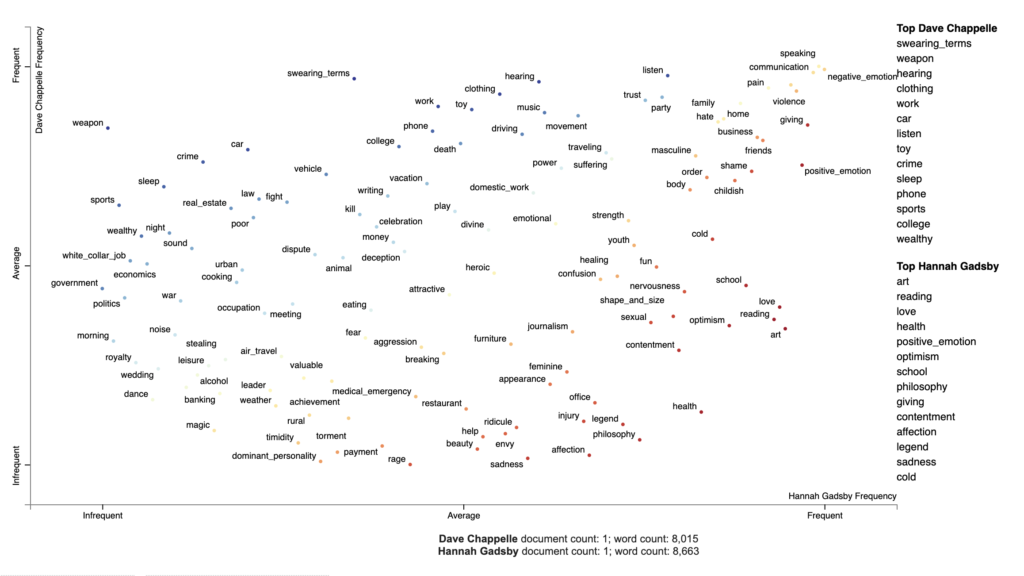
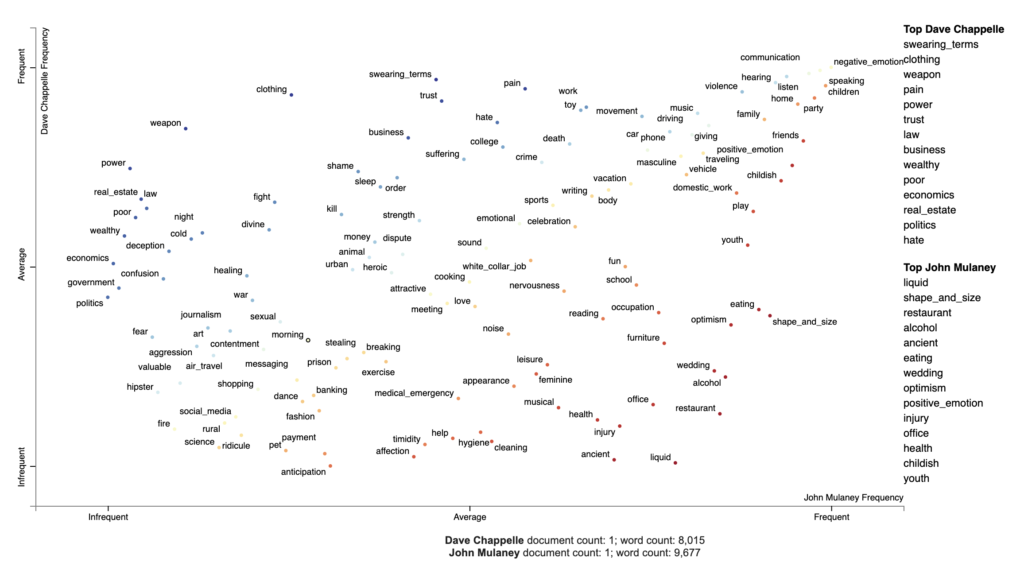
| Associated terms | Example | |
|---|---|---|
| Chappelle’s corpora | ‘mean’, ‘die’, ‘care’, ‘kill’, ‘bad’, ‘wrong’, f-ing, ‘worst’, ‘dead’, ‘beat’, ‘alone’, ‘hard’, ‘reason’, ‘guilty’, ‘crazy’, etc. | …If you’ve been poor, you know what that feels like. You ashamed all the time. Feels like it’s your fault… |
| Gatsby’s corpora | ‘reason’, ‘bad’, ‘wrong’, ‘disappointed’, ‘beaten’, ‘mean’, ‘stop’, f-ing, ‘hit’, ‘confused’, etc. | …And I am angry, and I believe I’ve got every right to be angry! But what I don’t have a right to do is to spread anger… |
| Mulaney’s corpora | ‘crazy’, ‘worth’, ‘terrible’, ‘wanted’, ‘lie’, ‘blame’, ‘killed’, ‘wanted’, ‘alone’, ‘lost’, ‘stupid’, ‘mean’, ‘bad’, ‘confused’, ‘fault’, ‘terrible’ etc. | …When people get mad at me now, it’s my fault, when people get mad at me on the highway that’s all my bad, I’m a terrible driver, I know nothing about cars. I meant to learn about cars, and then I forgot… |

Did this quick text visualization analysis help you decide which stand-up comedy TV specials to check out on Netflix tonight?
#gettingstartedwith is our new blog series for those of you that are eager to get acquainted with data and AI.
Curiosity is in our core, and many DAINians are constantly experimenting on things. We owe it to our customers to stay on top of new technologies, and to be honest, being a bit on the nerdy side, it comes quite naturally! Taking time to learn is also something we as employers want to encourage, and make sure some time is reserved each week for sharing knowledge with co-workers.
The blogs and posts we publish with the #gettingstartedwith tag will be more of an introductory level for those of you that want get familiar with the world of data and AI. It may be tips and tricks, showing how to build an API in 60 minutes, or a fun project on experimenting on text analysis for instance. Or we may be sharing links to good reading or watching, e-learning available or people to follow.