Why is this important?
In today’s data-driven world, algorithmic decision-making plays a critical role in many aspects of our lives, from credit scoring to hiring. However, with this increasing reliance on algorithms comes a growing concern about the lack of transparency in the decision-making processes. Transparent processes are critical to building trust and promoting fairness in algorithmic decision-making.
Providing understandable explanations of algorithmic decisions is essential, especially for decisions that impact individuals, such as customers or employees. The requirements to explain the decisions have already been outlined in the GDPR, but the requirements will become more relevant with the upcoming EU AI act. Decision-makers in organizations need to understand how algorithms arrive at their decisions, evaluate their accuracy, and identify potential biases or errors. This can increase the organization’s efficiency on all levels where algorithms are supporting the decision-making process.
Language models like ChatGPT can help bridge the gap between technical explanations and the general public. They can provide clear and concise explanations of how algorithms arrive at their decisions. Explainability algorithms like SHAP can also provide valuable insights, but the information they offer is often not easily understood by people who are not data scientists or have limited technical understanding.
By generating more accessible and understandable explanations of algorithmic decisions, organizations can build trust and confidence in their decision-making processes, which is particularly important when it comes to decisions that impact individuals. This can ultimately lead to better outcomes for individuals, organizations, and society as a whole.
The process for POC
We did a proof-of-concept experiment in an attempt to connect explainable AI techniques like SHAP values and counterfactuals to ChatGPT.
To generate the desired model explanations, ChatGPT needs to know something about the data. Specifically, it needs to know the meaning of the fields, their value range, and the implications of each categorical value feature :

After inputting the data, we can generate explanations. ChatGPT needs to know the specific data point to explain as well as the related SHAP values:
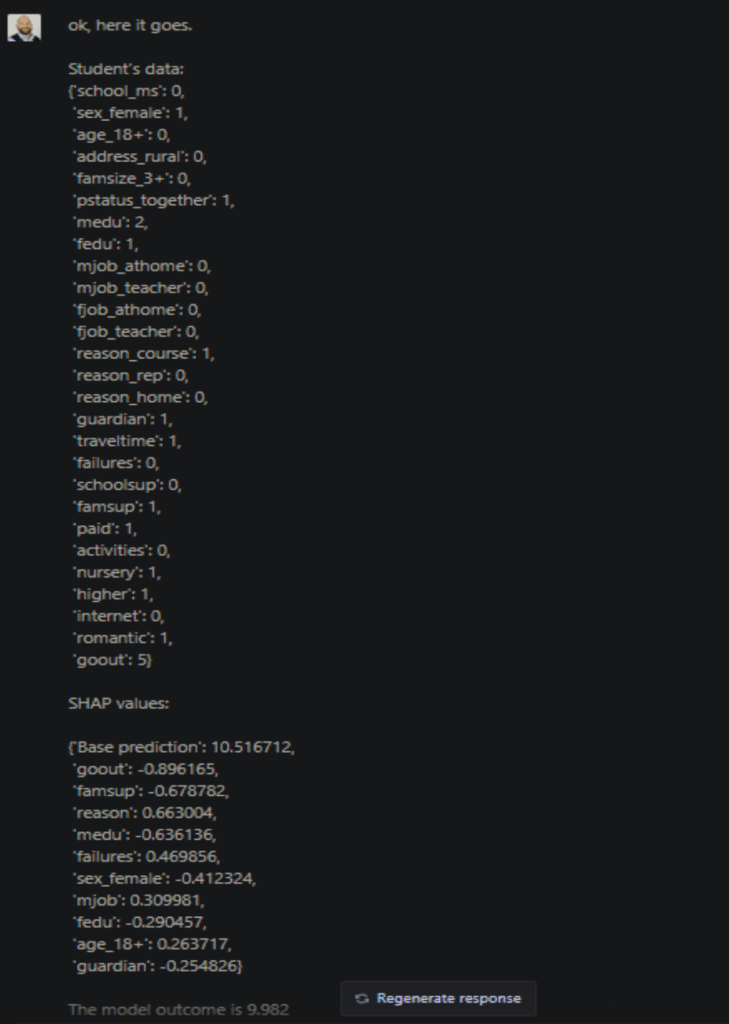
This would be the normal software output. It could be embedded in a dashboard to provide some visual support, but it still doesn’t help anybody without the technical knowledge to understand the reasoning behind the model outcome. The first explanation ChatGPT provides is still a bit technical:
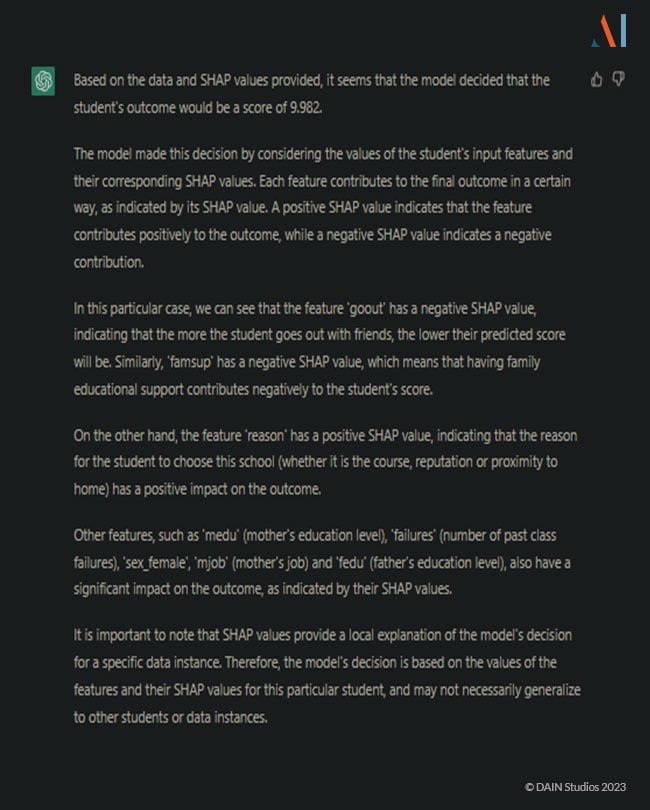
In order to obtain a simpler explanation, ChatGPT needs a specific request:
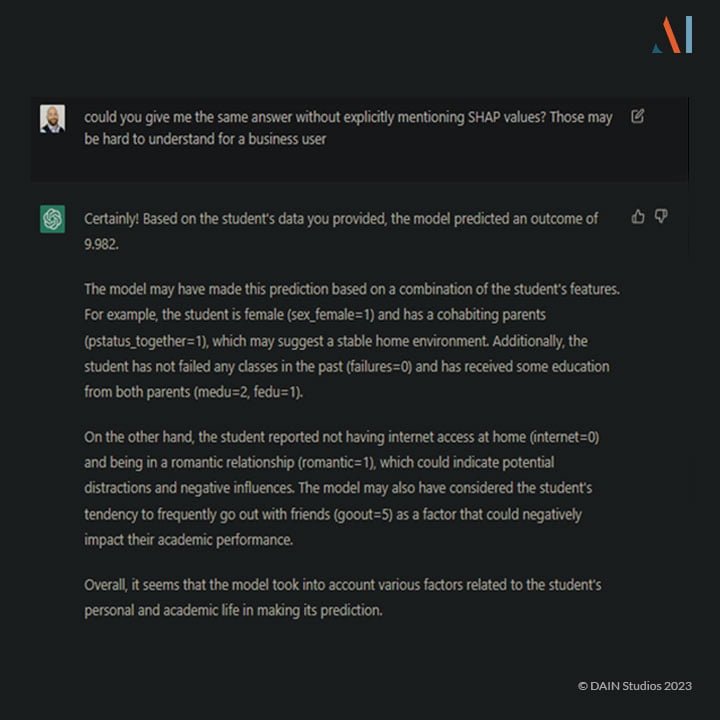
This explanation is a bit simpler and could arguably be understood by most people, regardless of their technical knowledge. However, if we need an even simpler explanation, we can request it:
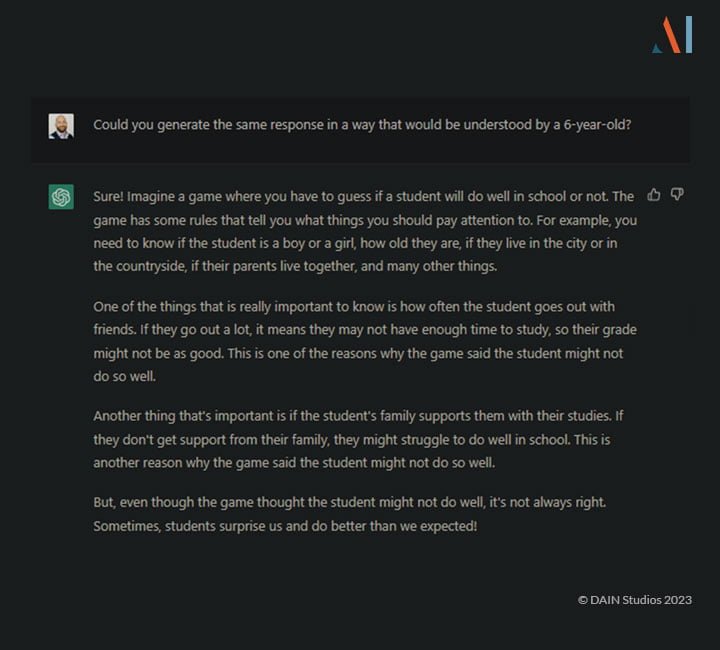
This explanation is simplistic, but it gets the point across without even using numbers.
Once we’ve received the explanation for the model’s decision, we may want to know how that decision could be reversed or improved. Suppose there was a model for granting or denying a loan or hiring somebody, it is legitimate to ask why and how the decision could be reversed. ChatGPT cannot give that explanation on its own without knowledge of the model:
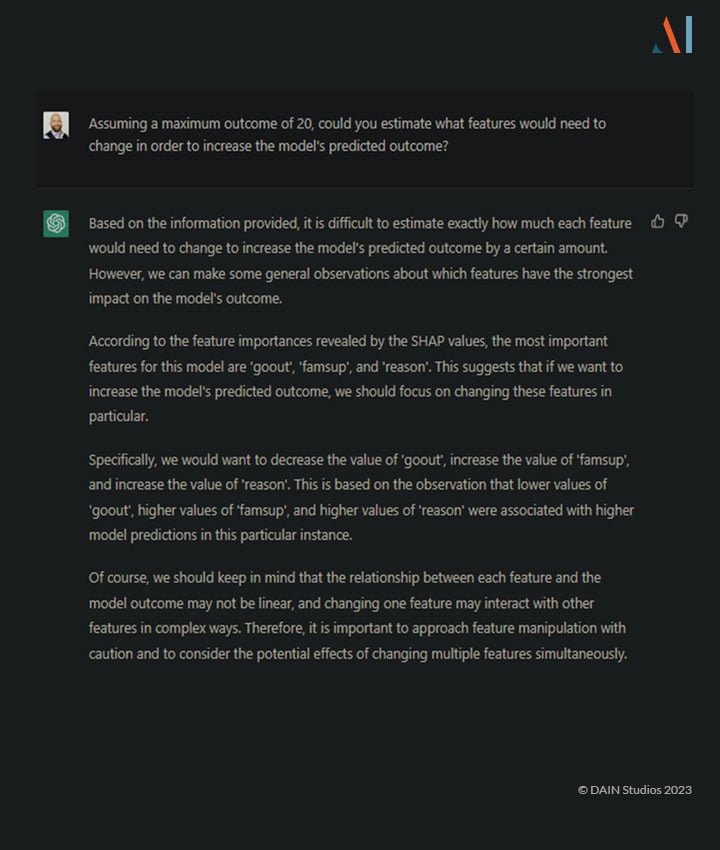
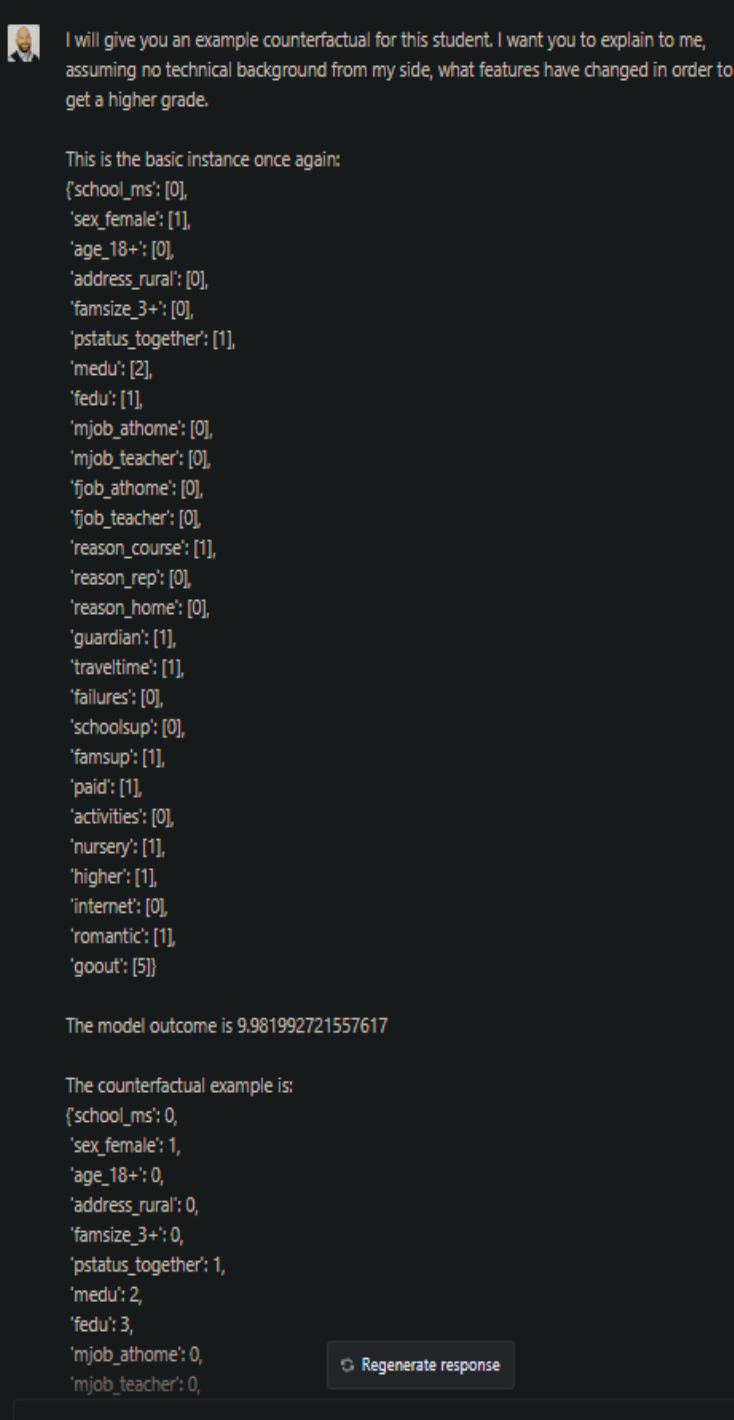
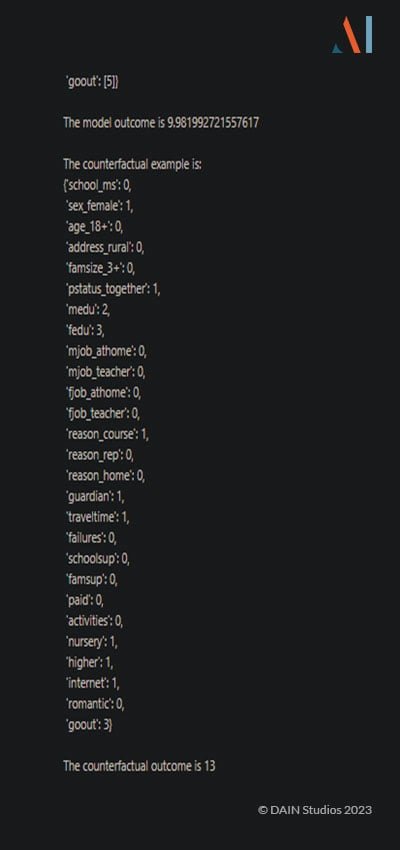
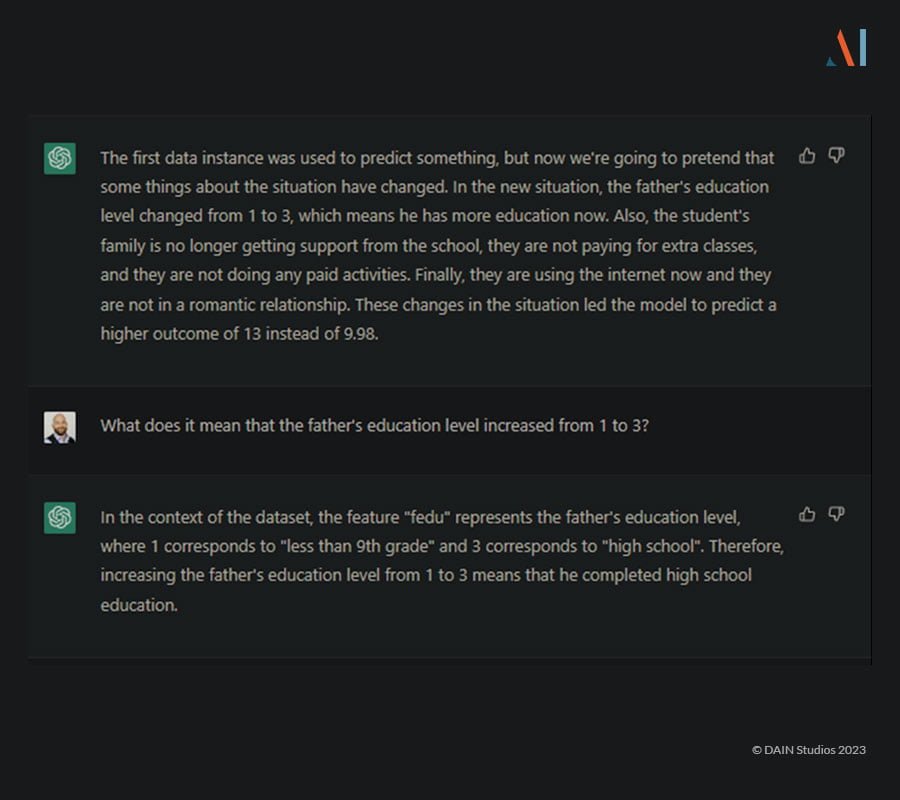
It does a reasonable job at guessing what might need to change but warns not to take these explanations at face-value and refrains from giving specific numbers. However, if given the data for a proper counterfactual from another piece of software, it can easily explain what changes would be needed for the desired outcome: (Click to zoom in.)
{kind=link}
{kind=link}
{kind=link}
These responses explain how the model’s decision can be changed in favor of the user. It is important to note though that producing these explanations requires ChatGPT to have detailed information about the data. If, for example, we don’t give any information in the data dictionary about the values of the categorical feature ‘fedu’, the following happens:
The resulting explanation of the counterfactual ends up being wrong: ChatGPT guesses rather than admitting it’s wrong.
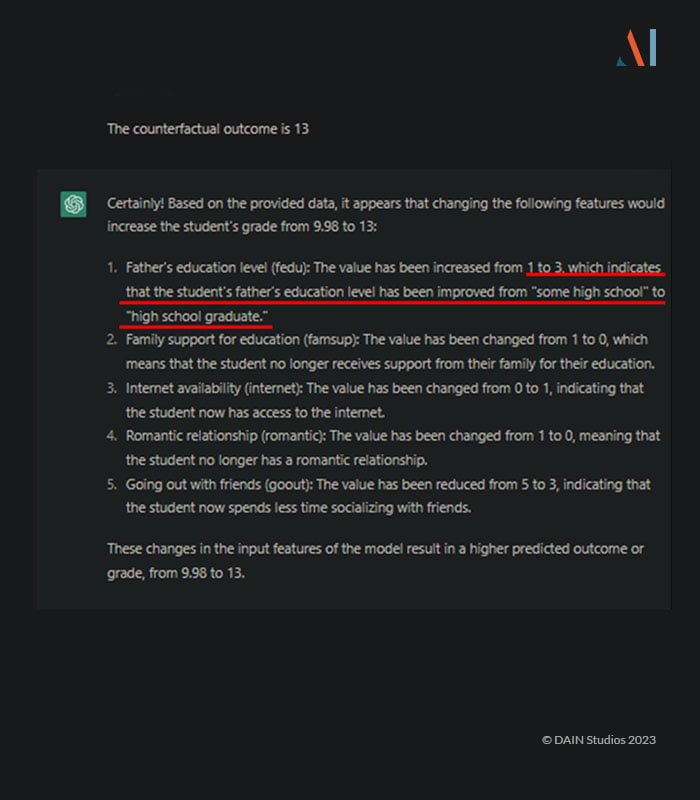
This is an incorrect guess and that it is a limit of the current ChatGPT model. To avoid these kinds of mistakes, the quality of the data dictionary is crucial.
In general, language models could be a powerful tool in explaining technical conclusions to people who want to understand how they can improve outcomes served by ML models but may not have the time or desire to learn a lot of technical jargon. The implementation is simple once the relevant (meta)data exists.
Limitations of the POC and other risks
While the explanations generated using ChatGPT were understandable and produced within seconds, it is worth mentioning that the data needed in order to get precise information was generated using a specific software suite. ChatGPT cannot explain a model without proper data or knowledge of how the model works. When asked to generate a counterfactual based on the SHAP values, it tried its best, while admitting its ignorance of the model and warning against
taking the tentative explanation too seriously as the conclusions that could be drawn from SHAP values would not extend to the general model.
When the metadata is not detailed enough, we showed previously that ChatGPT can guess at what the feature values mean. The error was caught thanks to specific domain knowledge, but if the ChatGPT explanation had been given to a student trying to improve their grade without any knowledge of the data, it would have made little sense or, worse, it may never have been understood as an error. In the case of a loan application or a hiring decision, that could have been a lawsuit waiting to happen.
In order to scale this proof-of-concept to a full application, software generating ML explanations would be needed, but, after that, a simple API call would be enough to generate explanations of automated models for the general public with minimal effort.
Future possibilities of using an API with ChatGPT or other language models
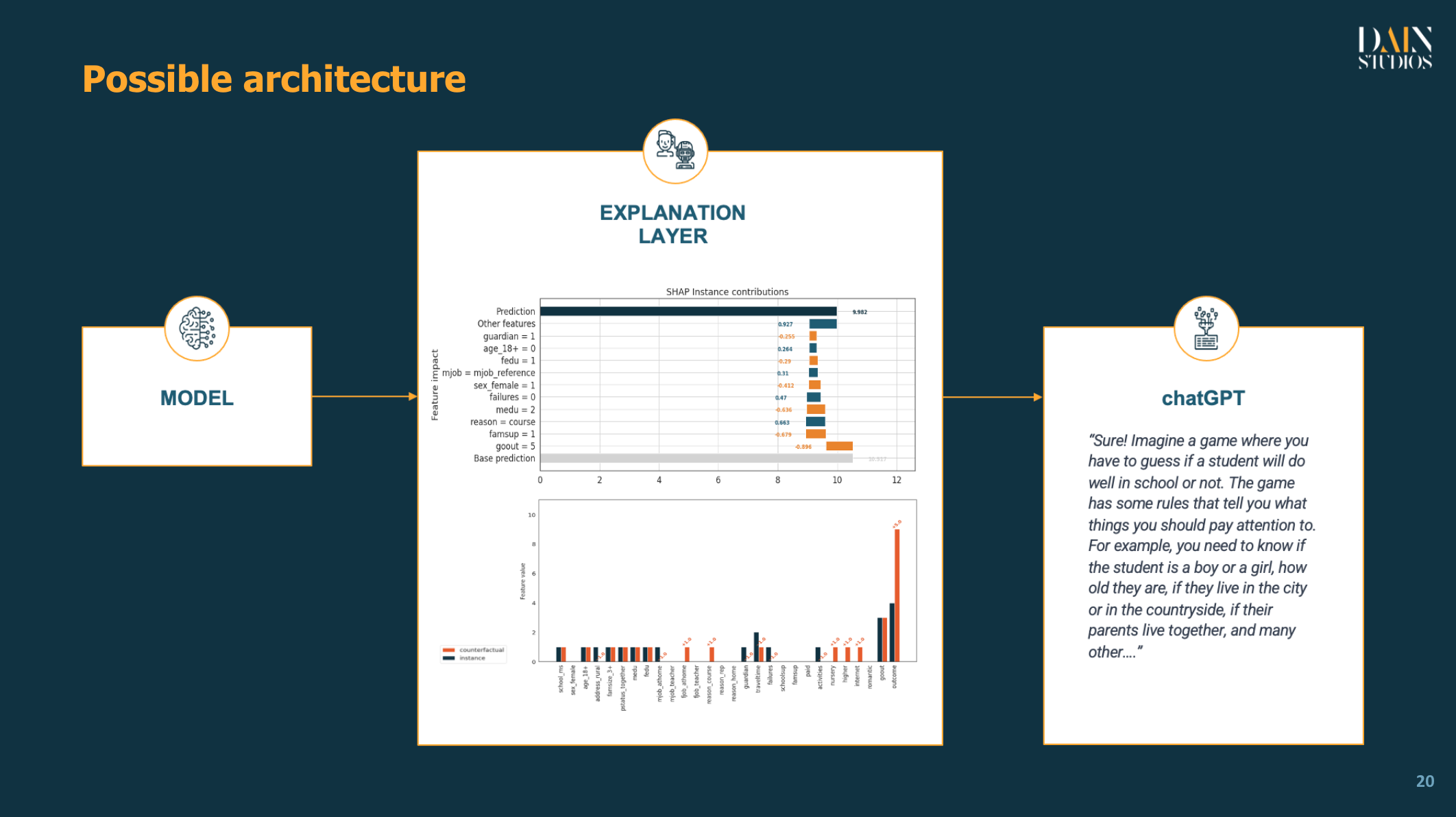
As we adopt ChatGPT in the industry, the use demonstrated so far could simplify ML explanations to any type of user. In terms of system architecture, once the appropriate software generates the relevant explanations, we can connect to any large language model via an API and scale the ML explanations for the general public.
As highlighted in the proof-of-concept, it’s important to take the effort to generate a precise data dictionary, listing the meaning of all features and their values (if categorical) or distributions (if numeric).
Thorough testing should happen before deployment, ensuring the language model has all the necessary information to describe the data used in the model and return sensible explanations. Also, as with any IT solution, there should be constant monitoring in place to ensure the quality of the responses remains at a level that avoids complaints from the public.
Conclusion
Software-generated explanations for a machine learning model were passed to ChatGPT in order to simplify the information for non-technical users. ChatGPT can do this rather well, once we provide a detailed description of the data.
When the data dictionary contained missing information, ChatGPT tried to guess the meaning of the values for the unclear features. Guessing is a risk as it may lead to false explanations that may go unnoticed by people without domain knowledge.
As transparency requirements demand more and more of the decision-making process (more so for automated decisions), language models could be a valuable asset in scaling machine learning explainability to wider audiences without requiring them to learn specific technical concepts commonly used by data scientists.
In general, we can use a language model to improve communication between technical and business people as well as between businesses and customers. Language models can simplify concepts that would otherwise be hard to communicate to people who have no time, need, or desire to get specific technical knowledge.