Many companies want to embrace digital transformation and use Artificial Intelligence (AI). They have the ideas, resources, and a vision, but the foundations are missing. That is, a deep knowledge of their data, from how they use and define terminologies, to how they store, use and archive data. Most AI and data analytics use cases will require connecting multiple and different data sources and types to gain deep insights and business optimisation outcomes. However, a lack of knowledge and narrow vision of the data ecosystem can be a threat to the success of these projects.
This post aims to give an overview of the Principles of the Data Audit which will be the first milestone for sustainable Data Management.
Principles
The Data Audit is composed of 3 main iterative steps: the data asset identification, the measurement/evaluation of the data quality and the enrichment of the data through better quality processes.
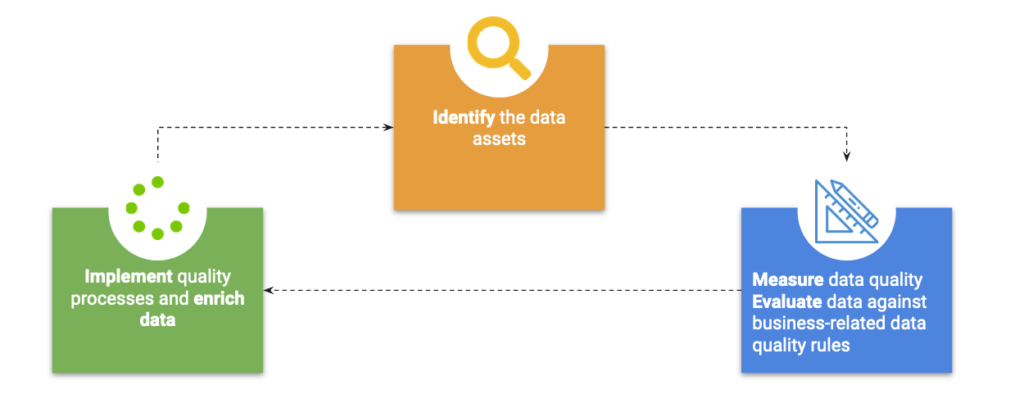
Identify the data assets
First things first, get familiar with the data ecosystem. There are data and it can be described in many different ways. The characteristics of the data asset need prudence in definition to be fully understood. It is important to ask questions such as:
How to identify a data asset? What is the right level of detail?
To identify a data asset in the most efficient way, it is necessary to know its life cycle.
First, let’s define a data asset.
Any entity that is comprised of data. A data asset may be a system or application output file, database, document, or Web page, also a service that may be provided to access data from an application.
National Institute of Standards and Technology – U.S. Department of Commerce
Every data asset has a life cycle: planning, obtainment, storage and sharing, maintenance, use, and disposal. Let’s explore these details further in the phases:
- Planning: Identify objectives, plan information architecture, develop standards and definitions;
- Obtainment: Ways to acquire data. For example, by creating records, purchasing data, or loading external files;
- Storage and Sharing: Form of storing and sharing data. Data may be stored electronically such as in databases or files. Data can be shared through such means as networks, emails or APIs;
- Maintenance: Update, change, and manipulate data. Cleanse, wrangle and transform data. Match and merge records, or optimize data;
- Use: Retrieve data. Use information. Use can be completing a transaction, writing a report, making a management decision from a report, and/or running automated processes;
- Disposal: Archive information or deleting data or records;
For each phase, four aspects have to be taken in account:
- the What: what data is concerned during these phases?.
- the How – Processes: how are these phases executed from a procedural point of view?
- the Who: who is involved in these phases?
- the How – Technology: how are these phases executed from a technological point of view?
This framework gives a holistic view of the analyzed data assets: it will be the pedestal for improving the data asset, imagining new use cases and making data governance implementable.
Measure and Evaluate Data Quality
Now that the data asset can be identified, the next step is to determine if the data is usable? Not all data is useable or relevant to the AI and analytics use cases, and therefore it is important and necessary to assess data quality. To do this, we ask the following questions:
What makes data quality? Is it necessary to have an impeccable data asset?
Data quality relies on metrics that will be confined to business rules. These metrics will be the same for all data assets but it will not be the case for the business rules. The comparison of the two will give the validation of the data quality.
Data Quality Metrics
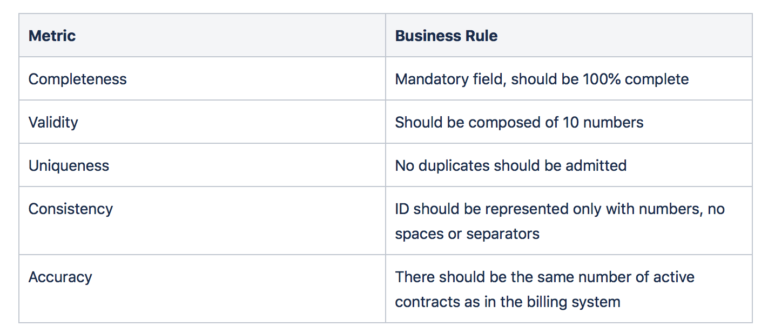
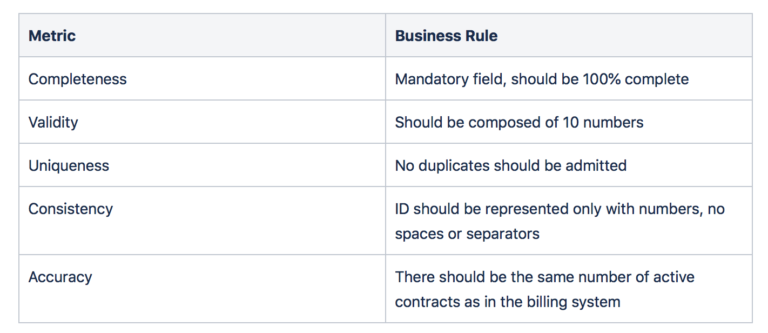
Data quality can be measured with 6 main metrics:
- Timeliness: Describe the latency between the event and the availability of the information – e.g. the contracts data set is refreshed once per year;
- Completeness: Percentage of values that are considered as complete – e.g. only 80% of the timestamps are complete;
- Validity: Respect of a certain syntax, range or set of rules – e.g. age has to be between 18 and 110 for some cases;
- Uniqueness: Presence of duplicates or missing values – e.g. if a business serves 100 clients, there shouldn’t be more than 100 in the data set;
- Consistency: Consistency in the way to represent data – e.g. dates are always encoded in the same way;
- Accuracy: Exactitude of the data in comparison with the reality – e.g. the billing system should be the same, and consistent with, the financial data sets.
At the exception of timeliness, all the other metrics are measured at the level of fields.
Business Rules
It’s good to be able to quantify the data quality but the final goal is to qualify data reliability. Indeed, not all the fields of a data set have the same importance: inaccuracy, incompleteness, and non-validity can be accepted for some of them.
To qualify this data reliability, one first step is to define business-related data quality rules. These rules are defined by the owner of the data asset and they represent the standard from which data can be qualified as reliable. Each metric we’ve seen previously should have its own business rule but it can happen in cases where there is none.
For example, in a telecom company, there is a data set containing all the mobile customer contracts. Some of the fields are contract ID and email address. Let’s elaborate the business rules for both of them.
Timeliness is the same for the whole data set – it should be refreshed daily.
Contract ID:
Email Address:
The key idea here is that not all the fields have the same value. For those which are central in the core business, the business rules should be strict and carefully defined. However, for secondary fields, it may not be worth spending too much time on the determination of rules.
Data Quality Evaluation
The goal here is to compare the metrics measured and the defined business rules. If all the metrics respect the rules then the field is validated.
In the best case of fields being evaluated, all fields will be validated and therefore the entire data asset is validated too. In the worst but simple case, all fields are wrong and the entire data asset will need correction.
The reality usually presents a mix of both valid and invalid fields in the data quality evaluation with some fields being compliant, and others not. In that case, the mandatory fields should be defined and their compliance required for validating the data asset. This validation should, however, go with some indication about how the problematic fields could affect (or not) the current or future business use cases.
Implement quality processes and enrich data
After the data quality evaluation, the issues are underlined and have to be resolved. The best way to solve these issues is to find the root causes.
Fortunately, the data life cycles of problematic data assets are known. Therefore, it is possible to locate the stage where the problem appears, its technical and/or business reason, and the people to talk with to fix it.
To conclude, a Data Audit is divided into three phases. The first is the identification of the data asset and the investigation on its life cycle. The second is the evaluation of the data quality. For this, it is necessary to measure the 6 main metrics and compare them to the defined business rules. The output of these two phases is a clear view of any problematic data. The third and last phase consists of treating the root causes of these issues. Using the data life cycle enables us to find why and where there is a problem and with whom to interact with for a sustainable data management solution.