Im dritten von vier Artikeln zum Thema Fairness und erklärbare KI beschreibt Sinem Ünal einige Methoden, mit denen Unternehmen die Verzerrung in den ML-Modellen reduzieren können.
Anwendungen von KI und maschinellem Lernen (ML) sind in unserem Leben immer sichtbarer geworden. Ein wesentlicher Bestandteil dieses Anstiegs der Popularität ist ihre Fähigkeit, erstaunlich genaue Ergebnisse mit hoher Leistung zu erzielen. Eine wichtige Frage bleibt jedoch, ob ML-Systeme fair oder voreingenommen sind, insbesondere weil Entscheidungen, die auf ihnen basieren, schwerwiegende Auswirkungen auf den Einzelnen haben könnten, sei es im Recruiting, im Bankwesen oder im Gesundheitswesen. Jeder kennt das bange Warten auf eine Entscheidung über einen Job oder einen Kreditantrag. ML-Systeme sollten diese Prozesse nicht wesentlich erschweren, indem sie sie verzerrt machen.
Im ersten Artikel dieser Serie ging es um die Frage der Fairness und die Diskussion darüber, wie Unternehmen sicherstellen können, dass ihre automatisierte Entscheidungsfindung fair ist. Natürlich kann Fairness auf viele Arten definiert werden und daher müssen Unternehmen ihre Definition sorgfältig und objektiv wählen. Sobald diese Entscheidung getroffen ist, kann das Data Science-Team wieder ins Spiel einsteigen, um seine Modelle anhand dieses Playbooks zu erstellen und zu testen.
Nehmen wir nun an, dass Sie als Data Scientist diese Verfahren befolgt und festgestellt haben, dass Sie ein verzerrtes Modell zur Hand haben. Was haben Sie dann? Glücklicherweise gibt es mehrere Methoden, um algorithmische Verzerrungen zu reduzieren, und dieser Blogpost wird auf diese eingehen. Diese Techniken können in drei Kategorien eingeteilt werden, je nachdem, in welcher Phase sie angewendet werden: Vorverarbeitung, In-Verarbeitung und Nachbearbeitung. Kurz gesagt, Vorverarbeitungstechniken werden auf die Daten selbst angewendet, während In-Processing-Techniken das Modell modifizieren. Nachbearbeitungstechniken hingegen konzentrieren sich auf die Ausgabe des ML-Modells.
Mit Werkzeugen, die von DAIN Studioswird die Anwendung von Techniken zur Minderung von Verzerrungen und deren Implikationen anhand des Deutschen Kreditdatensatzes demonstriert.
Entscheidung über Darlehensanträge als Beispiel
Der Datensatz besteht aus tausend Stichproben von Bankkontoinhabern, die Informationen über ihre Kontodaten, ihren finanziellen Status und persönliche Informationen wie Alter und Geschlecht enthalten. Dazu gehört auch, ob die Person Anspruch auf einen Kredit hat oder nicht. Ein maschinelles Lernmodell wird angewendet, um vorherzusagen, ob eine bestimmte Person Anspruch auf eine Gutschrift hat. Gleichzeitig wird die Fairness des Modells überprüft, d.h. ob sie Frauen und Männer gleich behandelt. Für dieses Problem wird die statistische Parität als Fairness-Metrik ausgewählt. Er misst, ob die geschützten (weiblichen) und ungeschützten Gruppen (männlich) die gleichen Chancen auf ein positives Ergebnis haben, in diesem Fall auf einen Kredit. Das Verhältnis richtiger Entscheidungen zu allen Entscheidungen wurde ebenfalls protokolliert, um die Genauigkeit des Modells zu verfolgen.
Das Modell wird auf die Kredit-Score-Daten angewendet und führt zu den folgenden Messungen:
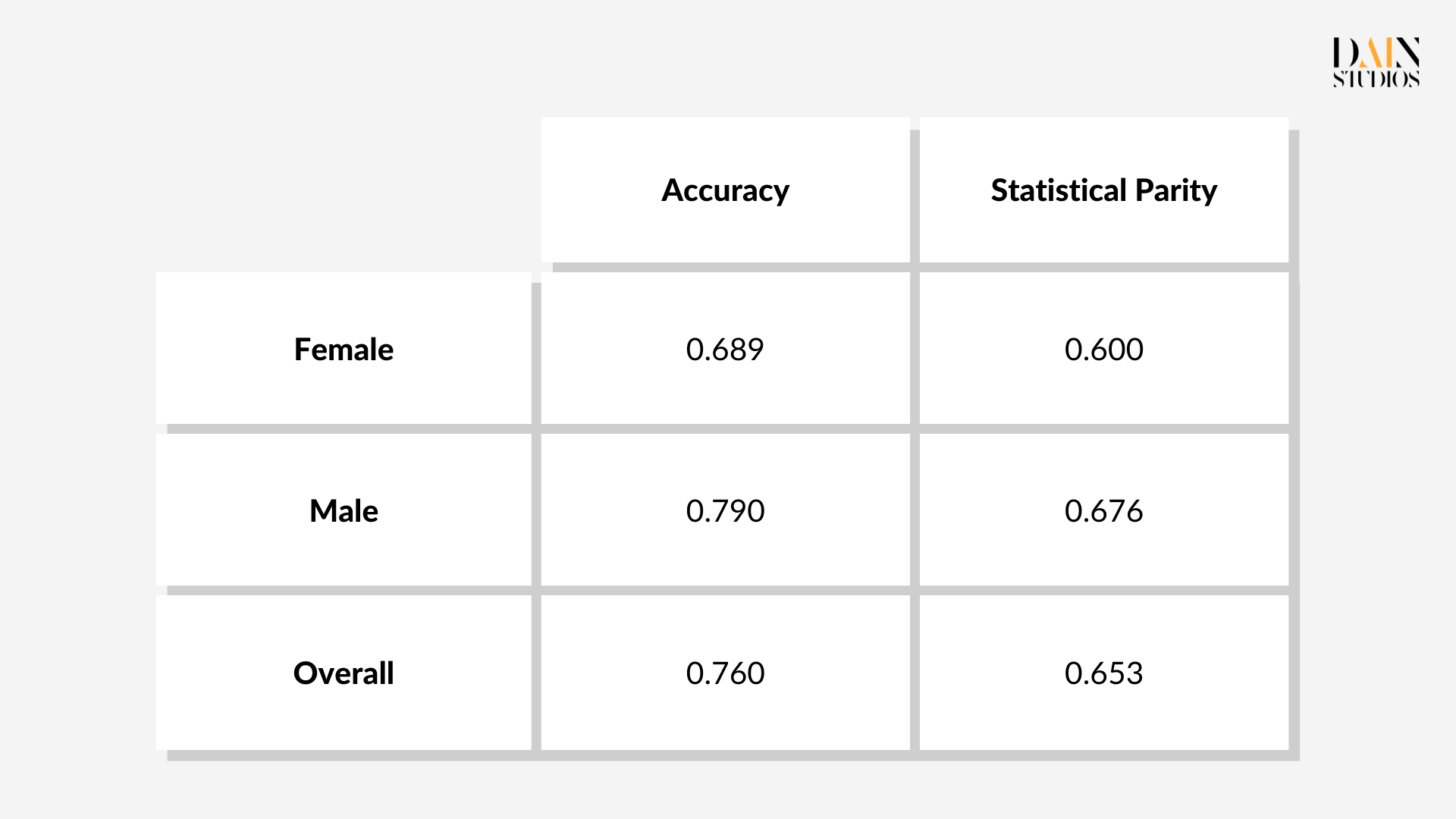
Nach der Fairness-Metrik Statistical Parity (STP) erhalten 68 % der Männer im Datensatz einen Kredit, während nur 60 % der Frauen einen erfolgreichen Antrag stellen. Diese Differenz von 8 Prozentpunkten deutet darauf hin, dass das ML-Modell unter dem Gesichtspunkt der Fairness verbessert werden kann und dass Techniken zur "Minderung von Ungerechtigkeiten" angewendet werden können, um die Differenz zu verringern. Wie bereits oben erwähnt, gibt es drei Möglichkeiten, vorzugehen: Ändern Sie die Art und Weise, wie der zugrunde liegende Datensatz zum Trainieren des Modells verwendet wird, überarbeiten Sie den Algorithmus des ML-Modells oder ändern Sie die Schwellenwerte, die positive von negativen Entscheidungen unterscheiden.
Techniken zur Reduzierung von Verzerrungen: Vorverarbeitung
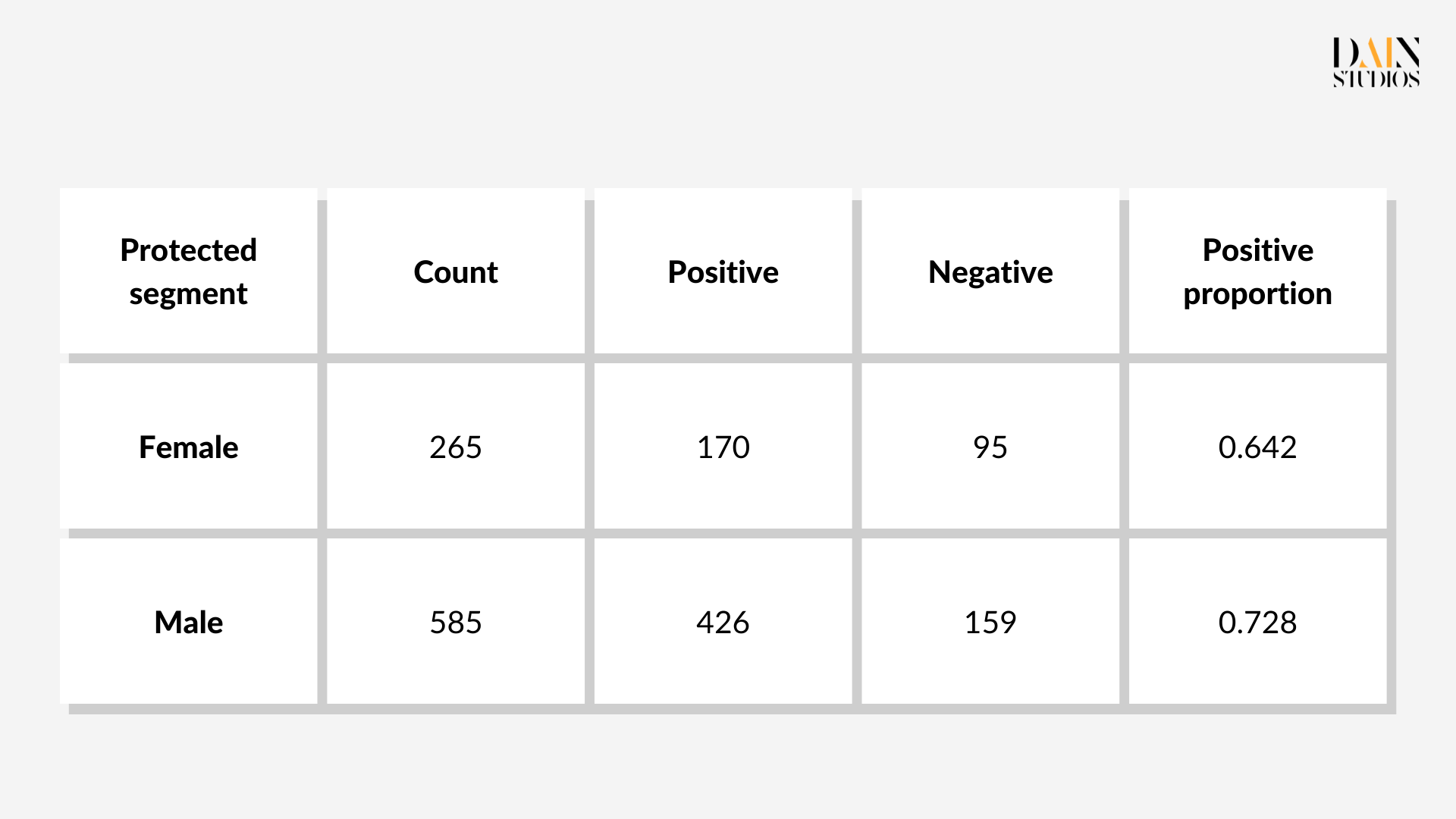
Es gibt mehrere Vorverarbeitungstechniken, die auf die Trainingsdaten angewendet werden können. Hier kommt das "Resampling" der Trainingsdaten des ML-Modells zum Einsatz. Datensegmente werden unter- oder übersampelt, um Verzerrungen auszugleichen. Im German Credit Dataset sind beispielsweise 64 % der Frauen und 73 % der Männer (die sogenannten geschützten bzw. ungeschützten Gruppen) tatsächlich kreditberechtigt. Was das Modell aus dieser Rohstichprobe lernen wird, ist, dass Männer eher für Kredite in Frage kommen als Frauen.
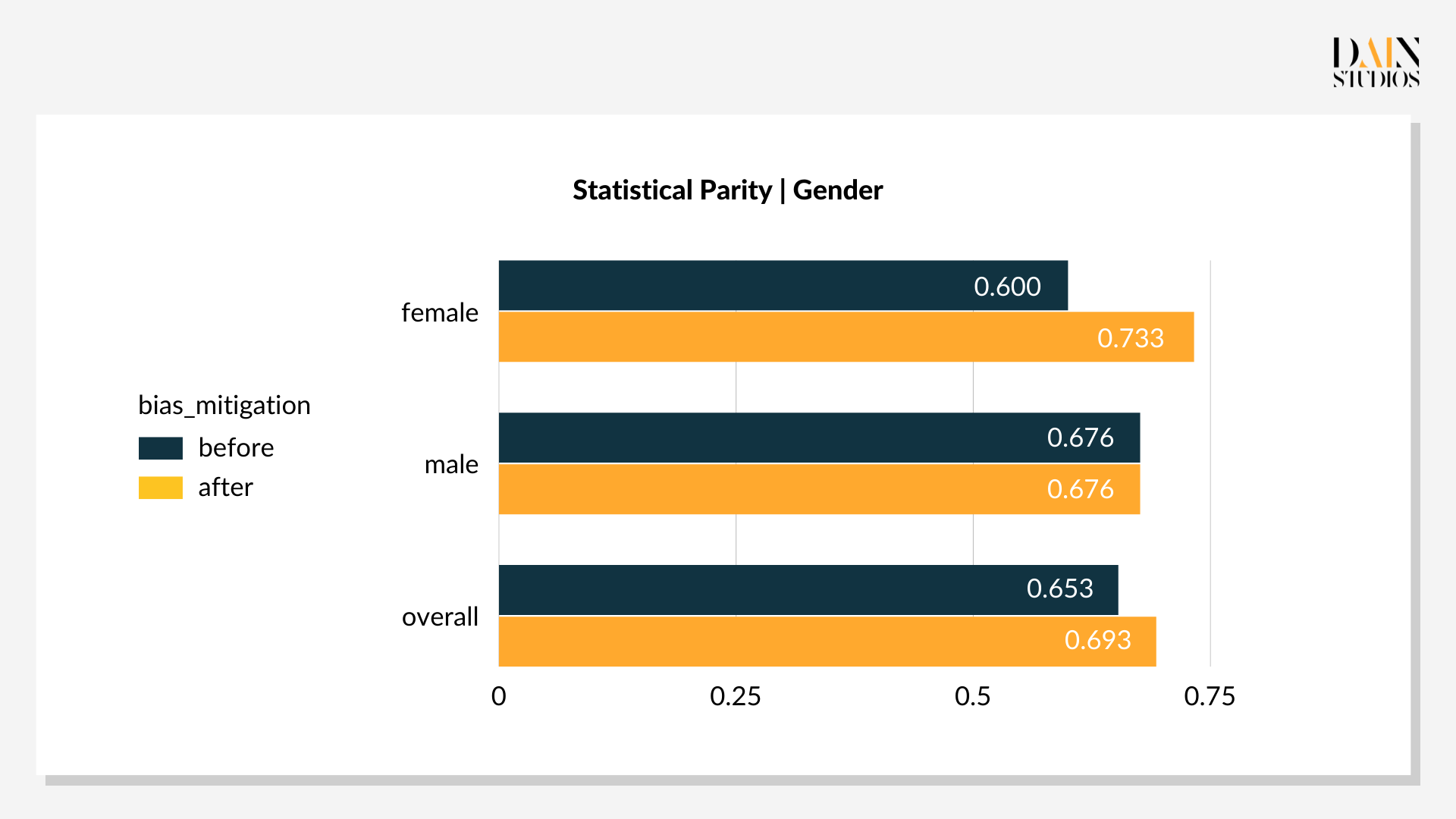
Techniken zur Reduzierung von Verzerrungen: In-Processing
In-Processing-Techniken zur Reduzierung von Verzerrungen modifizieren das ML-Modell , das die Kreditentscheidungen trifft. Anstatt die Trainingsdaten erneut zu erfassen, können die Modelle so angepasst werden, dass sie Verzerrungen berücksichtigen, auf die sie während dieser Lernphase stoßen, und so faire(re) Ergebnisse trotz verzerrter Daten ermöglichen. Unter mehreren verfügbaren Methoden wird die Rastersuche angewendet. Dabei wird eine Sequenz von optimierten Versionen des ursprünglichen Problems erstellt. Für Details kann man sich auf Agarwal et al. beziehen.
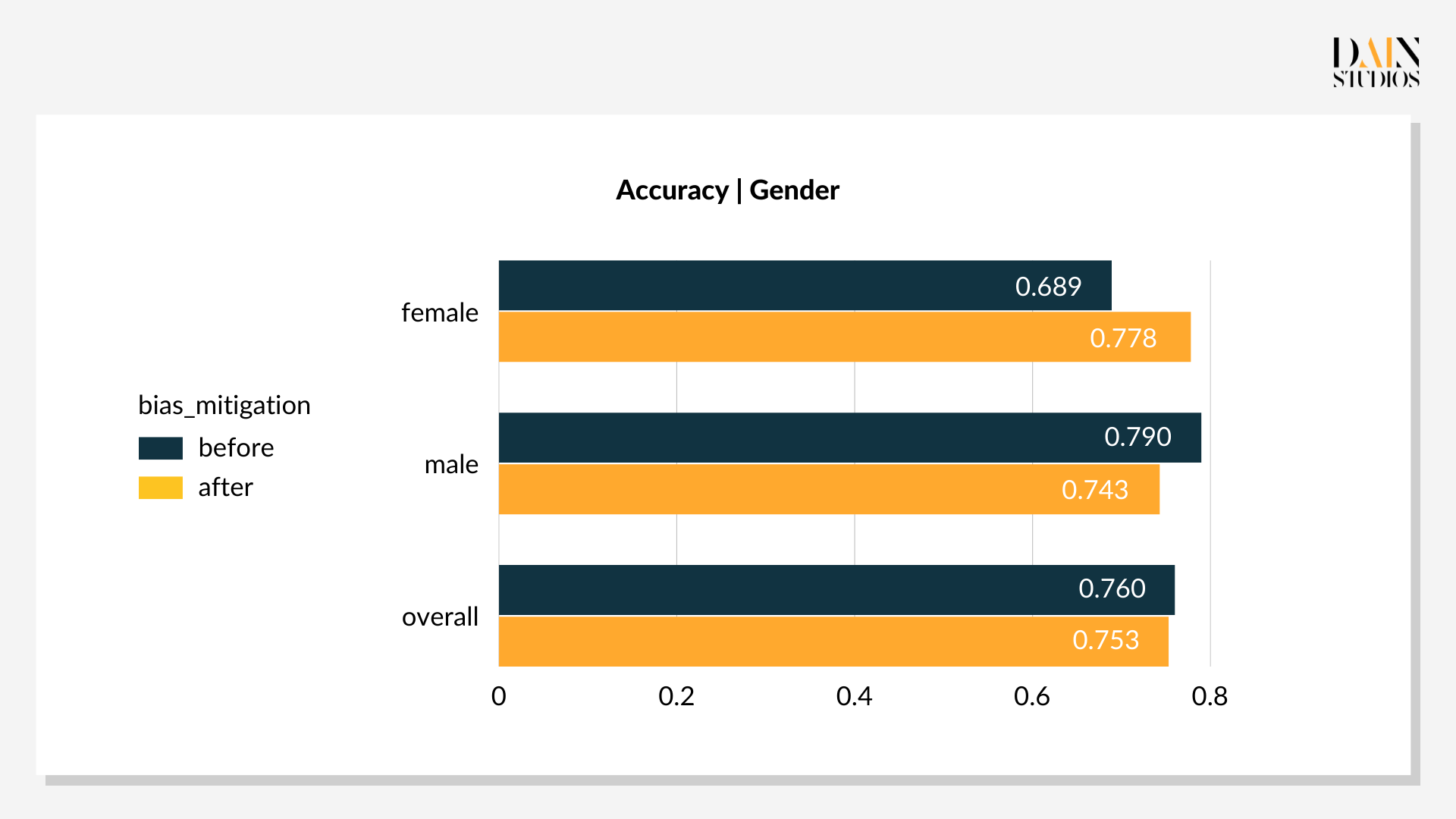
Techniken zur Reduzierung von Verzerrungen: Nachbearbeitung
Nachbearbeitungstechniken zielen auf die Ergebnisse des trainierten Modells ab. Da sie sich nicht mit dem zugrunde liegenden Datensatz oder dem ML-Modell befassen, ignorieren diese Methoden das Innenleben eines Modells, um sich auf das Ergebnis zu konzentrieren, das es hervorbringt.
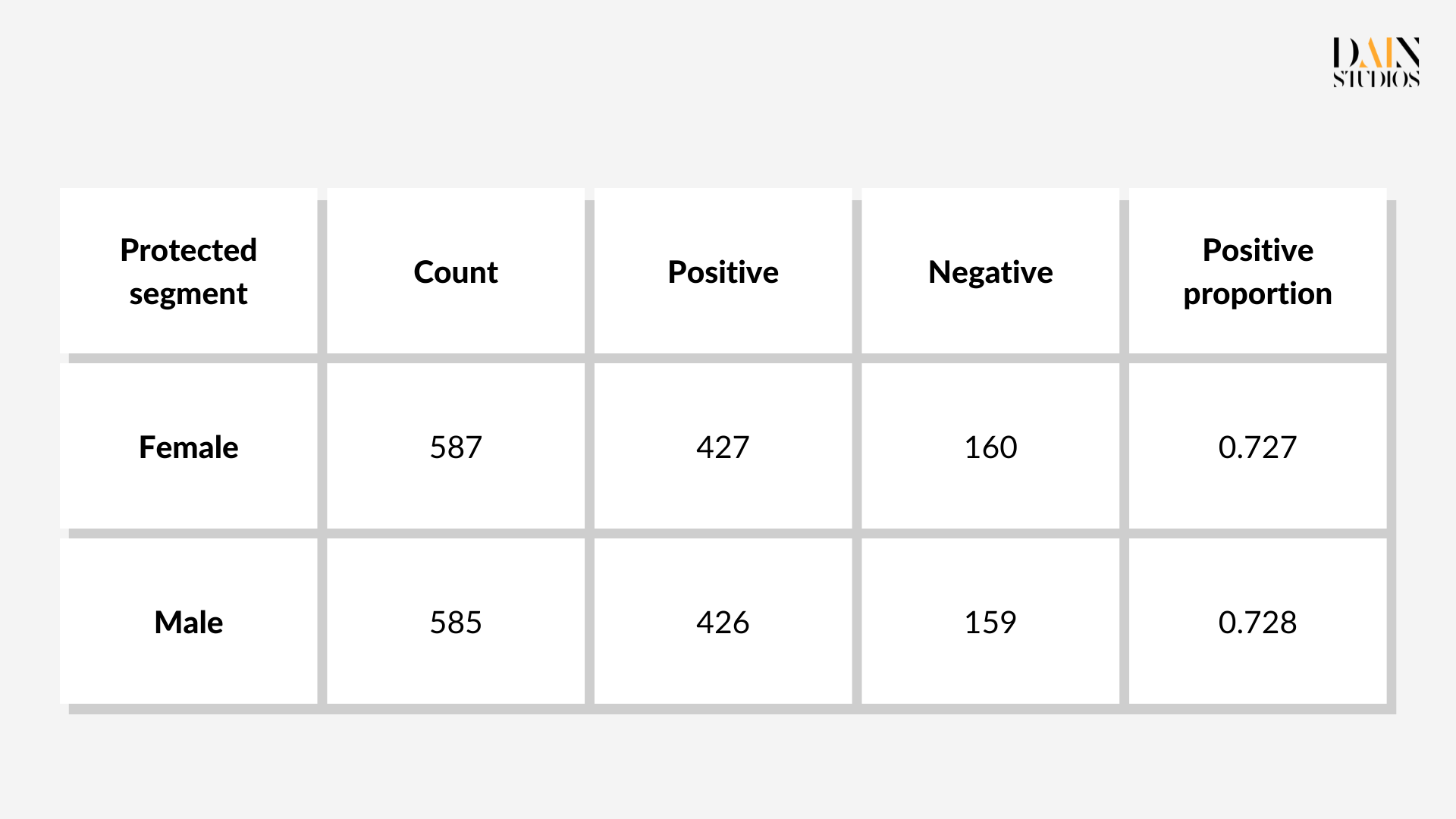
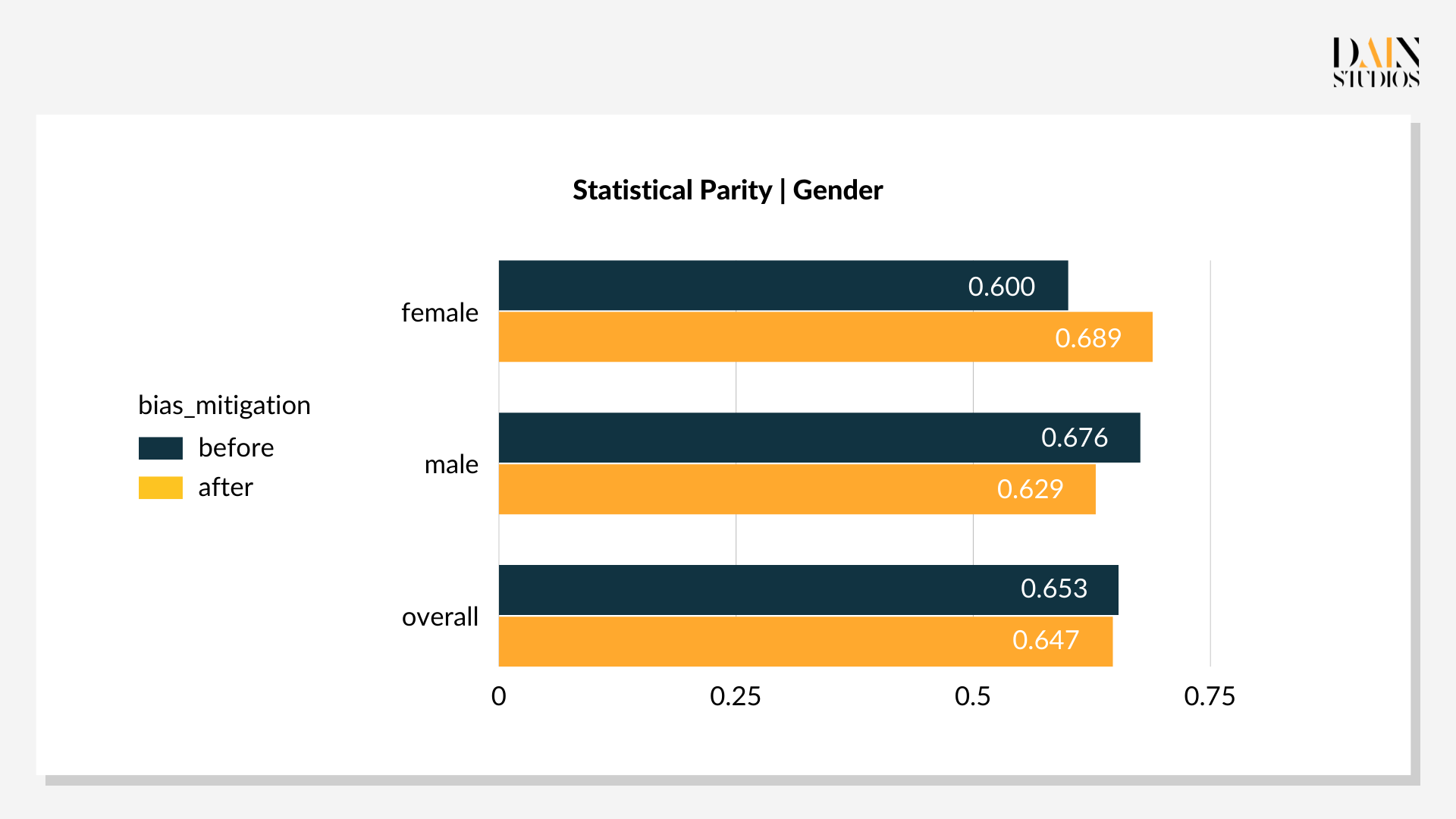
In diesem Beispiel berechnet das Modell zunächst, wie wahrscheinlich es ist, dass eine bestimmte Person in der Lage ist, einen Kredit zurückzuzahlen, z.B. Person A kann den Kredit mit einer Wahrscheinlichkeit von 0,9 zurückzahlen. Dann klassifiziert das Modell die Person als Person mit gutem Kreditrisiko, wenn ihre Wahrscheinlichkeit über einem bestimmten Schwellenwert liegt. Standardmäßig wendet das Modell bei der Entscheidungsfindung für alle Bewerber den gleichen Schwellenwert von 0,5 an. Man kann jedoch für bestimmte Gruppen unterschiedliche Schwellenwerte anwenden, z. B. eine niedrigere Schwelle für Frauen, um positivere Kreditergebnisse zu erzielen. Durch die Überarbeitung der Schwellenwerte für weibliche und männliche Bewerber im Deutschen Kreditdatensatz kann also die statistische Parität optimiert werden.
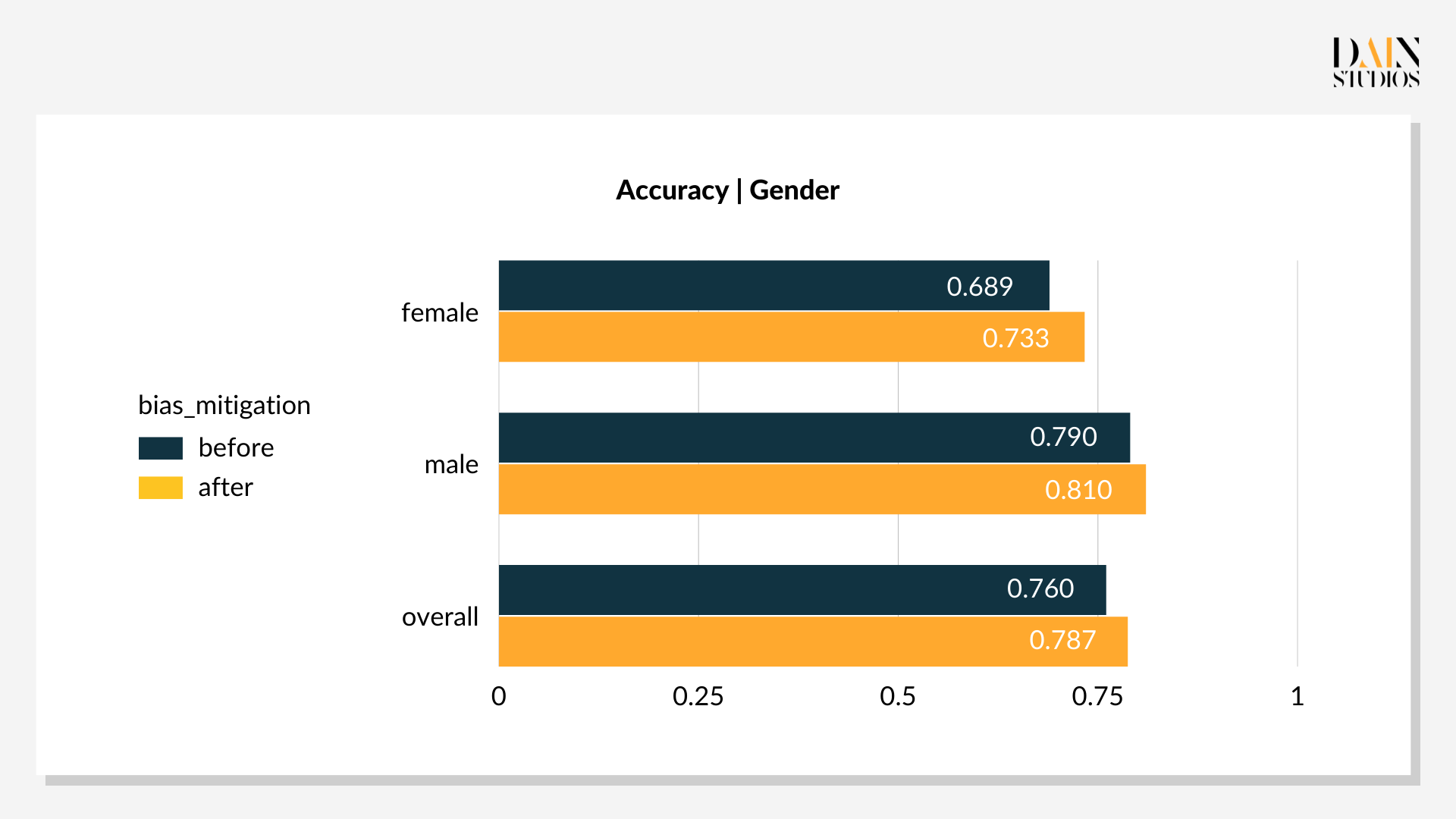
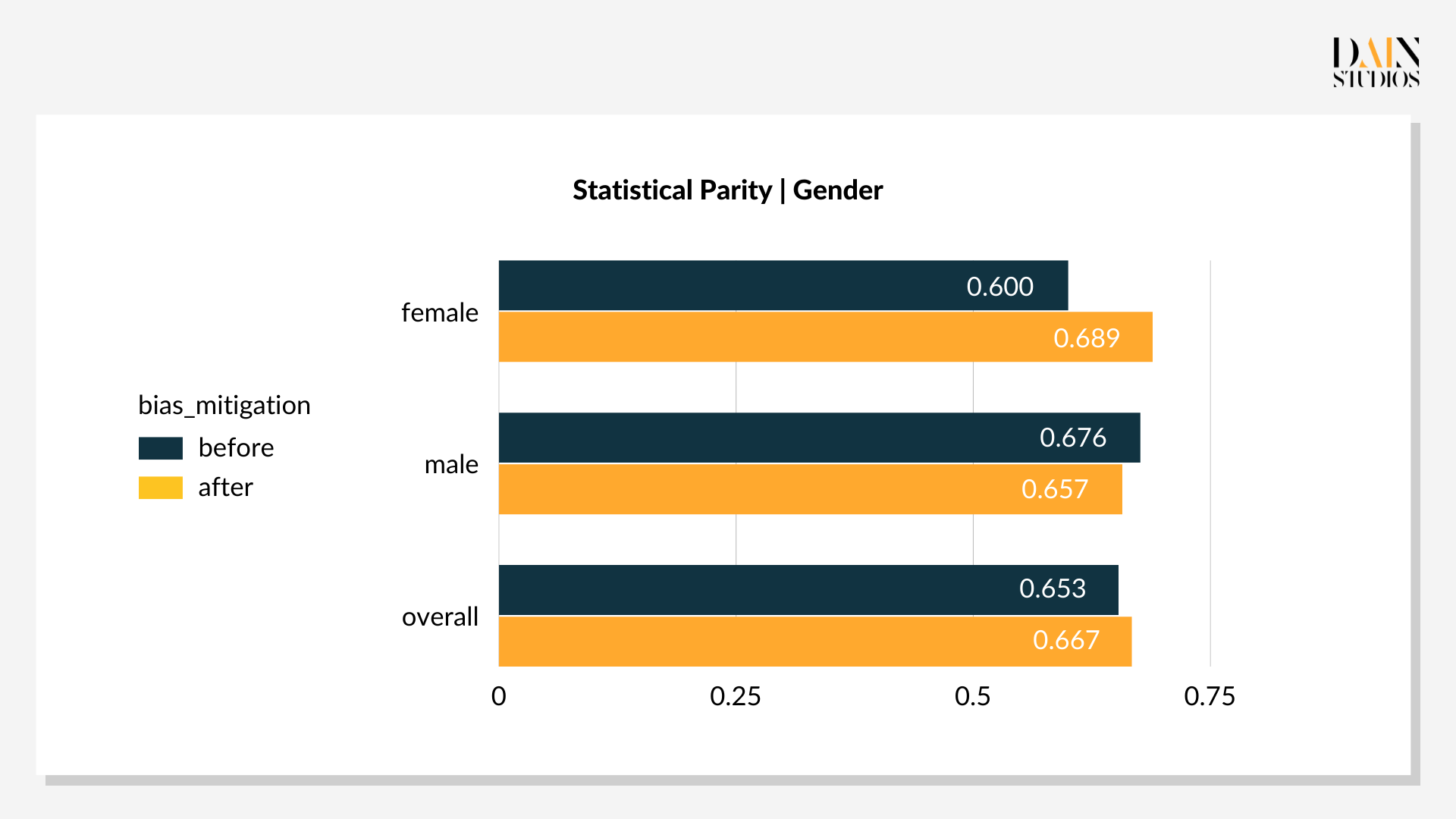
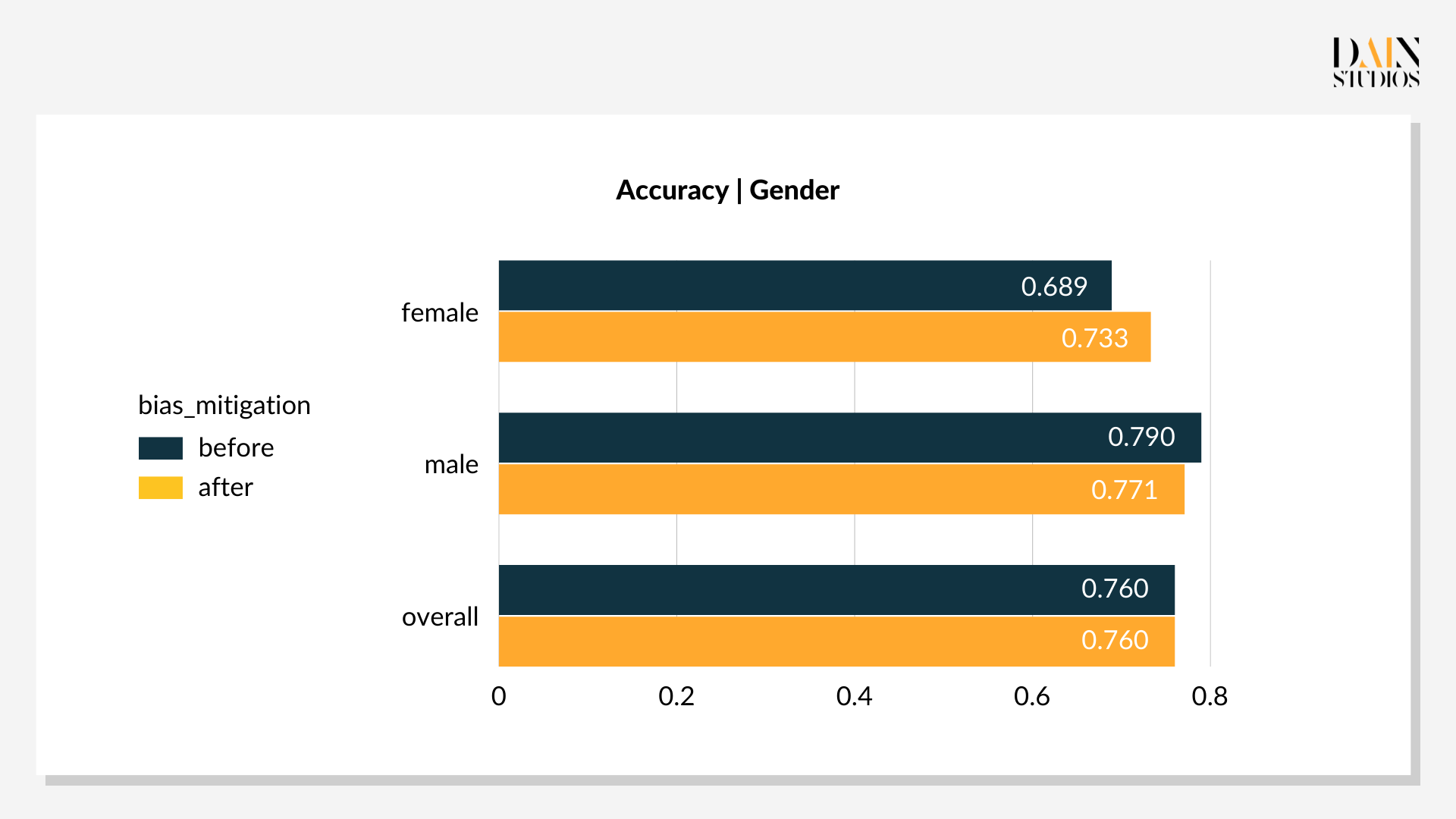
Die optimalen Schwellenwerte liegen bei 0,29 für Frauen und 0,59 für Männer. Diese niedrigere Schwelle für weibliche Kreditantragsteller und eine etwas höhere für Männer führt dazu, dass 69 % der Frauen und 66 % der Männer als gutes Kreditrisiko eingestuft werden. Die Verzerrung des Ergebnisses von drei Prozentpunkten zugunsten von Frauen ist akzeptabler als das Standardergebnis mit seiner Verzerrung von acht Prozentpunkten zugunsten von Männern. Auch die Gesamtgenauigkeit – das Verhältnis von richtigen Entscheidungen zu allen Entscheidungen – verbesserte sich um drei Punkte auf 79 %. Dies zeigt, dass Nachbearbeitungsoptimierungen nicht nur Verzerrungen reduzieren, sondern auch die Leistung eines ML-gesteuerten Systems verbessern können, wovon alle profitieren.
Verzerrungsreduzierung und ihre Anwendbarkeit
Die Methoden zeigen, dass Data Scientists eine Reihe von Optionen haben, um Verzerrungen zu bekämpfen, wenn sie feststellen, dass ein Machine-Learning-Modell unfair ist. Jede Technik kann auch als Reaktion auf die verfügbare Zeit und Ressourcen gesehen werden. Wenn Datensätze und Modelle leicht zugänglich sind, kann man sich daran machen, geeignete Vorverarbeitungs- und In-Verarbeitungstechniken zu identifizieren. In ihrer Abwesenheit können Nachbearbeitungstechniken genutzt werden. Es ist auch zu bedenken, dass die Leistung des Modells nicht unbedingt beeinträchtigt wird.