Das maschinelle Lernen (ML) spielt im Alltag eine immer größere Rolle, indem es uns hilft, Entscheidungen zu treffen - von der Wahl, welche Filme wir auf Netflix ansehen oder welche Nachrichten wir auf Facebook lesen, bis hin zu potenziell lebensverändernden Entscheidungen wie Arbeits- und Kreditanträgen oder Entscheidungen im Gesundheitswesen. Aber können wir diese automatisierten Entscheidungen, die von Systemen der künstlichen Intelligenz (KI) getroffen werden, als fair bezeichnen? Können wir uns auf ML-Algorithmen verlassen, wenn es um Kredit- und Stellenbewerbungen geht, oder sind sie anfällig für Verzerrungen, die sich negativ auf bestimmte Gruppen von Menschen auswirken würden? Leider waren in den letzten Jahren voreingenommene Entscheidungen von KI allgegenwärtig: Googles Suchmaschine scheint davon auszugehen, dass die meisten CEOs weiße Männer sind, Amazons kostenlose Lieferung scheint schwarze Viertel in US-Städten zu benachteiligen, und sein Einstellungsmodell war voreingenommen gegenüber Frauen, und es wurde nachgewiesen, dass Stellenanzeigen eher männlichen als weiblichen Verbrauchern angezeigt werden.
Solche Ungerechtigkeiten haben verschiedene Ursachen. Probleme können dadurch verursacht werden, worauf ein Algorithmus zu optimieren versucht. Eine bestimmte Art von Stellenanzeige, die mehr Männern als Frauen angezeigt wird, kann das Ergebnis eines Algorithmus sein, der sich auf die Kosteneffizienz der Werbung in einer Branche konzentriert, die für die Zustellung von Anzeigen an jüngere Frauen mehr verlangt als für Männer. Häufiger liegt das Problem in den Daten selbst - zum Beispiel waren in der Vergangenheit CEOs meist weiß und männlich, und solche veralteten Informationen können immer noch den neuesten KI-Systemen zugrunde liegen. Fehlerhafte Daten führen zu fehlerhaften Ergebnissen, oder, wie Informatiker zu sagen pflegen: "Garbage in, garbage out." Aber wie können wir entscheiden, ob ein System unfair ist oder nicht? Was kann ein Unternehmen tun, um negative Schlagzeilen wie die oben genannten zu vermeiden?
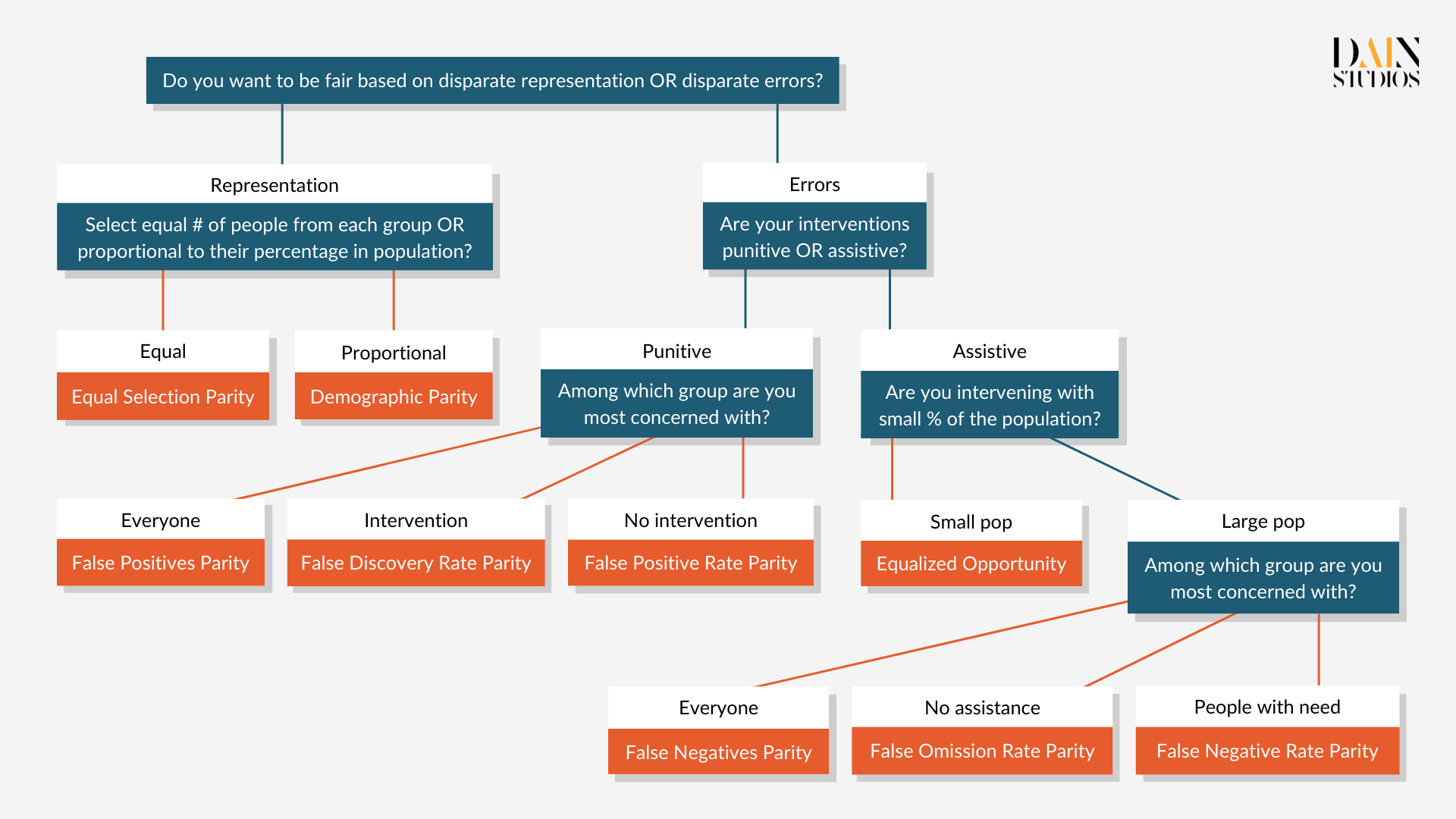
Wie lässt sich Fairness im Zusammenhang mit der Entscheidungsfindung messen?
Fairness im Zusammenhang mit der Entscheidungsfindung "ist die Abwesenheit von Vorurteilen oder Bevorzugung einer Person oder Gruppe aufgrund ihrer angeborenen oder erworbenen Eigenschaften", wie es die Forscher des Information Sciences Institute der University of Southern California ausdrücken. Aber wie kann sie gemessen werden? Stellen wir uns ein ML-Modell vor, das über die Kreditwürdigkeit von Personen entscheidet, die einen Bankkredit beantragen. Anhand von Kredithistorie, Einkommen, Alter, Vorstrafen usw. stuft es jede Person entweder als kreditwürdig (und damit wahrscheinlich als kreditwürdig) oder als kreditunwürdig (wahrscheinlich als zahlungsunfähig) ein. Wir müssen uns genauer ansehen, welche Entscheidungen das ML-Modell getroffen hat - und ob die als kreditwürdig eingestuften Personen die ihnen gewährten Kredite tatsächlich zurückgezahlt haben.
Wie wir die Fairness-Klassifizierungen in ML-Modellen bewerten
Der so genannte deutsche Kreditdatensatz enthält beispielsweise Informationen über 1000 Kreditantragsteller. Jede Person wird anhand einer Reihe von Merkmalen als gutes oder schlechtes Kreditrisiko eingestuft - wofür sie den Kredit benötigt, ihr Alter, ihr Geschlecht, ob sie Wohneigentum besitzt, wie viel sie gespart hat usw. Mit den von DAIN Studios entwickelten Tools können wir die Fairness dieser Klassifizierungen auf verschiedene Weise bewerten. Zunächst wählen wir das, was Datenwissenschaftler als "geschützte Variable" bezeichnen, d. h. die Variable, aus der sich die für uns interessante Bevölkerungsgruppe zusammensetzt. Dies kann die ethnische Zugehörigkeit, das Geschlecht, die Alters- oder Einkommensgruppe usw. sein. - oder eine Kombination davon, wenn wir uns z. B. dafür interessieren, wie Menschen einer bestimmten Altersgruppe und ethnischen Zugehörigkeit vom ML-Modell behandelt werden.
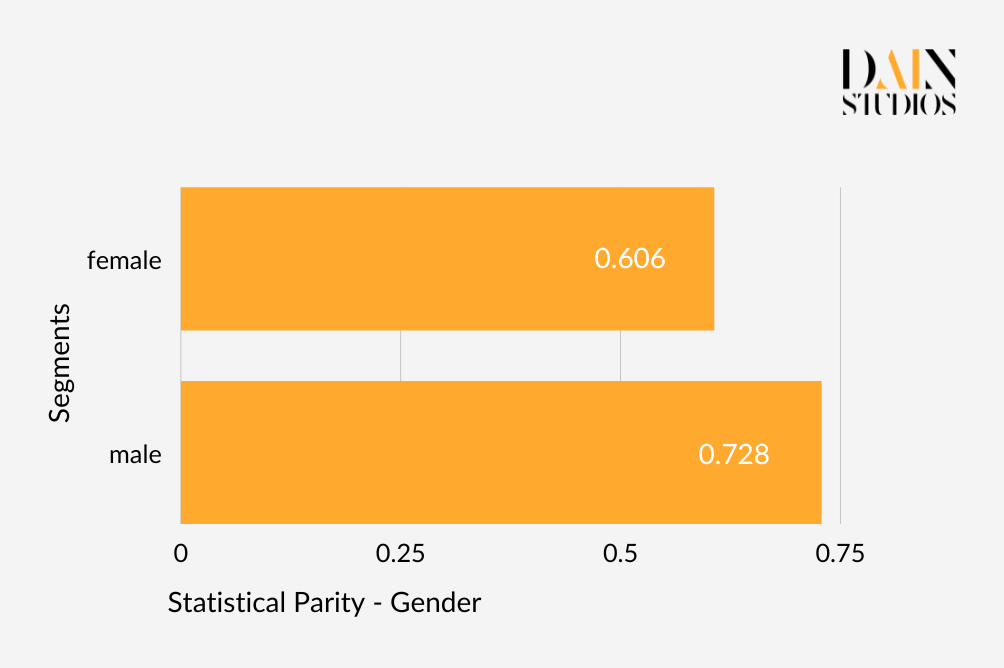
Nehmen wir das Geschlecht. Eine der gebräuchlichsten Definitionen von Fairness ist die demografische oder statistische Parität, die in diesem Beispiel sicherstellen würde, dass die Ergebnisse eines Algorithmus für Männer und Frauen gleich sind. Das bedeutet, dass der deutsche Kreditdatensatz eine Kreditantragsannahmequote haben sollte, die für Männer und Frauen ungefähr gleich ist. Im Kreditdatensatz erhielten 73 % der Männer den beantragten Kredit, aber nur 61 % der Frauen. Ob wir das Ergebnis als ungerecht ablehnen, hängt davon ab, wie streng wir sind. Ein gängiger Ansatz besteht darin, alles bis zu einem Unterschied von 20 Prozent zwischen zwei Werten als akzeptabel zu betrachten. Das würde in diesem Fall bedeuten, dass das ML-Modell des Datensatzes die demografische Parität in Bezug auf das Geschlecht erfüllt.
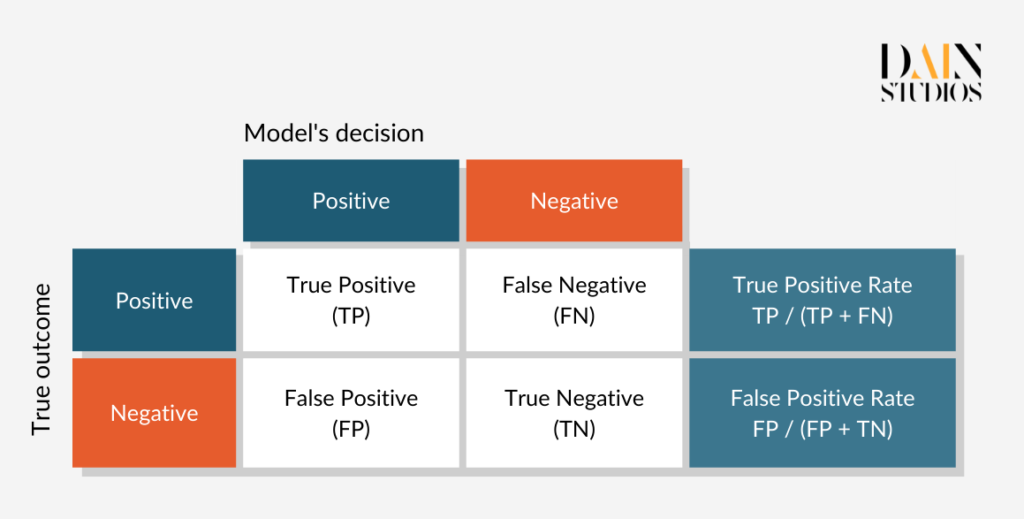
Ein Problem mit der demografischen Parität ist, dass sie auf unfaire Weise erfüllt werden kann. Mit Hilfe des Modells könnten wir zum Beispiel die besten 80 % der männlichen Bewerber sorgfältig auswählen und jede fünfte Frau nach dem Zufallsprinzip ablehnen. Dies würde das Ergebnis gemäß der demografischen Parität als gerecht erscheinen lassen. Eine alternative Fairness-Definition nennt sich Equalized Odds, die in diesem Fall sicherstellt, dass alle kreditwürdigen Antragsteller die gleiche Chance auf einen Kredit haben, unabhängig davon, ob sie Männer oder Frauen sind. Diese Bedingung ist erfüllt, wenn männliche und weibliche Anträge den gleichen Anteil an so genannten "True Positives" (Kredite, die an kreditwürdige Kreditnehmer vergeben werden) und "False Positives" (Kredite, die an riskante Kreditnehmer vergeben werden) aufweisen.
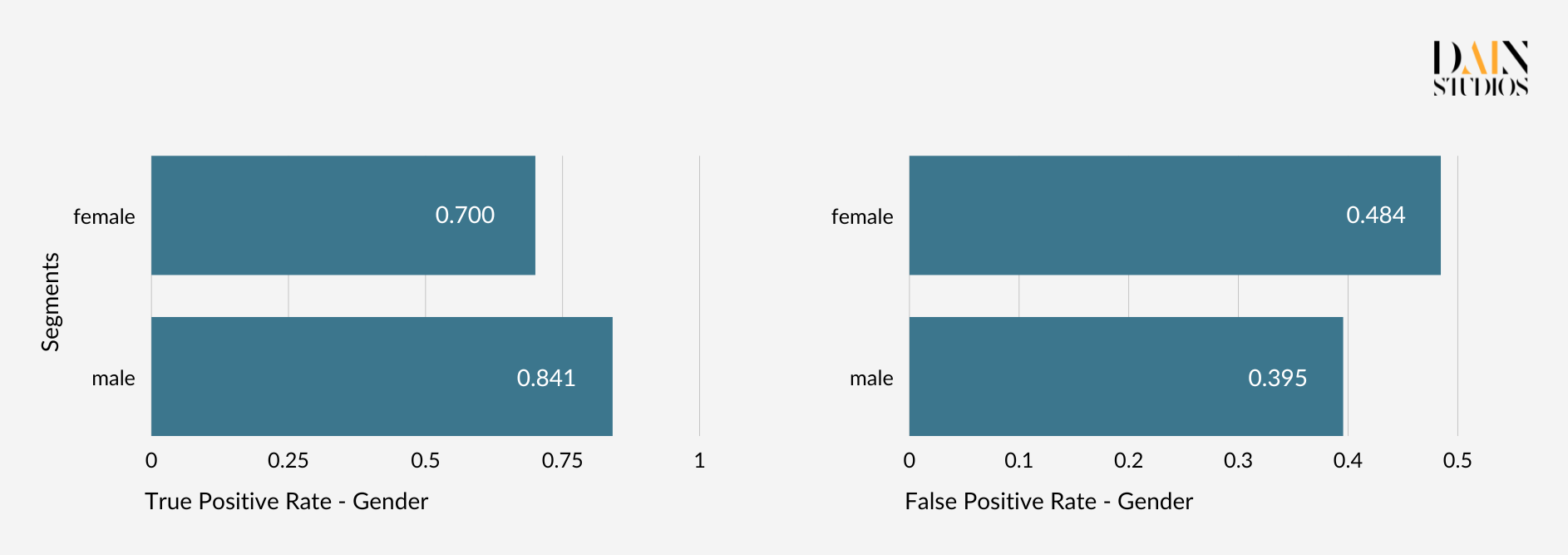
Die nachstehende so genannte Konfusionsmatrix hilft, dies zu verstehen. Anhand der Daten für Männer und Frauen aus unserem deutschen Kreditdatensatz können wir feststellen, welcher Anteil jedes Geschlechts zu Recht einen Kredit erhalten hat (echte Positive) und welcher Anteil zu Unrecht einen Kredit erhalten hat (falsche Positive). Dabei zeigt sich, dass, wenn wir den Empfehlungen des Modells folgen, 70 Prozent der kreditwürdigen Frauen und 84 Prozent der kreditwürdigen Männer einen Kredit erhalten, während 48 Prozent der kreditunwürdigen Frauen und 40 Prozent der kreditunwürdigen Männer ebenfalls einen Kredit aufnehmen können. Ob das ML-Modell Männer und Frauen wieder gleich behandelt, hängt davon ab, wie ernst wir die Diskrepanzen nehmen, die sich in diesen Fehlerquotenpaaren zeigen.
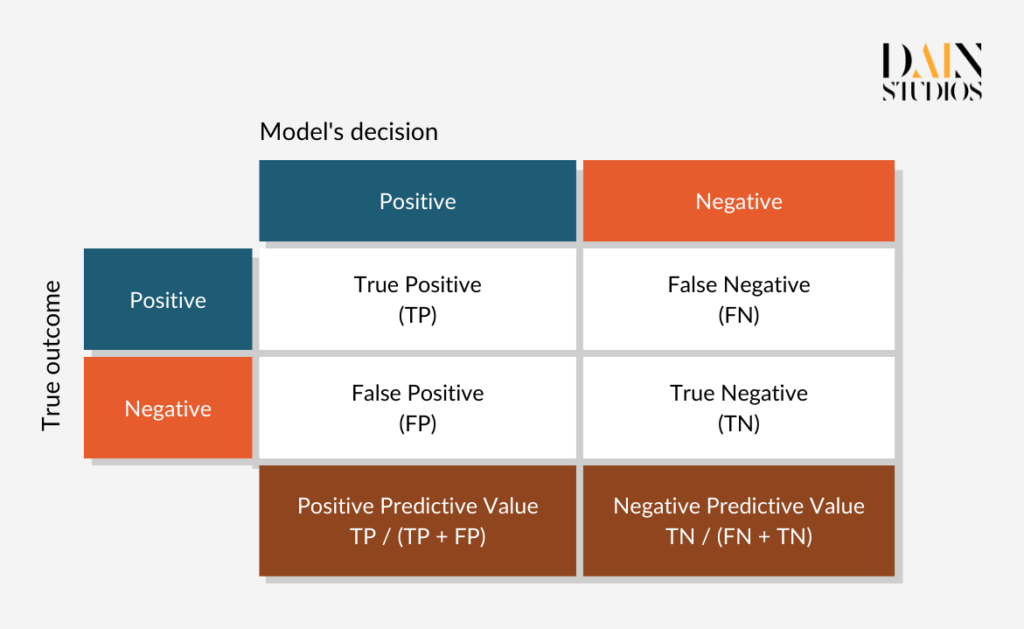
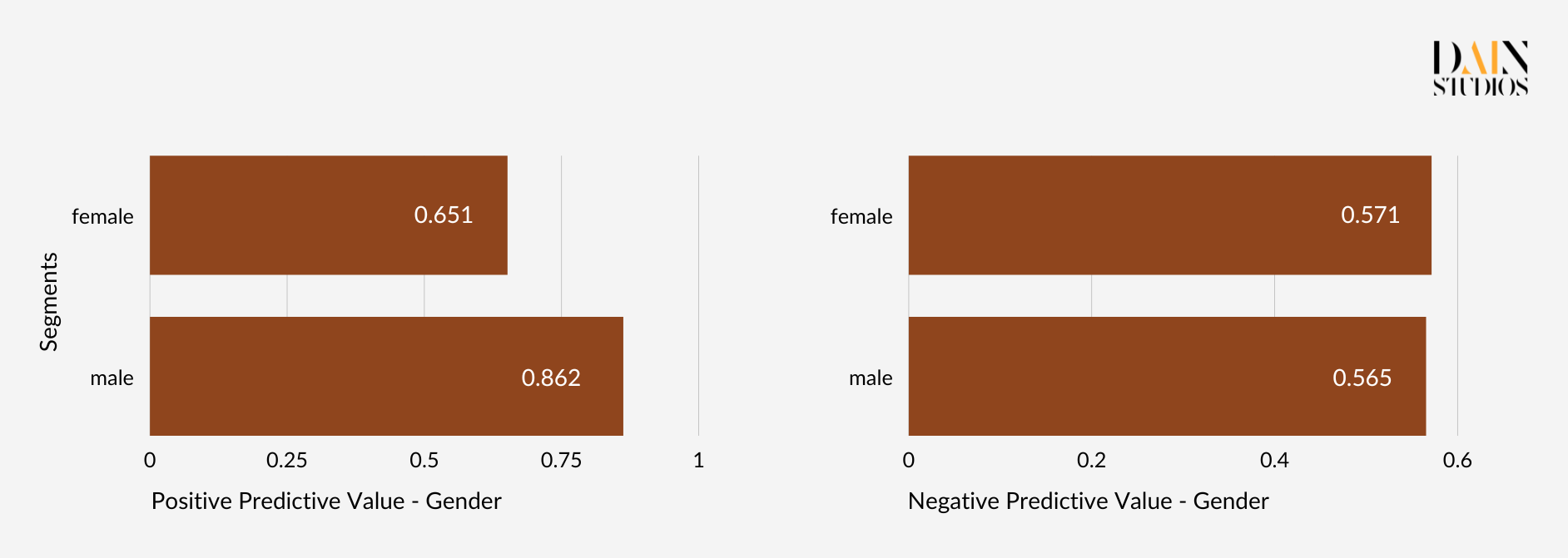
Um die Fairness von KI-Systemen zu messen, müssen wir je nach Anwendungsfall eine Fairness-Metrik auswählen.
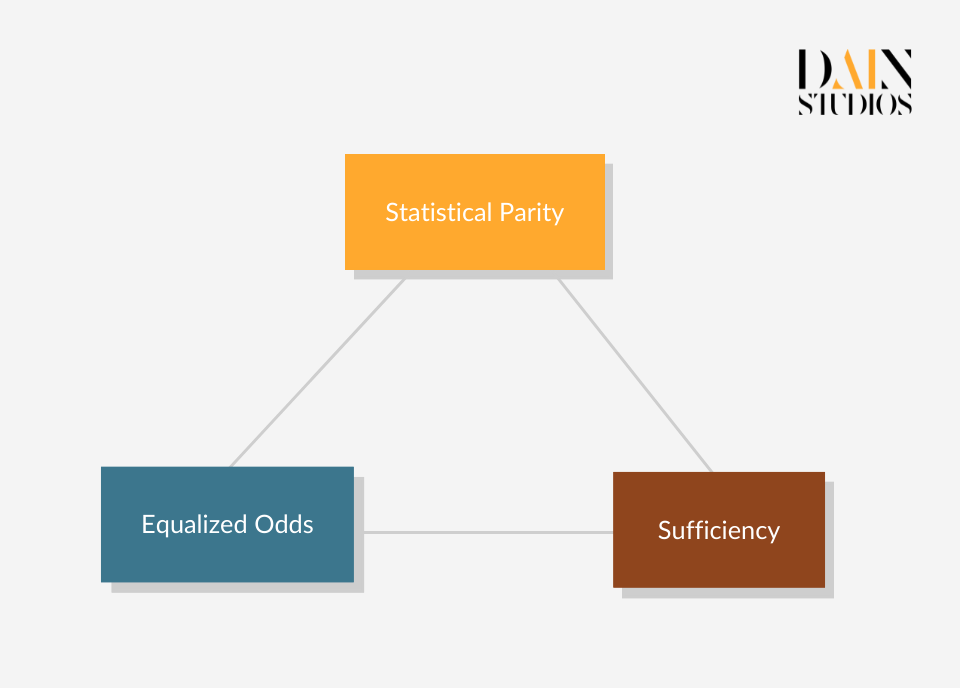
Es gibt noch viele weitere Fairness-Definitionen und -Kennzahlen, aber die meisten stützen sich auf die drei beschriebenen Arten. Wie können wir Algorithmen entwickeln, die alle diese Anforderungen erfüllen? Glücklicherweise müssen wir das nicht. Das Unmöglichkeitstheorem der Fairness besagt, dass die drei Fairnesskriterien - Unabhängigkeit (auch bekannt als demografische Parität), Trennung (auch bekannt als Chancengleichheit) und Suffizienz - nicht alle gleichzeitig erfüllt werden können. Das bedeutet, dass wir Kompromisse eingehen müssen, wenn wir über die Fairness von KI-Systemen nachdenken, und dass wir je nach Anwendungsfall eine Fairness-Metrik auswählen müssen. Equalized Odds" wäre zum Beispiel nicht die am besten geeignete Metrik für die Untersuchung der Fairness von Problemen, bei denen falsch-positive Ergebnisse selten sind, wie z. B. bei SARS-CoV-2-Antigentests. Wir sollten auch darüber nachdenken, ob die Entscheidung, die das ML-Modell unterstützen soll, strafend (wie die Festlegung einer Bewährungsstrafe) oder unterstützend (wie die Gewährung eines Kredits) ist.