Warum ist das wichtig?
In der heutigen datengesteuerten Welt spielt die algorithmische Entscheidungsfindung in vielen Aspekten unseres Lebens eine entscheidende Rolle, von der Kreditwürdigkeitsprüfung bis zur Einstellung von Personal. Mit der zunehmenden Abhängigkeit von Algorithmen wächst jedoch auch die Besorgnis über die mangelnde Transparenz der Entscheidungsprozesse. Transparente Prozesse sind entscheidend für den Aufbau von Vertrauen und die Förderung von Fairness in der algorithmischen Entscheidungsfindung.
Die Bereitstellung verständlicher Erklärungen zu algorithmischen Entscheidungen ist von wesentlicher Bedeutung, insbesondere bei Entscheidungen, die sich auf Einzelpersonen, wie Kunden oder Mitarbeiter, auswirken. Die Anforderungen an die Erläuterung von Entscheidungen wurden bereits in der Datenschutz-Grundverordnung (DSGVO) festgelegt, werden aber mit dem kommenden KI-Gesetz der EU noch relevanter werden. Entscheidungsträger in Unternehmen müssen verstehen, wie Algorithmen zu ihren Entscheidungen kommen, ihre Genauigkeit bewerten und mögliche Verzerrungen oder Fehler erkennen. Dies kann die Effizienz des Unternehmens auf allen Ebenen erhöhen, auf denen Algorithmen den Entscheidungsprozess unterstützen.
Sprachmodelle wie ChatGPT können helfen, die Kluft zwischen technischen Erklärungen und der breiten Öffentlichkeit zu überbrücken. Sie können klar und prägnant erklären, wie Algorithmen zu ihren Entscheidungen kommen. Erklärbarkeitsalgorithmen wie SHAP können ebenfalls wertvolle Erkenntnisse liefern, aber die Informationen, die sie bieten, sind für Menschen, die keine Datenwissenschaftler sind oder nur über ein begrenztes technisches Verständnis verfügen, oft nicht leicht zu verstehen.
Durch leichter zugängliche und verständliche Erklärungen für algorithmische Entscheidungen können Organisationen Vertrauen in ihre Entscheidungsprozesse aufbauen, was besonders wichtig ist, wenn es um Entscheidungen geht, die Auswirkungen auf den Einzelnen haben. Dies kann letztlich zu besseren Ergebnissen für Einzelpersonen, Organisationen und die Gesellschaft als Ganzes führen.
Der Prozess für POC
In einem Proof-of-Concept-Experiment haben wir versucht, erklärbare KI-Techniken wie SHAP-Werte und Kontrafaktizitäten mit ChatGPT zu verbinden.
Um die gewünschten Modellerklärungen zu erstellen, muss ChatGPT etwas über die Daten wissen. Insbesondere muss es die Bedeutung der Felder, ihren Wertebereich und die Implikationen der einzelnen kategorialen Werteigenschaften kennen:

Nach der Eingabe der Daten können wir Erklärungen erstellen. ChatGPT muss den zu erklärenden Datenpunkt sowie die zugehörigen SHAP-Werte kennen:
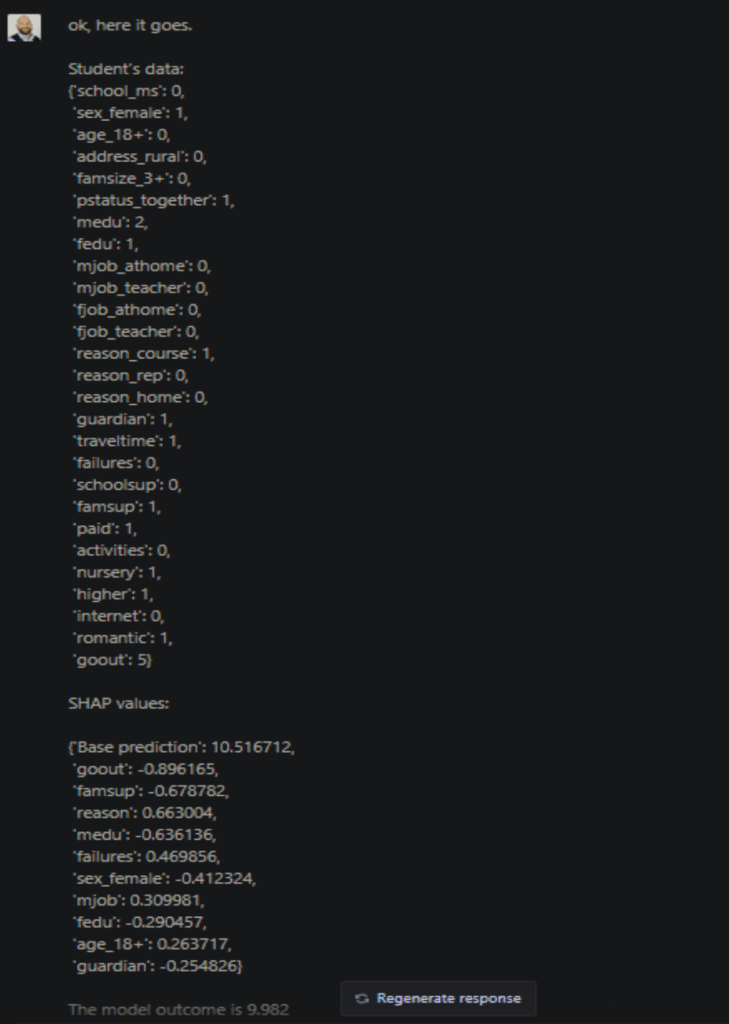
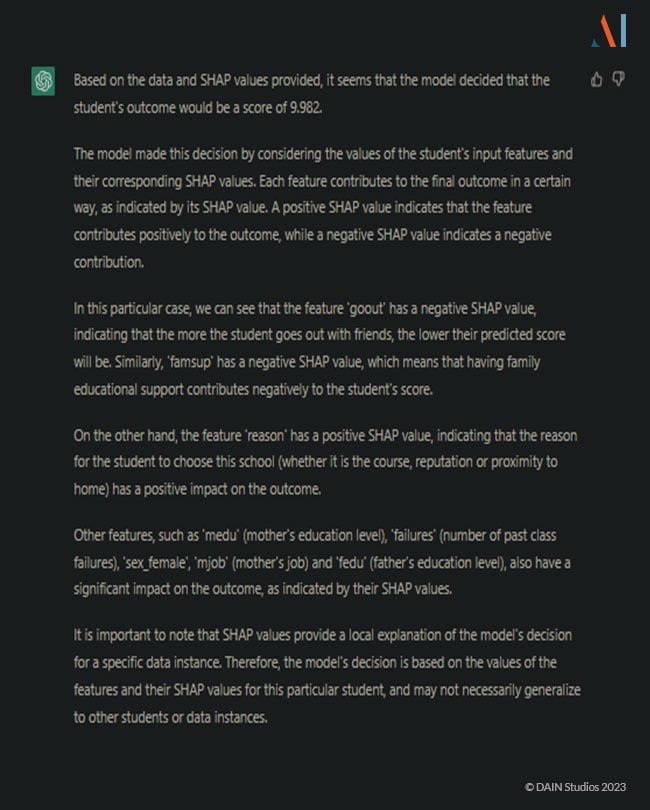
Dies wäre die normale Softwareausgabe. Sie könnte in ein Dashboard eingebettet werden, um eine visuelle Unterstützung zu bieten, aber sie hilft niemandem, der nicht über das technische Wissen verfügt, die Gründe für das Modellergebnis zu verstehen. Die erste Erklärung, die ChatGPT liefert, ist immer noch ein wenig technisch:
Um eine einfachere Erklärung zu erhalten, benötigt ChatGPT eine spezielle Anfrage:
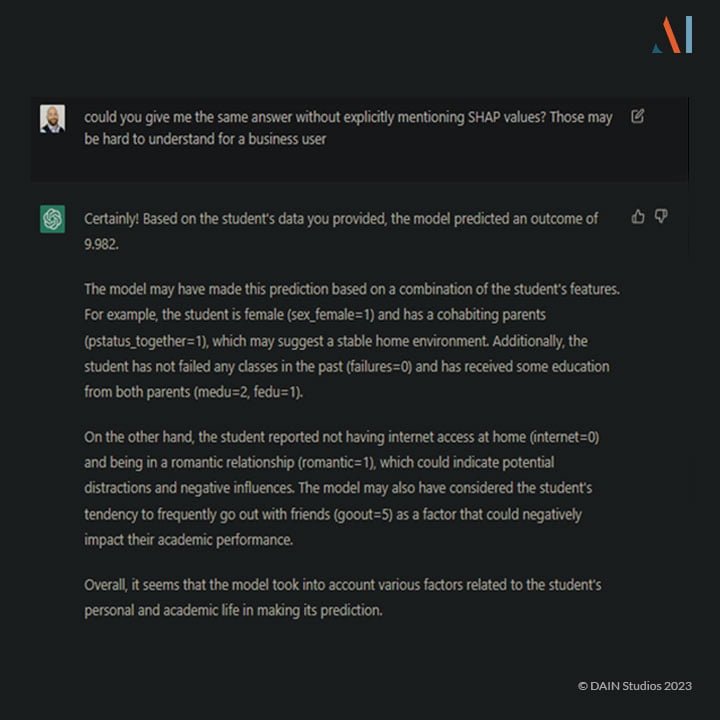
Diese Erklärung ist etwas einfacher und könnte wohl von den meisten Menschen verstanden werden, unabhängig von ihren technischen Kenntnissen. Wenn wir jedoch eine noch einfachere Erklärung benötigen, können wir sie anfordern:
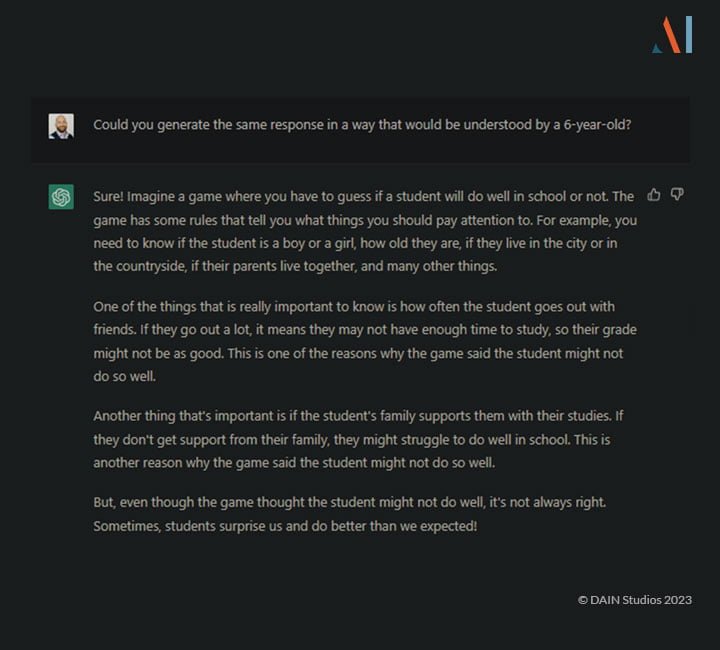
Diese Erklärung ist zwar vereinfacht, aber sie bringt die Sache auf den Punkt, ohne Zahlen zu verwenden.
Sobald wir die Erklärung für die Entscheidung des Modells erhalten haben, möchten wir vielleicht wissen, wie diese Entscheidung rückgängig gemacht oder verbessert werden könnte. Angenommen, es gäbe ein Modell für die Gewährung oder Verweigerung eines Kredits oder die Einstellung eines Mitarbeiters, dann ist es legitim zu fragen, warum und wie die Entscheidung rückgängig gemacht werden könnte. ChatGPT kann diese Erklärung ohne Kenntnis des Modells nicht geben:
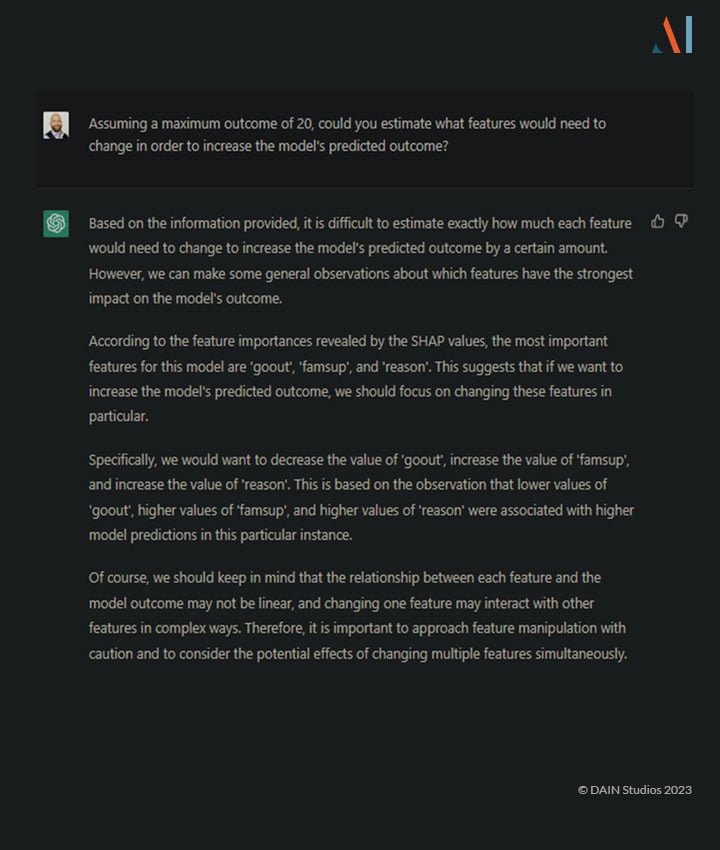
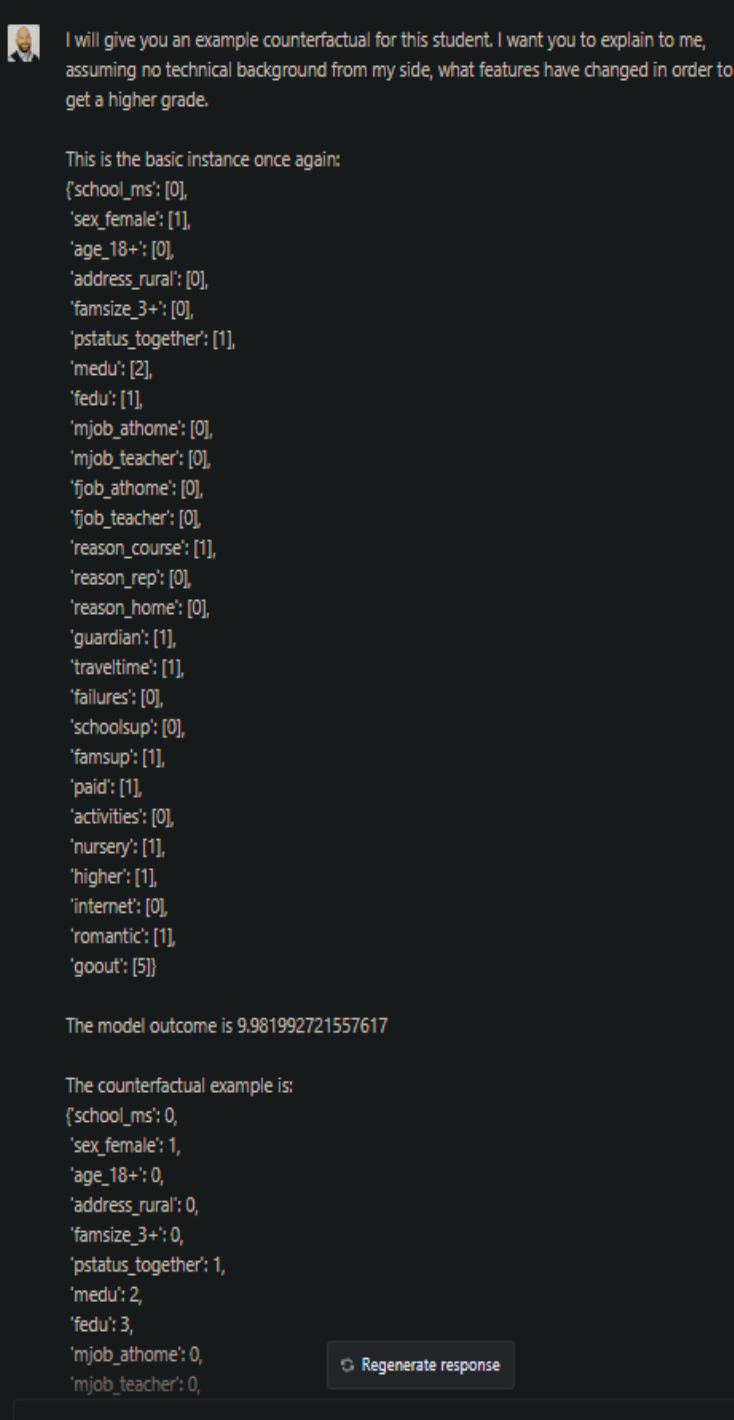
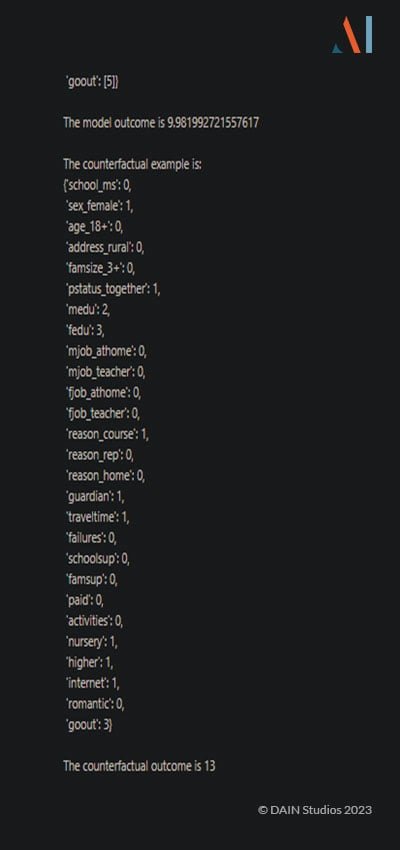
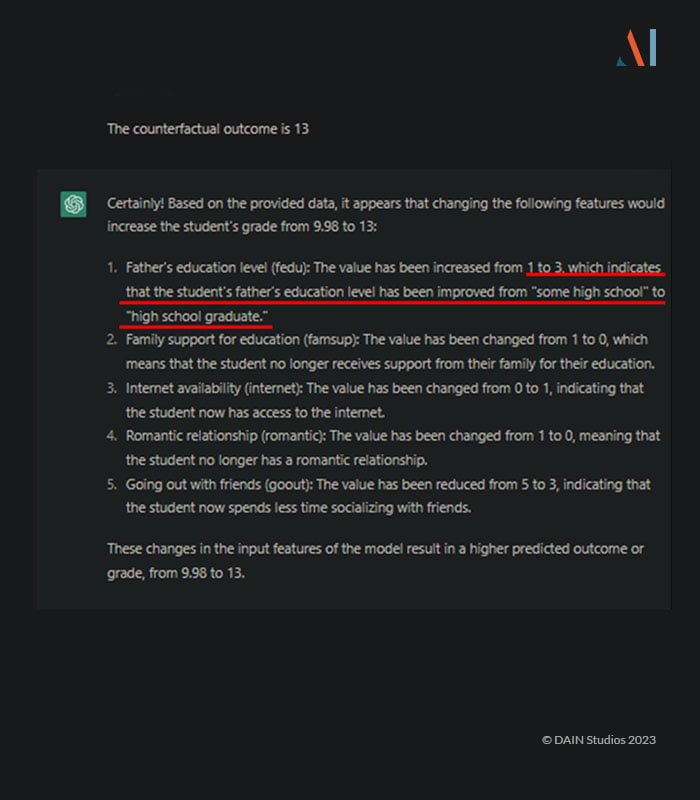
Das Programm gibt eine vernünftige Einschätzung dessen ab, was sich ändern müsste, warnt aber davor, diese Erklärungen für bare Münze zu nehmen, und verzichtet auf die Angabe konkreter Zahlen. Wenn man jedoch die Daten für eine korrekte kontrafaktische Situation von einer anderen Software erhält, kann sie leicht erklären, welche Änderungen für das gewünschte Ergebnis erforderlich wären: (Klicken Sie zum Vergrößern.)
{kind=link}
{kind=link}
{kind=link}
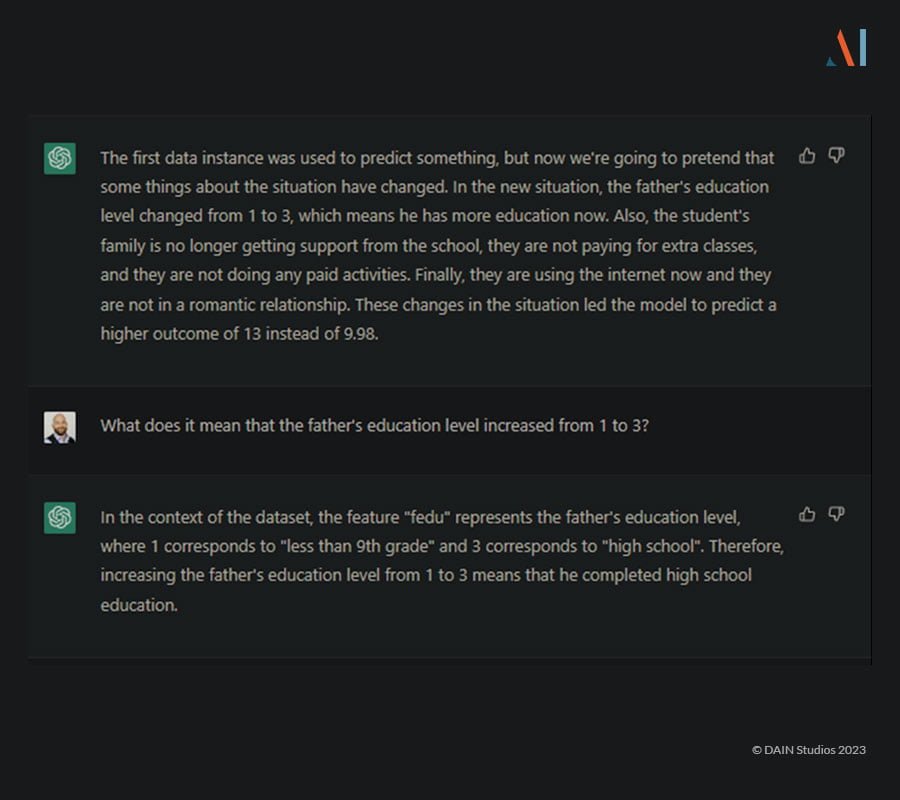
Diese Antworten erklären, wie die Entscheidung des Modells zu Gunsten des Benutzers geändert werden kann. Es ist jedoch wichtig zu beachten, dass die Erstellung dieser Erklärungen voraussetzt, dass ChatGPT detaillierte Informationen über die Daten hat. Wenn wir zum Beispiel im Datenwörterbuch keine Informationen über die Werte des kategorischen Merkmals "fedu" angeben, passiert Folgendes:
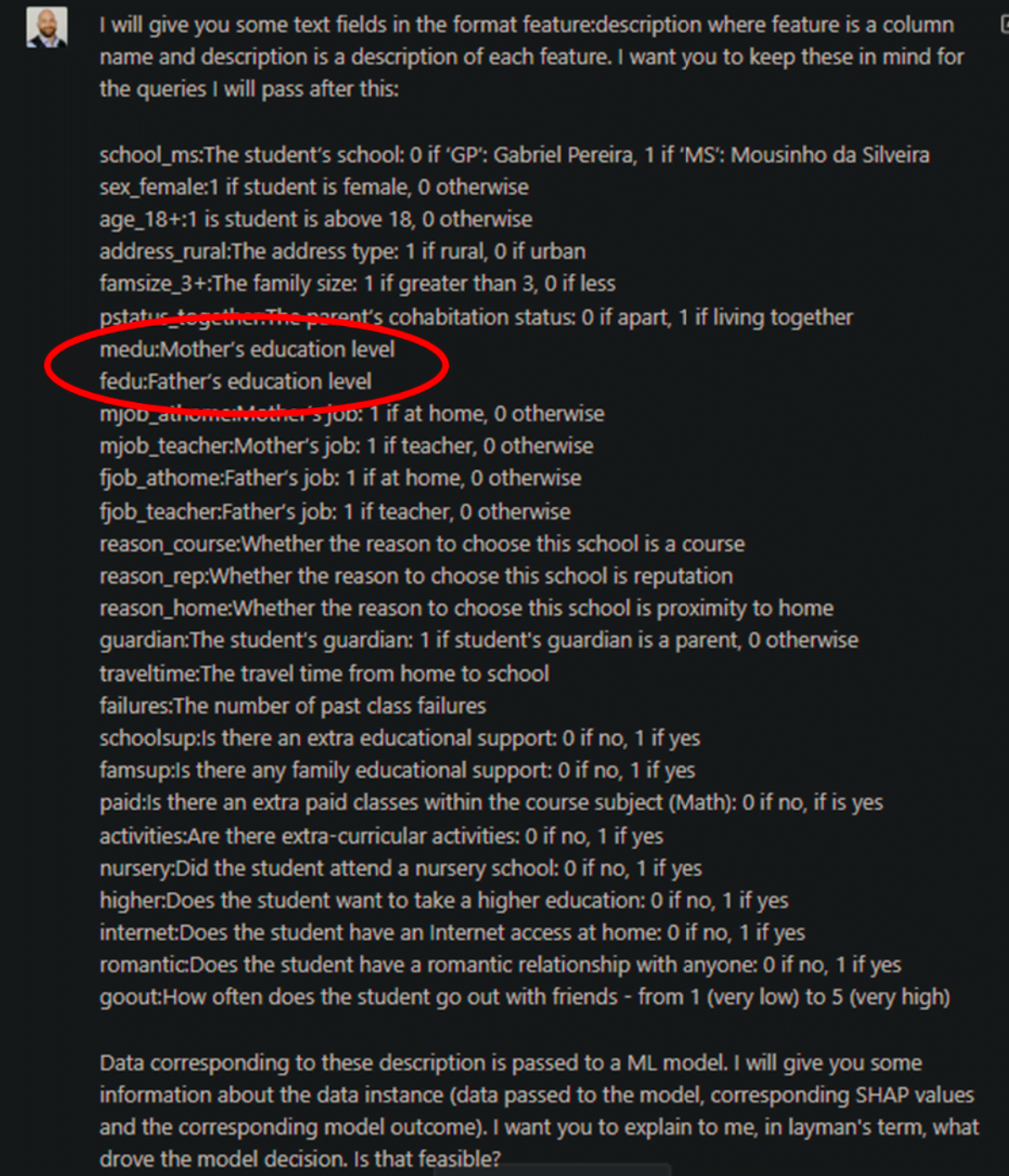
Die sich daraus ergebende Erklärung der kontrafaktischen Situation ist am Ende falsch: ChatGPT rät eher, als zuzugeben, dass es falsch ist.
Dies ist eine falsche Annahme und stellt eine Grenze des aktuellen ChatGPT-Modells dar. Um diese Art von Fehlern zu vermeiden, ist die Qualität des Datenwörterbuchs entscheidend.
Generell könnten Sprachmodelle ein leistungsfähiges Instrument sein, um Menschen, die verstehen wollen, wie sie die Ergebnisse von ML-Modellen verbessern können, aber vielleicht nicht die Zeit oder Lust haben, eine Menge Fachjargon zu lernen, technische Schlussfolgerungen zu erklären. Die Umsetzung ist einfach, wenn die entsprechenden (Meta-)Daten vorhanden sind.
Beschränkungen des POC und andere Risiken
Die mit ChatGPT erstellten Erklärungen waren zwar verständlich und in Sekundenschnelle erstellt, aber es ist erwähnenswert, dass die Daten, die benötigt werden, um genaue Informationen zu erhalten, mit einer speziellen Software-Suite erstellt wurden. ChatGPT kann ein Modell nicht erklären, wenn man nicht die richtigen Daten hat oder weiß, wie das Modell funktioniert. Als es gebeten wurde, ein kontrafaktisches Modell auf der Grundlage der SHAP-Werte zu erstellen, gab es sein Bestes, räumte aber gleichzeitig ein, dass es das Modell nicht kennt und warnte vor
die vorläufige Erklärung zu ernst zu nehmen, da die Schlussfolgerungen, die aus den SHAP-Werten gezogen werden könnten, nicht auf das allgemeine Modell übertragbar wären.
Wenn die Metadaten nicht detailliert genug sind, haben wir bereits gezeigt, dass ChatGPT erraten kann, was die Merkmalswerte bedeuten. Der Fehler wurde dank des spezifischen Domänenwissens erkannt, aber wenn die ChatGPT-Erklärung einem Schüler gegeben worden wäre, der versucht hat, seine Note zu verbessern, ohne etwas über die Daten zu wissen, hätte sie wenig Sinn ergeben oder, schlimmer noch, sie wäre vielleicht nie als Fehler verstanden worden. Im Falle eines Darlehensantrags oder einer Einstellungsentscheidung hätte dies einen Rechtsstreit nach sich ziehen können.
Um dieses Proof-of-Concept zu einer vollständigen Anwendung auszubauen, wäre eine Software zur Generierung von ML-Erklärungen erforderlich, aber danach würde ein einfacher API-Aufruf ausreichen, um mit minimalem Aufwand Erklärungen zu automatisierten Modellen für die Allgemeinheit zu generieren.
Künftige Möglichkeiten der Verwendung einer API mit ChatGPT oder anderen Sprachmodellen
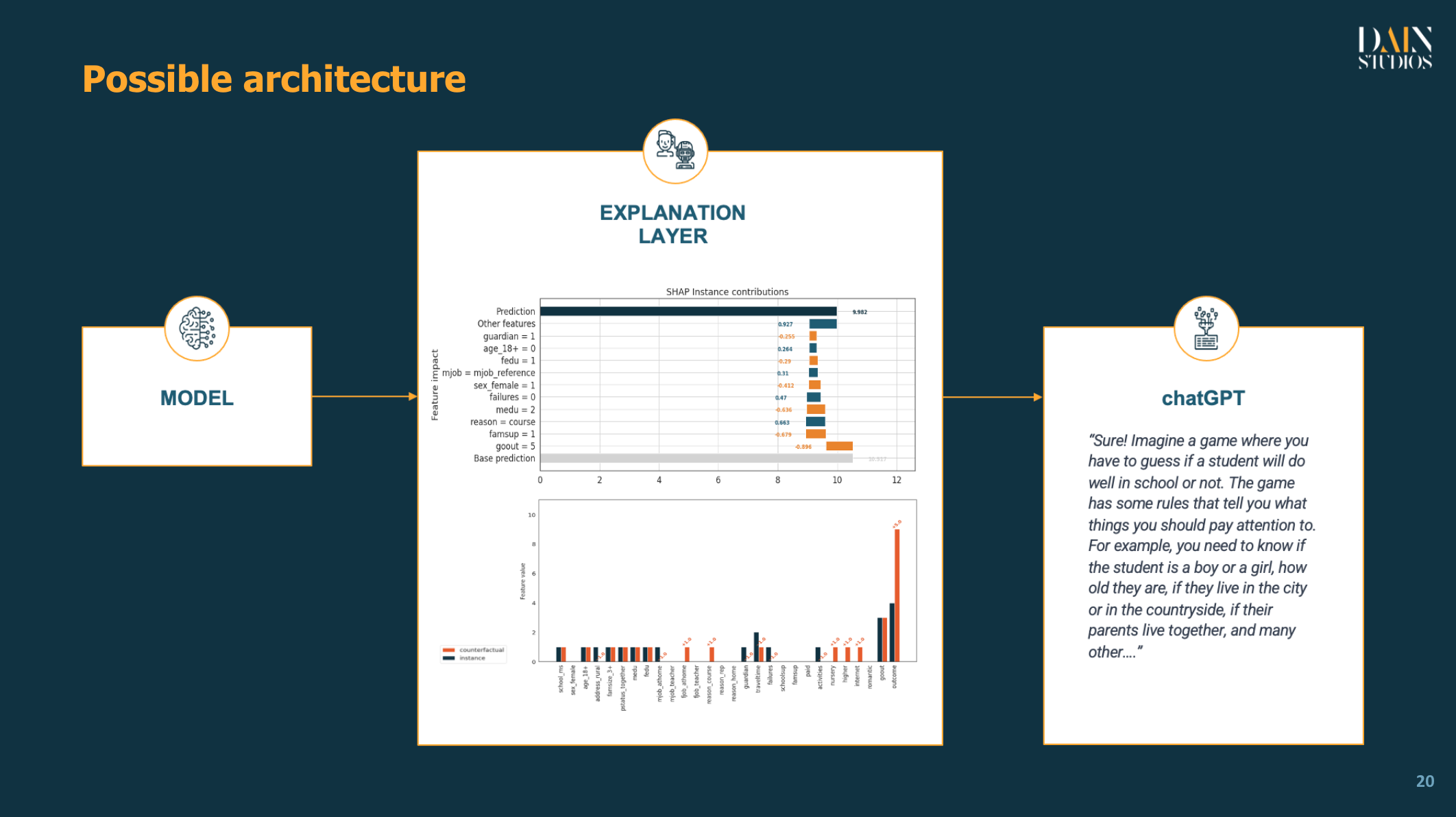
Wenn wir ChatGPT in der Industrie einführen, könnte die bisher demonstrierte Nutzung ML-Erklärungen für jede Art von Nutzer vereinfachen. Was die Systemarchitektur betrifft, so können wir, sobald die entsprechende Software die relevanten Erklärungen generiert, über eine API eine Verbindung zu jedem großen Sprachmodell herstellen und die ML-Erklärungen für die breite Öffentlichkeit skalieren.
Wie im Proof-of-Concept hervorgehoben wurde, ist es wichtig, sich die Mühe zu machen, ein präzises Datenwörterbuch zu erstellen, in dem die Bedeutung aller Merkmale und ihre Werte (falls kategorisch) oder Verteilungen (falls numerisch) aufgeführt sind.
Vor der Einführung sollten gründliche Tests durchgeführt werden, um sicherzustellen, dass das Sprachmodell alle notwendigen Informationen enthält, um die im Modell verwendeten Daten zu beschreiben und sinnvolle Erklärungen zu liefern. Außerdem sollte, wie bei jeder IT-Lösung, eine ständige Überwachung stattfinden, um sicherzustellen, dass die Qualität der Antworten auf einem Niveau bleibt, das Beschwerden der Öffentlichkeit vermeidet.
Schlussfolgerung
Software-generierte Erklärungen für ein maschinelles Lernmodell wurden an ChatGPT übergeben, um die Informationen für nicht-technische Benutzer zu vereinfachen. ChatGPT kann dies recht gut, wenn wir eine detaillierte Beschreibung der Daten liefern.
Wenn das Datenwörterbuch fehlende Informationen enthielt, versuchte ChatGPT, die Bedeutung der Werte für die unklaren Merkmale zu erraten. Das Raten stellt ein Risiko dar, da es zu falschen Erklärungen führen kann, die von Personen ohne Fachwissen unbemerkt bleiben können.
Da die Anforderungen an die Transparenz im Entscheidungsfindungsprozess immer höher werden (vor allem bei automatisierten Entscheidungen), könnten Sprachmodelle ein wertvolles Hilfsmittel sein, um die Erklärbarkeit von maschinellem Lernen für ein breiteres Publikum zu verbessern, ohne dass dieses spezielle technische Konzepte erlernen muss, die üblicherweise von Datenwissenschaftlern verwendet werden.
Im Allgemeinen können wir ein Sprachmodell verwenden, um die Kommunikation zwischen Technikern und Geschäftsleuten sowie zwischen Unternehmen und Kunden zu verbessern. Sprachmodelle können Konzepte vereinfachen, die andernfalls für Menschen, die keine Zeit, Notwendigkeit oder Lust haben, sich spezielles technisches Wissen anzueignen, schwer zu vermitteln wären.