Unter DAIN Studios erforschen wir, wie künstliche Intelligenz "erklärt" werden kann. Wir haben den Artikel "Erklärbare KI (XAI)" mit einer Einführung in die XAI und was wir von ihr erwarten können. In diesem Artikel werden die verfügbaren XAI-Methoden anhand von praktischen Beispielen näher erläutert.
In den letzten zehn Jahren hat das allgemeine Interesse an XAI zugenommen, angetrieben durch die Fortschritte der KI, insbesondere durch moderne komplexe KI-Methoden wie Deep Learning, die naturgemäß schwer zu erklären sind.
Viele XAI-Methoden zeigen in Labortests gute Ergebnisse, aber nur wenige wurden bisher in der Produktion eingesetzt. Je mehr Anwendungsfälle entwickelt werden und je mehr Erfahrungen mit der XAI-Forschung und -Entwicklung gesammelt werden, desto mehr ist zu erwarten, dass XAI ein Standardbestandteil bei der Entwicklung und dem Einsatz komplexerer KI-Modelle sein wird. Wir werden hier den Stand der Technik der XAI-Methoden und ihre potenziellen Anwendungen untersuchen.
Wir werden uns hauptsächlich auf ein Bildklassifizierungsproblem konzentrieren, bei dem jedes Bild zu einer Klasse gehört. Ziel ist es, durch überwachtes Training ein Modell zu erstellen, das die Klassenzugehörigkeit von neuen, ungesehenen Daten vorhersagt. Die Bildklassifizierung erfolgt in der Regel mit tiefen neuronalen Netzen. Tiefe neuronale Netze verwenden mehrere Schichten, um schrittweise Merkmale aus den Rohdaten zu lernen. Bei dieser Art von Klassifizierungsproblemen lässt sich die erklärbare KI grob in drei verschiedene Kategorien einteilen (Abbildung 3):
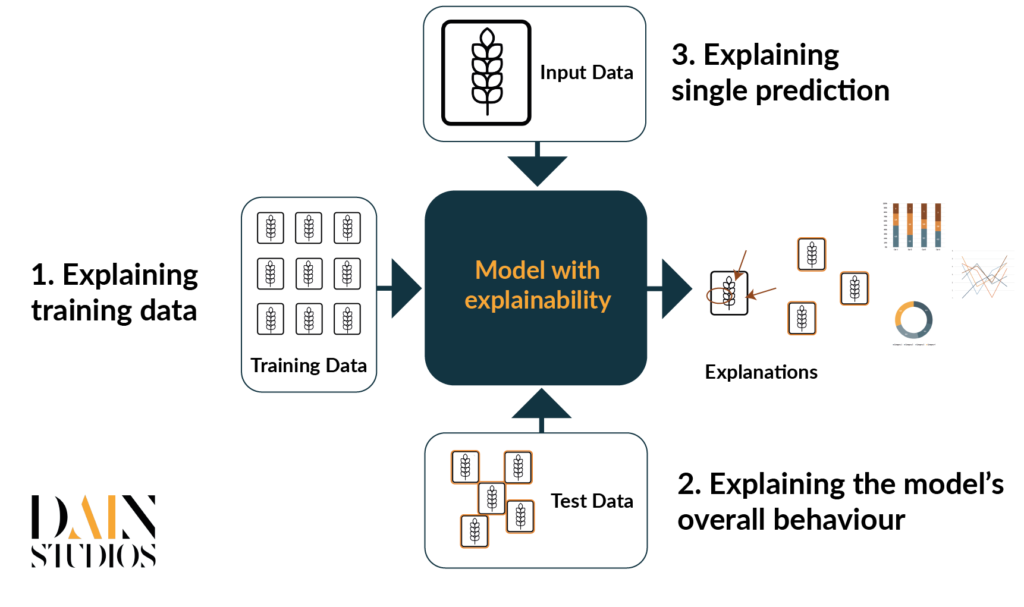
- Beim überwachten Lernen wird das Modell mit voretikettierten Daten trainiert, d. h. in der Trainingsphase wird eine Reihe von Bildern in das Modell eingespeist, und das Modell optimiert seine Parameter, bis es lernt, die Bilder so korrekt wie möglich zu klassifizieren. Da die Modellparameter mit den Beispielen aus dem Trainingssatz optimiert werden, haben die Trainingsdaten einen großen Einfluss auf die Genauigkeit und Zuverlässigkeit der Modellvorhersagen. Um das Modell zu verstehen, müssen wir zunächst die zum Trainieren des Modells verwendeten Daten verstehen. Typische Fragen, die wir zu beantworten versuchen, betreffen die Qualität und Quantität der Daten und ihre Repräsentativität für das Problem, das wir zu lösen versuchen.
- Erläuterung des Gesamtverhaltens des Modells. Sobald das Modell trainiert wurde, ist es wichtig, seine Leistung sorgfältig zu bewerten. Die Berechnung der Genauigkeit in der Testreihe ist ein sehr gängiger Schritt, aber oft würden wir von einer sorgfältigeren Analyse der Modellfehler und Verzerrungen profitieren. Je besser wir das Modell verstehen, desto einfacher ist es für die Modellentwickler, die problematischen Teile zu beheben und das Gesamtmodell zu verbessern.
- Erläuterung einer einzelnen Vorhersage. Wenn das Modell getestet wird oder im Einsatz ist, gibt der Benutzer jeweils ein Bild in das System ein. Dann sagt das Modell dessen Bezeichnung voraus und berechnet die Klassifizierungsbewertung. Im Idealfall ist die Vorhersage richtig, aber selbst die besten Modelle versagen manchmal. Die Benutzer könnten zögern, der Vorhersage des Modells zu vertrauen, wenn es keine Gründe für die Vorhersage gibt. Durch die Bereitstellung von Erklärungen für jede Vorhersage wird es für die Benutzer einfacher, dem Modell zu vertrauen und zu überprüfen, ob es sich auf die richtigen Teile des Bildes konzentriert.
Im Folgenden wird jede dieser Kategorien näher betrachtet.
Erläuterung der Trainingsdaten
Training ist die Phase, in der die KI das Modell für die Klassifizierung erlernt. Die Qualität und Quantität der Trainingsdaten haben daher einen großen Einfluss auf das Modell: Gibt es nur wenige Daten und/oder ist die Datenqualität gering, sind die Lernfähigkeiten des Modells begrenzt. Außerdem kann das Modell leicht Verzerrungen aus den Trainingsdaten übernehmen. Aus diesem Grund ist es von grundlegender Bedeutung, die Trainingsdaten genau zu verstehen, um die Qualität des Modells zu ermitteln.
Wenn wir ein neues Projekt beginnen oder neue Daten erhalten, möchten wir in der Regel die Eingabedaten visuell prüfen und mögliche Verzerrungen und deren Qualität quantifizieren. Im Falle der Bildklassifizierung benötigen wir jedoch in der Regel eine große Anzahl von Bildern, um die KI zu trainieren, und eine visuelle Inspektion aller Bilder ist keine mögliche Vorgehensweise. Stattdessen könnten wir eine Teilmenge von Bildern zufällig auswählen. Dies würde jedoch die Charakterisierung des Eingabematerials von der gewählten Teilmenge abhängig machen. Im Allgemeinen deckt eine Zufallsmenge nicht notwendigerweise den gesamten Datenraum ab, wenn die Daten stark variieren und wir nicht sicher sein können, welche Fälle für bestimmte Klassen typisch sind und welche seltene Fälle darstellen.
Aus diesem Grund wurde das Konzept der "Prototypen" und "Kritikpunkte" entwickelt. Die Idee hinter den Prototypen ist, dass ein kleinerer Datensatz den gesamten Datenraum ausreichend abdeckt. Anhand der Prototyp-Bilder kann man leicht erkennen, welche Art von Bildern in den Daten vorhanden ist. Allerdings sind die Prototypen oft nicht ausreichend, da es auch Ausreißer geben kann, d. h. Bilder, die mit den Prototypbildern nicht gut erfasst werden. Modellkritische Beispiele stellen diese seltenen Fälle dar und helfen dem Datenwissenschaftler zusammen mit den Prototypbildern, ein mentales Modell des Datenraums zu erstellen. In Abbildung 2 sind einige Beispiele für Prototypen und Kritiken für handgeschriebene Zahlen dargestellt, die mit einer statistischen MMD-Kritikmethode ausgewählt wurden.

Erläuterung des Gesamtverhaltens des Modells
Die Genauigkeit ist ein wichtiges Kriterium für die Einstufung verschiedener Modelle. Die Genauigkeit sagt jedoch nichts darüber aus, wo die Problembereiche liegen: Einige Fehler sind gravierender als andere. Daher hilft ein sorgfältiges Testen des Modells mit statistischen Methoden dabei, zu verstehen, wo das Modell funktioniert und wo es versagt. Das Testen erhöht das Vertrauen in das Modell. Wichtige Fragen sind: "Wie oft macht das Modell Fehler?" "In welchen Situationen ist das Modell wahrscheinlich richtig/falsch?" und "Gibt es unerwünschte Verzerrungen in dem Modell?"
Darüber hinaus sind Beispiele eine gute Möglichkeit, das Modell zu verstehen. Eine Methode, die als "adversarial prototypes and criticism" bezeichnet wird, wählt Beispiele aus, die typisch und untypisch für eine bestimmte Klasse sind, und zwar nicht nur als allgemeine Beispiele für die Klasse (wie oben beschrieben), sondern insbesondere aus der Sicht des Modells. Die Idee dahinter ist ähnlich wie bei gegnerischen Angriffen: Ändern Sie die Bilder ein wenig, so dass Sie versuchen, das Modell dazu zu bringen, seine Vorhersage zu ändern. Wenn das Modell seine Vorhersage schon nach wenigen Änderungen des Bildes umkehrt, wird das Bild als schwach in dieser Klasse eingestuft. Ähnlich verhält es sich, wenn sich die vorhergesagte Klasse nach mehreren kleinen Änderungen des Eingabebildes nicht ändert, dann gilt es als starkes Beispiel für diese Klasse. In Abbildung 3 sehen Sie Beispiele für diese Methode anhand der Klasse "Banane". Die oberste Reihe enthält Beispiele für starke Fälle von Bananen gemäß dem Modell, d. h. Prototypen. Die untere Reihe stellt schwache Fälle von Bananen dar, d. h. Kritikpunkte.

Erklärung einer einzelnen Vorhersage
Sobald ein Modell für den Testeinsatz oder für die Produktion bereit ist, ist es hilfreich zu verstehen, warum das Modell eine bestimmte Vorhersage macht. Dieser Anwendungsfall der "Einzelvorhersage" ist wichtig, um zu überprüfen, ob das Modell korrekt funktioniert, aber auch um bei den Nutzern des Systems Vertrauen in die Vorhersage zu schaffen. Vor allem, wenn man mit der Vorhersage nicht einverstanden ist, wäre es hilfreich, wenn der Nutzer weitere Daten angeben könnte, die erklären, warum die KI die Vorhersage getroffen hat. Mit diesen zusätzlichen Informationen kann der Nutzer Details bemerken, die er übersehen hat, die aber von der KI erkannt werden konnten.
Bei Bilddaten besteht eine gängige Methode zur Erläuterung der Vorhersage darin, die Pixel hervorzuheben, die den größten Einfluss auf die Modellvorhersage haben, sowie die Pixel, die der gegebenen Vorhersage meist entgegengesetzt sind. Ein Beispiel für eine einzelne Vorhersage ist das System "Naama", das bereits beschrieben wurde(Wie man künstliche Intelligenz transparenter macht): Die Erklärungen heben die Bereiche des Gesichts hervor, die für die Erkennung der Stimmung der Person am wichtigsten waren.
Aber die pixelbasierte Erklärungsmethode, die in "Naama" verwendet wurde, war nur eine Methode unter vielen anderen. Es gibt Dutzende von Methoden, die alle unterschiedliche Vor- und Nachteile haben. Die Art und Weise, wie die XAI-Schicht die Erklärung vornimmt, hängt vom Anwendungsfall und den verwendeten Daten ab.
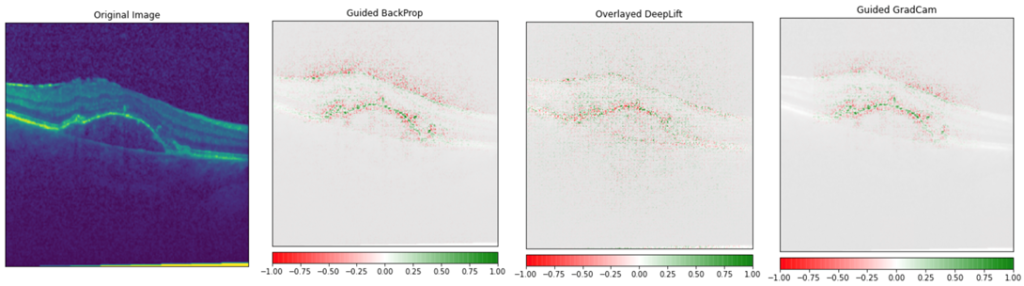
Die folgende Abbildung zeigt einen Vergleich der XAI-Methoden anhand eines medizinischen Bildes als Eingangsbild. Es ist erwähnenswert, dass bei medizinischen Bildern die Details, die das KI-Modell erkennen sollte, oft so klein sind, dass einige dieser Methoden nicht in Frage kommen, weil ihr Ergebnis für diesen Zweck zu vage ist (aber sie könnten gut sein, um die Vorhersage "Katze" aus dem Bild zu erklären).
Das obige Bild ist für uns sehr interessant, da wir denselben Datensatz verwenden, um unsere eigene XAI-Demo zu erstellen. Der Datensatz besteht aus OCT-Bildern (Optische Kohärenztoleranz) von Netzhäuten lebender Patienten, und jedes Bild gehört zu einer der vier Klassen: normal, CNV, DME und DRUSEN. Die drei letztgenannten Klassen sind Krankheiten, die die häufigsten Ursachen für Blindheit darstellen. Der Datensatz ist quelloffen, enthält eine große Anzahl von Beispielen (insgesamt etwa 84 000 Bilder) und die Bilder wurden zwischen 2013 und 2017 in verschiedenen Kliniken weltweit gesammelt. Bevor wir xAI-Methoden auf die Bilder angewandt haben, haben wir ein Modell trainiert, das die Bezeichnung des Bildes vorhersagt. Bei der Bewertung der Leistung des Modells mit ungesehenen Bildern konnten wir sehr gute Genauigkeiten im Testsatz erzielen.
Um mit den verschiedenen Arten von pixelbasierten Erklärungen zu experimentieren, haben wir ein Paket namens Captum gefunden. Es ist ein sehr einfach zu verwendendes Paket und enthält mehrere verschiedene pixelbasierte Erklärungen. In dem oben gezeigten XAI-Beispiel für medizinische Bilder haben wir einige der leistungsfähigsten Methoden für unsere Tests ausgewählt. In der Abbildung unten zeigen wir unsere Modellerklärungen mit den drei besten Methoden, die wir gefunden haben. Anhand der Erklärungen können wir sehen, dass unser trainiertes Modell die feinen Details des Netzhautbildes erkennen kann, die für die Vorhersage erforderlich sind.
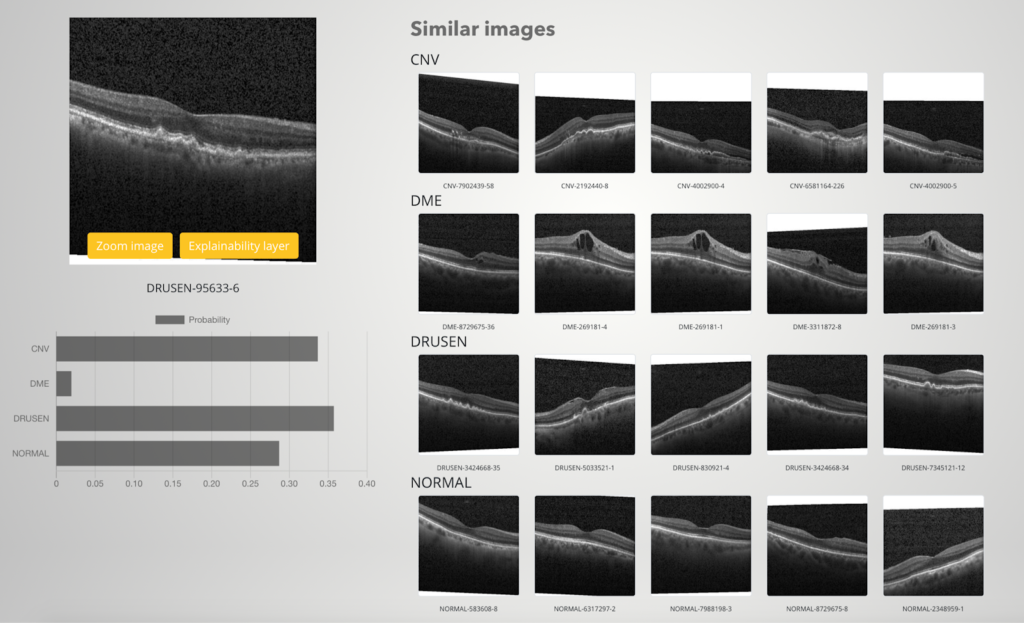
Neben pixelbasierten Erklärungen wollten wir auch einige andere einzelne Vorhersagemethoden in unsere XAI-Demo implementieren. Wir sind besonders daran interessiert, einige Beispiele für die Klassen zu zeigen, die das Modell vorhergesagt hat. Aber wir wollen nicht einfach ein paar zufällige Beispiele ausgeben, die der Benutzer mit dem Suchbild vergleichen kann. Stattdessen hoffen wir, möglichst ähnliche Beispiele wie das Abfragebild zu finden. Hierfür verwenden wir "Bildeinbettungen": Wir wählen eine der letzten Schichten des neuronalen Netzes und berechnen die Berechnungen bis zu dieser Schicht. Das Gleiche machen wir für jedes Bild des Trainingssatzes, um einen Datenpool zu erstellen, mit dem wir unsere Suchbilder vergleichen. Der Grundgedanke ist, dass ähnliche Bilder auch ähnliche Bildeinbettungen haben sollten.
Nachfolgend zeigen wir ein Beispielergebnis dieser Methode aus unserer XAI-Demo. Beachten Sie, dass wir absichtlich ein Bild ausgewählt haben, bei dem sich das Modell nicht sicher war: Die Vorhersageergebnisse für die drei Top-Klassen liegen ziemlich nahe beieinander, so dass der Benutzer entscheiden muss, ob er dem Ergebnis vertraut oder nicht. Und wie aus den ähnlichen Beispielen ersichtlich, ist es nicht so einfach, dieses Bild zuzuordnen, da ähnliche Bildtypen in drei verschiedenen Klassen zu finden sind.