Ist Ihnen die wachsende Zahl von Stellenangeboten aufgefallen, bei denen das Wort "Daten" vorangestellt wird? Im Jahr 2012 wurde die Berufsbezeichnung "Datenwissenschaftler" von der Harvard Business Review als "sexiest job of the 21st century" bezeichnet. Jahrhunderts" bezeichnet. Seitdem wurden, wie richtig vorhergesagt, zahlreiche Ableger und neue Berufsbezeichnungen mit dem Wort "Daten" propagiert, und der Ehrgeiz, ein unbezahlbares "Data-Science-Einhorn" zu werden, geht einher mit dem anhaltenden Talentkrieg und der Fresswut von Unternehmen und Headhuntern, die verzweifelt versuchen, eines zu entdecken und zu fangen.
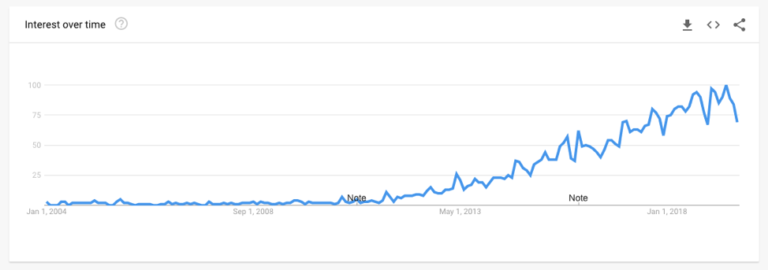
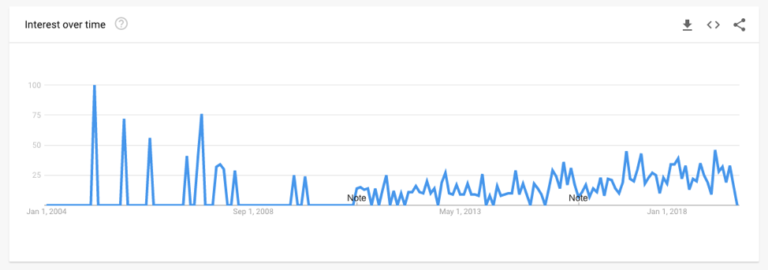
Da Einhörner im Bereich der Datenwissenschaft sehr selten und unbezahlbar zu sein scheinen, suchen Unternehmen das gleiche Fachwissen oder die gleichen Fähigkeiten bei mehreren Personen.
In den Stellenbeschreibungen für Datenwissenschaftler finden sich neben den üblichen Anforderungen eines fortgeschrittenen wissenschaftlichen Abschlusses, SQL, R, Python, maschinelles Lernen usw. häufig auch die folgenden Fähigkeiten:
"die Fähigkeit, Geschäftsprobleme in analytische Lösungen und Erkenntnisse umzusetzen".
Techniker mögen über diesen Satz spotten und ihn als typisches Beispiel für nutzlosen Geschäftsjargon abtun. Es scheint so offensichtlich, dass dies für die Arbeit eines Datenwissenschaftlers wichtig ist - warum sollte man es in die Stellenbeschreibung aufnehmen? Der einfache Grund ist, dass es sich um eine echte Fähigkeit handelt, die zwar trainiert und entwickelt werden kann, aber seltener ist, als man denkt. Wie viele promovierte Datenwissenschaftler haben einen Abschluss in Betriebswirtschaft? Es gibt ein paar, aber auch das ist nicht üblich.
Die obige Definition stellt in Wirklichkeit die Hauptkompetenz eines Datenstrategen dar. Um zu veranschaulichen, was dies in der Praxis bedeutet, betrachten wir ein Beispiel aus dem E-Commerce:
Kunde: Können Sie uns helfen, unsere Kunden besser zu verstehen?
Die Antwort auf diese Frage kann knifflig sein und erfordert viel Erfahrung und Vertrauen. Schauen wir mal, was oft folgt:
Datenwissenschaftler: Sie können einfach ein neuronales Netzwerk auf AWS bereitstellen, um einen Klassifikator für die verschiedenen Benutzergruppen zu trainieren.
Kunde: Ähm, okay. Aber welche Art von Daten brauchen wir dafür?
Datenwissenschaftler: Ein etikettierter Datensatz mit mehreren tausend Beobachtungen - natürlich in ausgeglichenen Klassen.
Klient: "Ich habe keine Ahnung.
Von all den Wörtern in diesen Sätzen sind nur wenige für einen Manager verständlich, der hofft, seine Kunden einfach zu verstehen. Der Rest könnte genauso gut eine obskure Fremdsprache sein. Dieses vereinfachte Beispiel veranschaulicht das Problem und verdeutlicht die Notwendigkeit von Übersetzungsfunktionen. Der Datenwissenschaftler hat Begriffe verwendet, die Personen mit fortgeschrittenen wissenschaftlichen Abschlüssen vielleicht verstehen, die aber für die meisten Manager und Geschäftsleute, denen sie direkt unterstellt sind, unverständlich sind.
Rufen wir einen Datenstrategen an, um zu sehen, wie sie abschneiden:
Kunde: Können Sie uns helfen, unsere Kunden besser zu verstehen?
Datenstratege: OK, schauen wir mal. Welche Art von Daten haben Sie bereits, wenn überhaupt?
Kunde: Wir verfügen über Google-Analytics-Daten, Daten zum Nutzerverhalten und zu Käufen auf unserer Website, Daten zu Produktbewertungen und Kommentaren in einer Datenbank sowie Daten zu sozialen Medien.[1]
Daten-Stratege: Auf der Grundlage dieser Datensätze können wir versuchen, die Frage auf verschiedene Weise zu beantworten. Zum einen können wir die Verhaltensdaten nehmen und eine Stimmungsanalyse durchführen - wie die Kunden über Ihre spezifischen Produkte denken. Das ist gut, denn Teile dieses Projekts können zur Analyse der Textdaten der Produktbewertungen verwendet werden. Wir können hier noch einen Schritt weiter gehen und sehen, ob es einige Muster gibt - vielleicht Gruppen von verschiedenen Nutzern. Anhand solcher Modelle können wir erkennen, ob es gemeinsame Muster im Kundenfeedback gibt, und negatives Feedback automatisch kennzeichnen und an die Supportmitarbeiter weiterleiten. Die Wahrscheinlichkeit, dass dies funktioniert, ist groß. Ich würde sagen, dass wir mit 80 %iger Sicherheit relevante Ergebnisse erhalten werden.
Kunde: Oh, das klingt interessant. Was können wir sonst noch tun?
Daten-Stratege: Wenn wir einen guten Datensatz über die Kunden haben, können wir versuchen, ihre Abwanderungswahrscheinlichkeit vorherzusagen, oder anders gesagt, die Wahrscheinlichkeit, dass sie ihren Anbieter verlassen. Diese Vorhersagen können wir dann nutzen, um Nutzer, bei denen eine Abwanderung wahrscheinlich ist, mit speziellen Angeboten anzusprechen, die sie auf unserer Plattform halten können. Dies kann etwas schwieriger sein und hängt stark von der Datenmenge ab, die Ihnen zur Verfügung steht - ich würde sagen, die Wahrscheinlichkeit, dass es funktioniert, liegt bei 50 %, und es könnte mehr Arbeit, Fachwissen und Domänenkenntnisse erfordern, um ein Abwanderungsmodell zu erstellen.
Können Sie erraten, welche von beiden eine größere Auswirkung auf das Geschäft haben würde?
Hier sind die Punkte, die den Unterschied ausmachen:
- Der erste auffällige Unterschied zwischen den beiden Gesprächen ist, dass es sich bei letzterem um einen echten Dialog handelt. Es gibt ein Hin und Her zwischen dem Kunden und dem Datenstrategen, und es fühlt sich viel mehr wie eine Zusammenarbeit an.
- Der Datenstratege versuchte zunächst, sich ein Bild zu machen.
- Der Datenstratege verband die Arbeit sofort mit dem Unternehmensziel.
- Im zweiten Fall wurde auch über die Wiederverwendbarkeit von Code nachgedacht.
- Und schließlich lieferte der Stratege einige Metriken für den Vergleich der verschiedenen Ansätze - Bedeutung, Komplexität und Erfolgswahrscheinlichkeit.
All diese Punkte definieren die neue Rolle des Datenstrategen. Dies steht auch im Einklang mit der in letzter Zeit zunehmenden Spezialisierung und dem sich entwickelnden Reifegrad im Bereich der Datenwissenschaft. Jüngste Artikel, unter anderem bei HBR und Forbes, veranschaulichen diesen Punkt[2]. Angenommen, Sie sind davon überzeugt, dass Ihr Unternehmen oder Ihre Organisation eine solche Funktion benötigt, wie stellen Sie sie dann ein? Was sind die Merkmale, die einen guten Datenstrategen ausmachen?
In dieser Blogserie befassen wir uns mit der neu entstehenden Rolle des Datenstrategen und damit, wie wir erwarten, dass diese Rolle Geschäftseinblicke fördert und sich weiterentwickelt.