
Lassen Sie uns Stand-up-Comedy, TV-Specials, Transkripte und NLP-Techniken verwenden, um Comedians zu vergleichen. In diesem Artikel zeige ich, dass Textanalyse und -visualisierung einfach sein und Spaß machen kann und dass es mit modernen, öffentlich zugänglichen Tools jeder tun kann, auch ohne viel Programmiererfahrung.
Um diesen Artikel ein wenig unterhaltsam zu gestalten, habe ich mich für Open-Source-Daten entschieden, die amüsant zu analysieren sind. Die Idee, Stand-up-Comedy-TV-Specials, Transkripte und NLP-Techniken zu verwenden, um verschiedene Comedians zu vergleichen, wurde durch dieses Tutorial inspiriert.
Zum Zeitpunkt der Erstellung dieses Artikels (03/2020) gehörten die folgenden Stand-up-Comedy-TV-Specials zu den beliebtesten in der IMDB:
- Dave Chappelle: Stöcke & Steine
- Hannah Gadsby: Nanette
- John Mulaney: Neu in der Stadt
Vorverarbeitung
Ich scrape die Drehbücher für die oben genannten Programme von Scraps From The Loft, einem digitalen Magazin mit Filmkritiken, Stand-up-Comedy-Transkripten, Interviews usw., um sie für gemeinnützige und pädagogische Zwecke zur Verfügung zu stellen. Mit öffentlich zugänglichen Tools versuche ich zunächst, Bühnenpersönlichkeiten, Wörter, die für jeden Comedian am charakteristischsten sind, und Unterschiede in der Wortverwendung zwischen Comedians zu verstehen.
Im Vorverarbeitungsschritt lösche ich Text in Klammern, der auf Unterbrechungen durch das Publikum hinweist (z. B. "[Publikum lacht]").
data_df['transcript'] = [re.sub(r'([\(\[]).*?([\)\]])','', str(x)) for x in data_df['transcript']]
!pip install scattertext
import scattertext as st
Korporaunterschiede mit Scattertext visualisieren
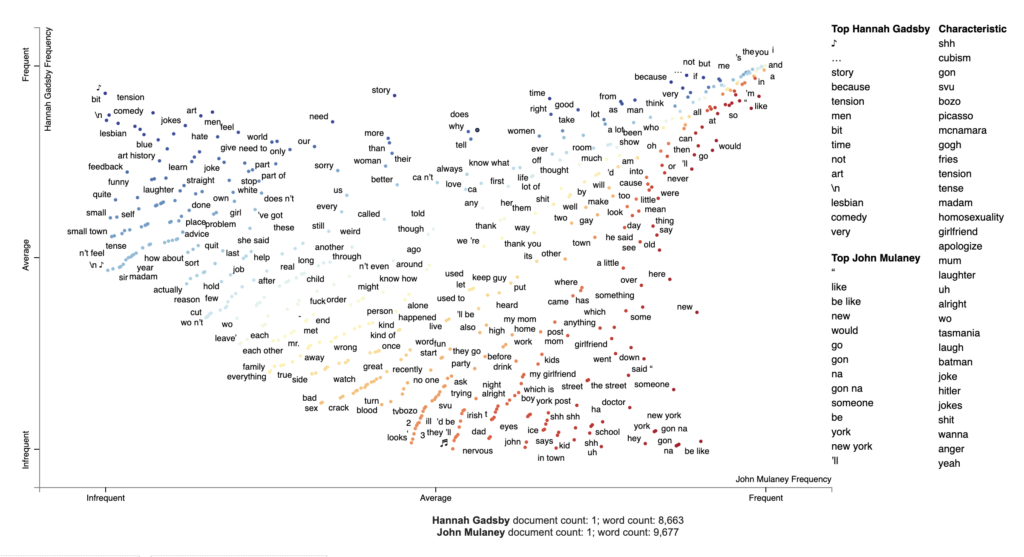
Um unsere erste Visualisierung zu generieren, führe ich die Schritte aus dem ursprünglichen Tutorial aus.
# chose the comedians to compare
pair1 = 'Hannah Gadsby', 'John Mulaney'
df_pair1 = data_df[data_df['comedian'].isin(pair1)]
# parse speech text using spaCy
nlp = spacy.load('en')
df_pair1['parsed'] = df_pair1.transcript.apply(nlp)
# convert dataframe into Scattertext corpus
corpus_pair1 = st.CorpusFromParsedDocuments(df_pair1, category_col='comedian', parsed_col='parsed').build()
# visualize term associations
html = produce_scattertext_explorer(corpus_pair1,
category='Hannah Gadsby',
category_name='Hannah Gadsby',
not_category_name='John Mulaney',
width_in_pixels=1000,
minimum_term_frequency=5
)
file_name = 'terms_pair1.html'
open(file_name, 'wb').write(html.encode('utf-8'))
IPython.display.HTML(filename=file_name)


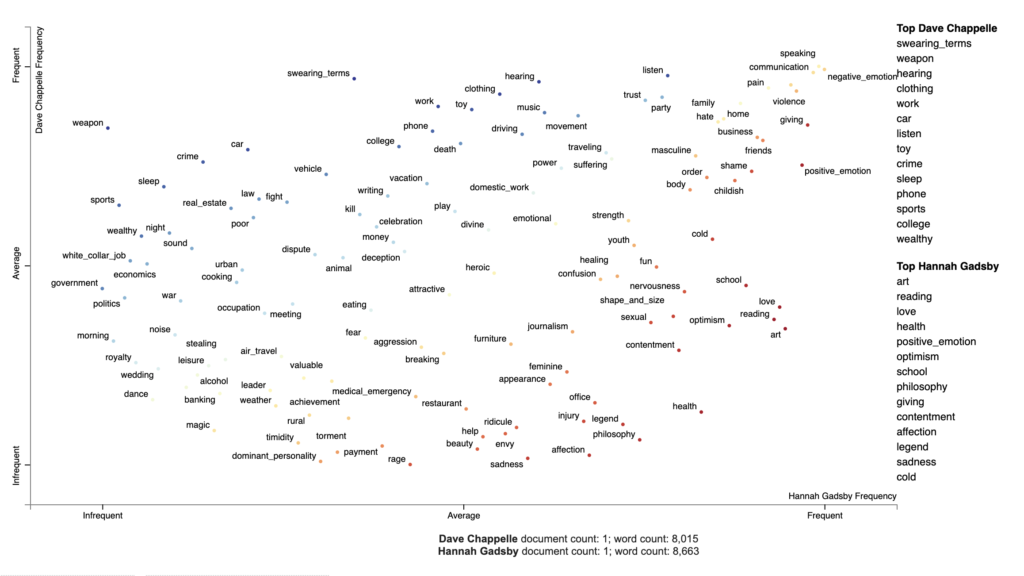
Visualisieren von Themen mit Empath
Im nächsten Beispiel verwende ich Chappelles Transkript, um Empath-Themen zu visualisieren. Empath (Fast et al., 2016) ist ein Werkzeug zur Analyse von Text über lexikalische Kategorien (oder Themen) hinweg, das auch neue Kategorien aus Text generieren kann (z. B. "bleed"- und "punch"-Begriffe erzeugen die Kategorie Gewalt). Um Empath-Themen mit Scattertext zu visualisieren, installiere ich Empath, eine Open-Source-Python-Bibliothek, und erstelle einen Korpus extrahierter Themen. Ich verwende den Quellcode, um ihn für unsere Daten anzupassen. Das Ergebnis ist in Abbildung 3 dargestellt.
!pip install empath
# chose the comedians to compare
pair2 = 'Dave Chappelle', 'Hannah Gadsby'
df_pair2 = data_df[data_df['comedian'].isin(pair2)]
# parse speech text using spaCy
nlp = spacy.load('en')
df_pair2['parsed'] = df_pair2.transcript.apply(nlp)
# create a corpus of extracted topics
feat_builder = st.FeatsFromOnlyEmpath()
empath_corpus_pair2 = st.CorpusFromParsedDocuments(df_pair2,
category_col='comedian',
feats_from_spacy_doc=feat_builder,
parsed_col='parsed').build()
# visualize Empath topics
html = produce_scattertext_explorer(empath_corpus_pair2,
category='Dave Chappelle',
category_name='Dave Chappelle',
not_category_name='Hannah Gadsby',
width_in_pixels=1000,
use_non_text_features=True,
use_full_doc=True, topic_model_term_lists=feat_builder.get_top_model_term_lists())
file_name = 'empath_pair2.html'
open(file_name, 'wb').write(html.encode('utf-8'))
IPython.display.HTML(filename=file_name)
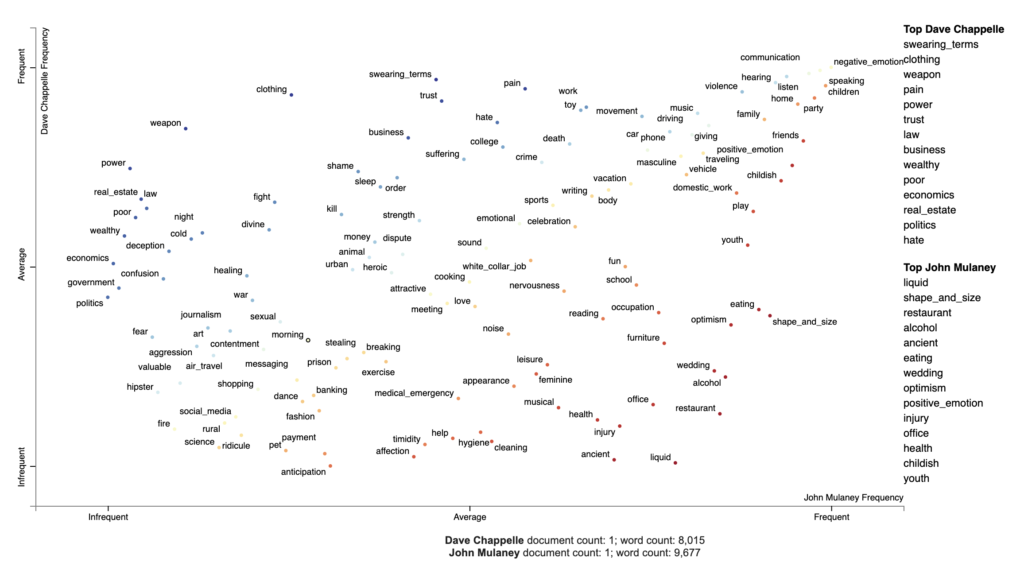
| Zugehörige Begriffe | Beispiel | |
|---|---|---|
| Chappelles Korpora | 'meinen', 'sterben', 'kümmern', 'töten', 'schlecht', 'falsch', f-ing, 'schlimm', 'tot', 'schlagen', 'allein', 'hart', 'vernunft', 'schuldig', 'verrückt' usw. | ... Wenn du arm warst, weißt du, wie sich das anfühlt. Du hast dich die ganze Zeit geschämt . Es fühlt sich an, als wäre es deine Schuld... |
| Gatsbys Korpora | 'reason', 'schlecht', 'falsch', 'enttäuscht', 'geschlagen', 'gemein', 'stop', f-ing, 'hit', 'verwirrt' usw. | ... Und ich bin wütend, und ich glaube, ich habe jedes Recht, wütend zu sein ! Aber wozu ich kein Recht habe, ist, Wut zu verbreiten... |
| Mulaneys Korpora | 'verrückt', 'wert', 'schrecklich', 'gewollt', 'lüge', 'schuld', 'getötet', 'gesucht', 'allein', 'verloren', 'dumm', 'gemein', 'schlecht', 'verwirrt', 'schuld', 'schrecklich' usw. | ... Wenn die Leute jetzt wütend auf mich sind, ist es meine Schuld, wenn die Leute auf der Autobahn wütend auf mich werden, ist das alles mein Schlechtes, ich bin ein schrecklicher Fahrer, ich habe keine Ahnung von Autos. Ich wollte etwas über Autos lernen, und dann vergaß ich es... |

Hat Ihnen diese schnelle Analyse der Textvisualisierung bei der Entscheidung geholfen, welche Stand-up-Comedy-TV-Specials Sie sich heute Abend auf Netflix ansehen sollten?
#gettingstartedwith ist unsere neue Blog-Serie für diejenigen unter Ihnen, die sich mit Daten und KI vertraut machen möchten.
Neugier ist unser Kern, und viele DAINianer experimentieren ständig mit Dingen. Wir sind es unseren Kunden schuldig, über neue Technologien auf dem Laufenden zu bleiben, und um ehrlich zu sein, da wir ein bisschen auf der nerdigen Seite sind, ist das ganz natürlich! Sich Zeit zum Lernen zu nehmen, ist auch etwas, das wir als Arbeitgeber fördern wollen, und stellen sicher, dass jede Woche etwas Zeit für den Wissensaustausch mit Kollegen reserviert ist.
Die Blogs und Beiträge, die wir mit dem #gettingstartedwith-Tag veröffentlichen, sind eher eine Einführungsebene für diejenigen unter Ihnen, die sich mit der Welt der Daten und der KI vertraut machen möchten. Dabei kann es sich um Tipps und Tricks handeln, die zeigen, wie man eine API in 60 Minuten erstellt, oder um ein lustiges Projekt zum Experimentieren mit Textanalyse. Oder wir teilen Links zu gutem Lesen oder Ansehen, verfügbarem E-Learning oder Leuten, denen man folgen kann.