Twitter-Bots und gefälschte Social-Media-Konten machten bereits 2016 Schlagzeilen, als nachgewiesen wurde, dass sie die US-Wahlergebnisse verändert haben. In diesem Jahr kämpft eine neue Gruppe von Präsidentschaftskandidaten um den Sitz im Weißen Haus. Sie nutzen Twitter auch aktiv als Kommunikationskanal. Ich fragte mich, was es braucht, um die Online-Präsenz einer Person glaubwürdig zu fälschen, und wie weit die Technologie seit der letzten Wahl bei der Erkennung der Schuldigen fortgeschritten ist. Würde maschinelles Lernen bei der Erkennung von gefälschtem Text helfen?
Textklassifikator: Echter Trump oder Twitter-Bot?
Um mit diesem lustigen Projekt zu beginnen, beschloss ich, zunächst einen Klassifikator zu erstellen, um zu versuchen, echte Trump-Tweets von Fälschungen zu unterscheiden. In den folgenden Abschnitten sehen Sie die Schritte, die ich vom Herunterladen der Daten über die Vorverarbeitung bis hin zur Klassifizierung unternommen habe.
Ich habe ein paar tausend Tweets von den folgenden Konten geladen: dem tatsächlichen Trump-Twitter (@realDonaldTrump), der Parodie Trump (@RealDonalDrumpf) und dem besten Deep-Fake-Bot-Konto, das ich finden konnte – (@DeepDrumpf).

Als nächstes habe ich Stoppwörter, zusätzliche Interpunktion, Erwähnungen und Links entfernt. Dann visualisierte ich die Sammlungen von Tweets pro Konto, um alle Merkwürdigkeiten und am häufigsten verwendeten Wörter aufzudecken. Ich habe das Retweet-Zeichen "rt" nicht entfernt, da ich festgestellt habe, dass es ein Indikator für den Twitter-Stil sein könnte. Außerdem sind die Bots möglicherweise nicht darauf trainiert, auf die gleiche Weise zu retweeten wie Donald Trump.
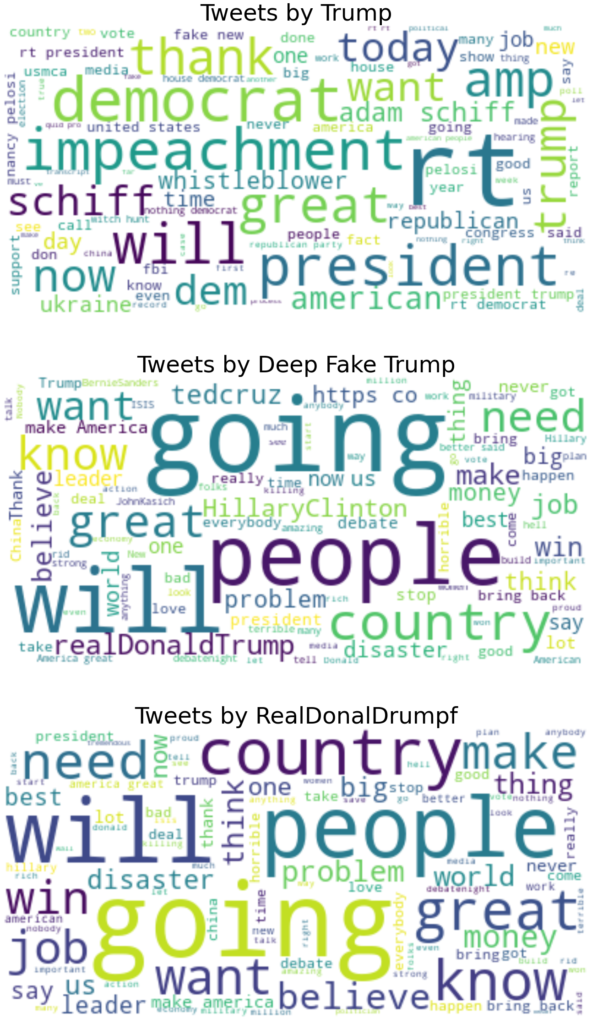
Der Unterschied zwischen dem echten Trump-Vokabular und den Fake-Text-Accounts ist ziemlich offensichtlich. Tatsächlich habe ich mir die 100 wichtigsten Wörter angesehen, die von jedem 3 Konto verwendet werden. Ich habe festgestellt, dass es keine Gemeinsamkeiten zwischen dem echten Trump und der Parodie und den Deep-Fake-Trump-Konten gibt. Die Fälschungen selbst haben jedoch einen großen Teil des Vokabulars gemeinsam. Insbesondere (und nicht sehr überraschend) sehen wir an der Spitze der Liste GREAT, COUNTRY, MAKE, AMERICA.
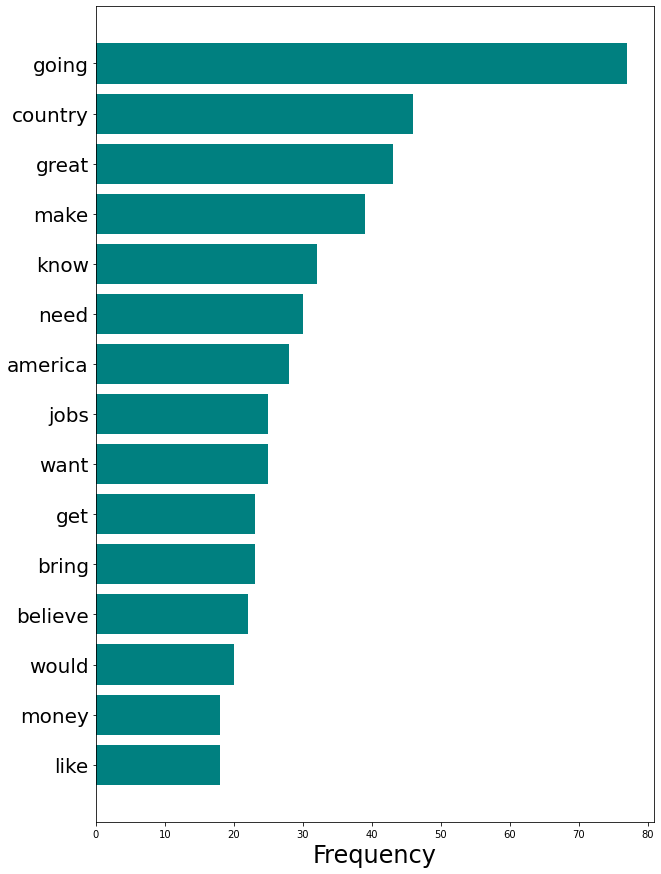
Bemerkenswert ist, dass der Deep Fake Trump-Bot im Jahr 2017 eingestellt wurde. Daher mögen seine Tweets den Stil einfangen, aber nicht das aktuelle Vokabular von Herrn Trump.
Vektorisierung und Klassifizierung von Tweet-Texten
Bevor ich mit der Klassifizierung fortfuhr, habe ich die Tweets mit spaCy tokenisiert und lemmatisiert. In der Praxis bedeutet dies, Tweets in Listen von Wortfolgen aufzuteilen und diese zu normalisieren, indem das flektierte Wort auf seine gemeinsame Basis reduziert wird. So werden z.B. "machen" und "gemacht" zu "machen" und werden als eine Wortschatzeinheit analysiert. Anschließend habe ich den resultierenden Satz von Token mit den Methoden Bag of Words (CountVectorizer in sklearn) und TF-IDF (TfidfVectorizer in sklearn) vektorisiert. Für den Klassifikator habe ich mich für LinearSVC entschieden, der bei NLP-Klassifizierungsproblemen tendenziell gut funktioniert. Hochdimensionale Textdaten und Support-Vektoren sind eine himmlische Kombination.
Für die beiden Vektorisierungsmethoden habe ich mit LinearSVC die folgenden Ergebnisse erhalten (Grafik 2):

Die Genauigkeit der Vorhersagen, ob die Tweets echten oder gefälschten Text enthalten, ist in allen 4 Fällen hoch. Es hat sich gezeigt, dass die TF-IDF-Methode etwas bessere Ergebnisse liefert als die Klassifizierung mit Bag of Words-Vektorisierung. Alles in allem ist es erleichternd, dass der Algorithmus besser zwischen dem echten und dem Bot-Account unterscheiden konnte, als zwischen den tatsächlichen Tweets des US-Präsidenten und dem von Menschen geführten Parodie-Account. Dies zeigt, dass die algorithmische Textgenerierung noch nicht perfektioniert ist. Es ist nicht so einfach, Maschinen oder Menschen zu täuschen, wenn es darum geht, die Echtheit der schriftlichen Online-Kommunikation von Personen des öffentlichen Lebens zu beurteilen.
Fazit & nächste Schritte
Maschinelles Lernen ist bei Klassifizierungsaufgaben enorm hilfreich. Wenn es jedoch um Sprache geht, scheint es, dass die Durchführung von linguistischen und Social-Media-Musteranalysen umfassendere Ergebnisse liefert als eine Black-Box-Lösung für das Problem. In meinem Prozess hätten die Unterschiede zwischen den Konten bereits bei der Analyse des Vokabulars entdeckt werden können. Andere haben sich auch nach alternativen Möglichkeiten umgesehen, einen Bot zu erkennen, wie z. B. seine Aktivität. Bots neigen dazu, zu oft und zu ganz bestimmten Zeiten zu twittern (z. B. jede volle Stunde), während Menschen etwa 10-15 Mal am Tag zu zufälligen Zeiten twittern.
Als nächsten Schritt möchte ich eine weitergehende Analyse durchführen, um zu entschlüsseln, was es bedeutet, wie Donald Trump zu twittern.
Bleiben Sie dran!