Viele Unternehmen wollen sich der digitalen Transformation stellen und Künstliche Intelligenz (KI) einsetzen. Sie haben die Ideen, die Ressourcen und eine Vision, aber es fehlen die Grundlagen. Das heißt, ein tiefes Wissen über ihre Daten, von der Verwendung und Definition von Terminologien bis hin zur Speicherung, Verwendung und Archivierung von Daten. Die meisten Anwendungsfälle für KI und Datenanalyse erfordern die Verbindung mehrerer und unterschiedlicher Datenquellen und -typen, um tiefe Einblicke und Ergebnisse zur Geschäftsoptimierung zu erhalten. Mangelndes Wissen und eine enge Sicht auf das Datenökosystem können jedoch eine Bedrohung für den Erfolg dieser Projekte darstellen.
Dieser Beitrag soll einen Überblick über die Grundsätze des Datenaudits geben, die den ersten Meilenstein für ein nachhaltiges Datenmanagement darstellen werden.
Grundsätze
Das Data Audit setzt sich aus 3 iterativen Hauptschritten zusammen: der Identifizierung von Datenbeständen, der Messung/Bewertung der Datenqualität und der Anreicherung der Daten durch qualitativ bessere Prozesse.
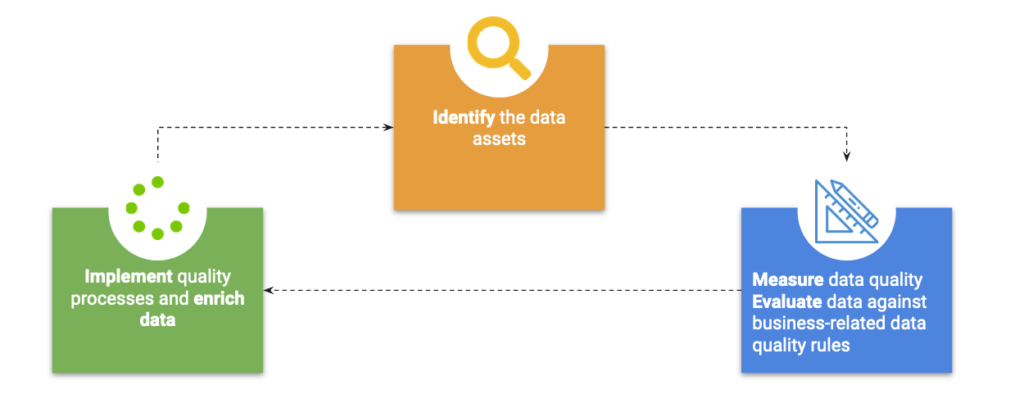
Identifizieren der Datenbestände
Das Wichtigste zuerst: Machen Sie sich mit dem Datenökosystem vertraut. Es gibt Daten und sie können auf viele verschiedene Arten beschrieben werden. Die Merkmale des Datenbestands erfordern Vorsicht bei der Definition, um vollständig verstanden zu werden. Es ist wichtig, Fragen zu stellen wie:
Wie identifiziere ich ein Datenasset? Was ist der richtige Detaillierungsgrad?
Um einen Datenbestand auf die effizienteste Weise zu identifizieren, ist es notwendig, seinen Lebenszyklus zu kennen.
Lassen Sie uns zunächst ein Datenasset definieren.
Jede Entität, die aus Daten besteht. Ein Datenobjekt kann eine System- oder Anwendungsausgabedatei, eine Datenbank, ein Dokument oder eine Webseite sein, auch ein Dienst, der bereitgestellt werden kann, um auf Daten aus einer Anwendung zuzugreifen.
Nationales Institut für Standards und Technologie – US-Handelsministerium
Jedes Datenasset hat einen Lebenszyklus: Planung, Beschaffung, Speicherung und Freigabe, Wartung, Nutzung und Entsorgung. Lassen Sie uns diese Details in den Phasen weiter untersuchen:
- Planung: Identifizieren von Zielen, Planen der Informationsarchitektur, Entwickeln von Standards und Definitionen;
- Beschaffung: Möglichkeiten zur Datenerfassung. Zum Beispiel durch das Erstellen von Datensätzen, den Kauf von Daten oder das Laden externer Dateien;
- Speicherung und Freigabe: Form der Speicherung und Weitergabe von Daten. Daten können elektronisch gespeichert werden, z. B. in Datenbanken oder Dateien. Daten können über Netzwerke, E-Mails oder APIs ausgetauscht werden.
- Wartung: Aktualisieren, Ändern und Manipulieren von Daten. Bereinigen, bearbeiten und transformieren Sie Daten. Abgleichen und Zusammenführen von Datensätzen oder Optimieren von Daten;
- Verwendung: Abrufen von Daten. Verwenden Sie Informationen. Die Verwendung kann der Abschluss einer Transaktion, das Schreiben eines Berichts, das Treffen einer Managemententscheidung auf der Grundlage eines Berichts und/oder das Ausführen automatisierter Prozesse sein.
- Entsorgung: Archivierung von Informationen oder Löschen von Daten oder Aufzeichnungen;
Für jede Phase sind vier Aspekte zu berücksichtigen:
- Was: Welche Daten sind in diesen Phasen betroffen?.
- Das Wie – Prozesse: Wie werden diese Phasen aus prozessualer Sicht durchgeführt?
- das Wer: Wer ist an diesen Phasen beteiligt?
- Das Wie – Technologie: Wie werden diese Phasen aus technologischer Sicht durchgeführt?
Dieser Rahmen bietet eine ganzheitliche Sicht auf die analysierten Datenbestände: Er wird die Grundlage für die Verbesserung des Datenbestands, die Vorstellung neuer Anwendungsfälle und die Umsetzung von Data Governance sein.
Datenqualität messen und auswerten
Nachdem das Datenobjekt identifiziert werden kann, besteht der nächste Schritt darin, festzustellen, ob die Daten verwendbar sind. Nicht alle Daten sind für die Anwendungsfälle KI und Analytik nutzbar oder relevant, daher ist es wichtig und notwendig, die Datenqualität zu bewerten. Dazu stellen wir uns folgende Fragen:
Was macht Datenqualität aus? Ist es notwendig, einen tadellosen Datenbestand zu haben?
Die Datenqualität hängt von Metriken ab, die auf Geschäftsregeln beschränkt sind. Diese Metriken sind für alle Datenbestände gleich, aber nicht für die Geschäftsregeln. Der Vergleich der beiden wird die Validierung der Datenqualität ermöglichen.
Metriken zur Datenqualität
Die Datenqualität kann mit 6 Hauptmetriken gemessen werden:
- Pünktlichkeit: Beschreiben Sie die Latenz zwischen dem Ereignis und der Verfügbarkeit der Informationen – z. B. wird der Vertragsdatensatz einmal pro Jahr aktualisiert;
- Vollständigkeit: Prozentsatz der Werte, die als vollständig angesehen werden – z. B. sind nur 80 % der Zeitstempel vollständig;
- Gültigkeit: Einhaltung einer bestimmten Syntax, eines bestimmten Bereichs oder eines bestimmten Regelwerks – z. B. muss das Alter in einigen Fällen zwischen 18 und 110 Jahren liegen;
- Eindeutigkeit: Vorhandensein von Duplikaten oder fehlenden Werten – z. B. wenn ein Unternehmen 100 Kunden bedient, sollte der Datensatz nicht mehr als 100 enthalten;
- Konsistenz: Konsistenz in der Darstellung von Daten – z. B. werden Datumsangaben immer auf die gleiche Weise kodiert;
- Genauigkeit: Genauigkeit der Daten im Vergleich zur Realität – z. B. sollte das Abrechnungssystem mit den Finanzdatensätzen übereinstimmen und konsistent sein.
Mit Ausnahme der Aktualität werden alle anderen Metriken auf der Ebene der Felder gemessen.
Geschäftsregeln
Es ist gut, die Datenqualität quantifizieren zu können, aber das Endziel besteht darin, die Zuverlässigkeit der Daten zu qualifizieren. In der Tat haben nicht alle Felder eines Datensatzes die gleiche Bedeutung: Ungenauigkeit, Unvollständigkeit und Nichtgültigkeit können für einige von ihnen akzeptiert werden.
Um diese Datenzuverlässigkeit zu qualifizieren, müssen in einem ersten Schritt geschäftsbezogene Datenqualitätsregeln definiert werden. Diese Regeln werden vom Eigentümer des Datenbestands definiert und stellen den Standard dar, anhand dessen Daten als zuverlässig eingestuft werden können. Jede Metrik, die wir zuvor gesehen haben, sollte ihre eigene Geschäftsregel haben, aber das kann in Fällen passieren, in denen es keine gibt.
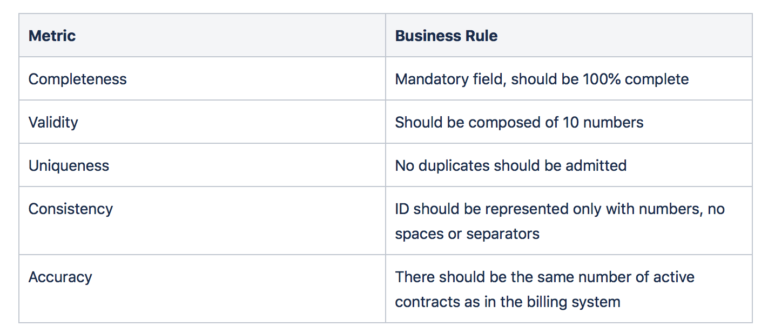
In einem Telekommunikationsunternehmen gibt es beispielsweise einen Datensatz, der alle Mobilfunkkundenverträge enthält. Einige der Felder sind Vertrags-ID und E-Mail-Adresse. Lassen Sie uns die Geschäftsregeln für beide ausarbeiten.
Die Aktualität ist für den gesamten Datensatz gleich – sie sollte täglich aktualisiert werden.
Vertrags-ID:
E-Mail-Adresse:
Der Kerngedanke dabei ist, dass nicht alle Felder den gleichen Wert haben. Für diejenigen, die im Kerngeschäft von zentraler Bedeutung sind, sollten die Geschäftsregeln streng und sorgfältig definiert sein. Für sekundäre Felder lohnt es sich jedoch möglicherweise nicht, zu viel Zeit mit der Festlegung von Regeln zu verbringen.
Evaluierung der Datenqualität
Ziel ist es hierbei, die gemessenen Metriken und die definierten Geschäftsregeln zu vergleichen. Wenn alle Metriken die Regeln einhalten, wird das Feld validiert.
Im besten Fall, dass Felder ausgewertet werden, werden alle Felder validiert und damit auch der gesamte Datenbestand. Im schlimmsten, aber einfachen Fall sind alle Felder falsch und der gesamte Datenbestand muss korrigiert werden.
Die Realität stellt in der Regel eine Mischung aus gültigen und ungültigen Feldern in der Datenqualitätsbewertung dar, wobei einige Felder konform sind und andere nicht. In diesem Fall sollten die Pflichtfelder definiert und deren Konformität für die Validierung des Datenbestands erforderlich sein. Diese Validierung sollte jedoch mit einem Hinweis darauf einhergehen, wie sich die problematischen Felder auf die aktuellen oder zukünftigen geschäftlichen Anwendungsfälle auswirken könnten (oder auch nicht).
Implementieren Sie Qualitätsprozesse und reichern Sie Daten an
Nach der Bewertung der Datenqualität werden die Probleme unterstrichen und müssen gelöst werden. Der beste Weg, diese Probleme zu lösen, besteht darin, die Grundursachen zu finden.
Glücklicherweise sind die Datenlebenszyklen problematischer Datenbestände bekannt. Daher ist es möglich, die Phase, in der das Problem auftritt, seinen technischen und/oder geschäftlichen Grund und die Personen zu lokalisieren, mit denen man sprechen kann, um es zu beheben.
Zusammenfassend lässt sich sagen, dass ein Data Audit in drei Phasen unterteilt ist. Die erste ist die Identifizierung des Datenbestands und die Untersuchung seines Lebenszyklus. Die zweite ist die Bewertung der Datenqualität. Dazu ist es notwendig, die 6 Hauptmetriken zu messen und mit den definierten Geschäftsregeln zu vergleichen. Das Ergebnis dieser beiden Phasen ist eine klare Ansicht aller problematischen Daten. Die dritte und letzte Phase besteht darin, die Ursachen dieser Probleme zu behandeln. Anhand des Datenlebenszyklus können wir herausfinden, warum und wo es ein Problem gibt und mit wem wir für eine nachhaltige Datenmanagementlösung interagieren können.