Im zweiten von vier Artikeln über Fairness in der KI sagt Paolo Fantinel, dass das Verständnis von ML-gesteuerten Entscheidungen Unternehmen und ihren Kunden helfen kann.
Immer mehr Unternehmen verlassen sich auf künstliche Intelligenz (KI) und maschinelles Lernen (ML), um Entscheidungen schneller und effizienter zu treffen oder zu treffen. Der vorherige Artikel befasste sich mit der Frage, wie Unternehmen sicherstellen können, dass eine solche automatisierte Entscheidungsfindung fair ist, und dieser befasst sich mit dem damit verbundenen Problem der "Erklärbarkeit" oder der Fähigkeit, ML-gesteuerte Entscheidungen zu verstehen, die seltsam erscheinen mögen. Es ermöglicht Unternehmen, Vorurteile, die in ihren Algorithmen lauern, zu erkennen und zu beseitigen, und hilft Menschen, die von unerwünschten Entscheidungen betroffen sind, die Situation möglicherweise zu beheben.
Nehmen wir eine Person, die als kreditwürdig eingestuft wird, aber einen Kredit abgelehnt hat. Mit Werkzeugen, die von DAIN Studios, ein ML-Modell, das den deutschen Kreditdatensatz von 1.000 Kreditantragstellern durchforstete, um ihnen gute (1) oder schlechte (0) Kredit-Scores zu geben. Eine Frau erhielt die Note 1, erhielt aber im wirklichen Leben keinen Kredit. Ein genauerer Blick zeigt, dass das Modell die Wahrscheinlichkeit, dass sie den Kredit zurückzahlt, mit 54 % berechnete, womit sie auf der richtigen Seite der 50 %-Schwelle des Modells für die Aufrundung von Scores auf 1 lag, obwohl ihr zugrunde liegender Score offensichtlich immer noch als zu riskant eingestuft wurde.

Was-wäre-wenn-Analyse
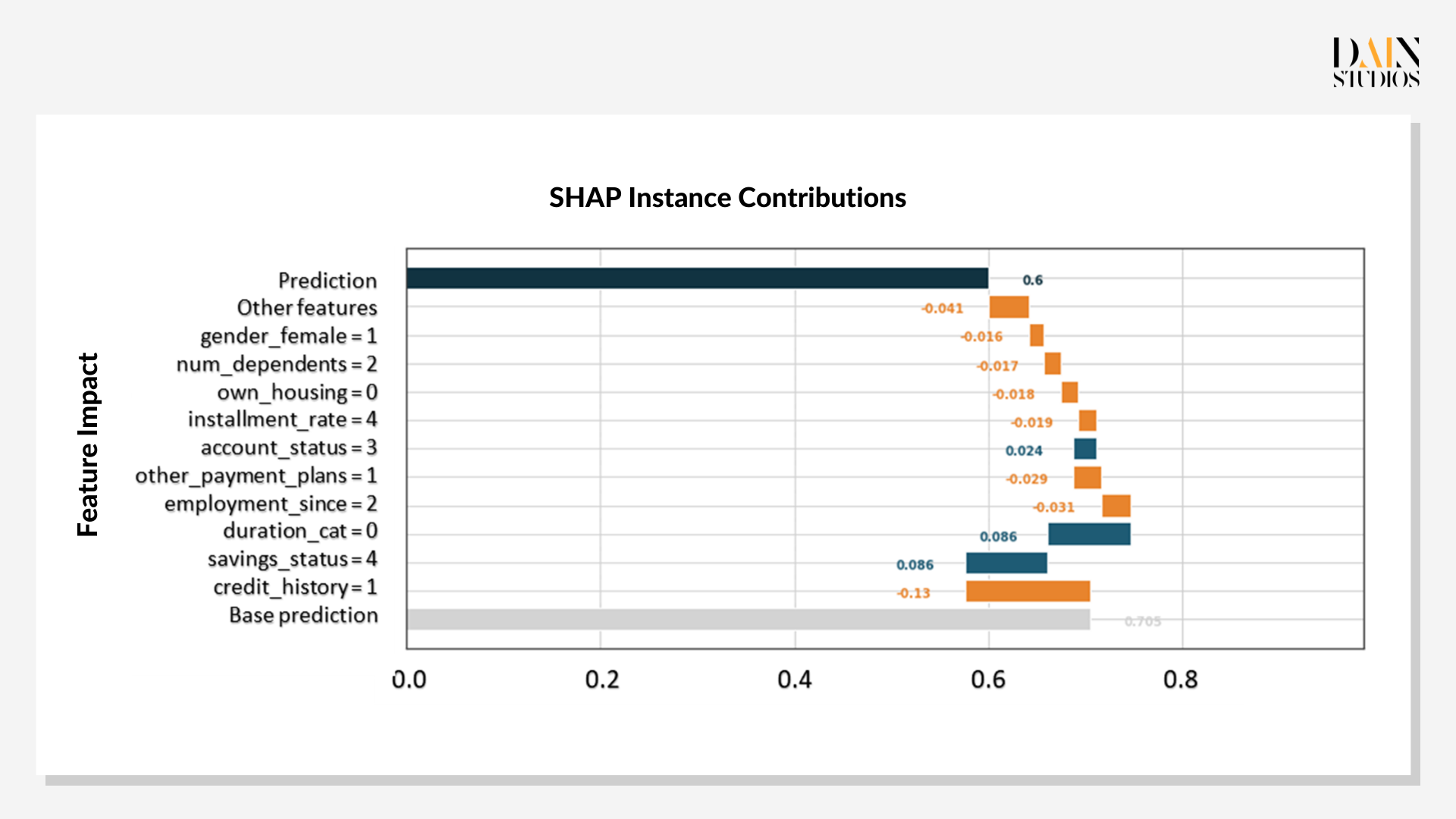
"Explainable AI" (XAI) ermöglicht es in diesem Fall der Bank oder dem Kreditantragsteller auch, zu sehen, wie das ML-Modell diese Wahrscheinlichkeit der Kreditrückzahlung berechnet hat. Die Shapley-Werte – benannt nach dem Nobelpreisträger und Pionier der Spieltheorie Lloyd Shapely – zeigen, wie die einzelnen Eigenschaften des Kreditantragstellers zum Endergebnis des Modells beigetragen haben. Jede Berechnung beginnt damit, dass dem Antragsteller eine Basisvorhersage, die durchschnittliche Vorhersage für den Datensatz, zugewiesen wird. Anschließend werden eine Reihe von Einzelmerkmalen betrachtet, die den anfänglichen Wahrscheinlichkeitswert ergänzen oder verringern.
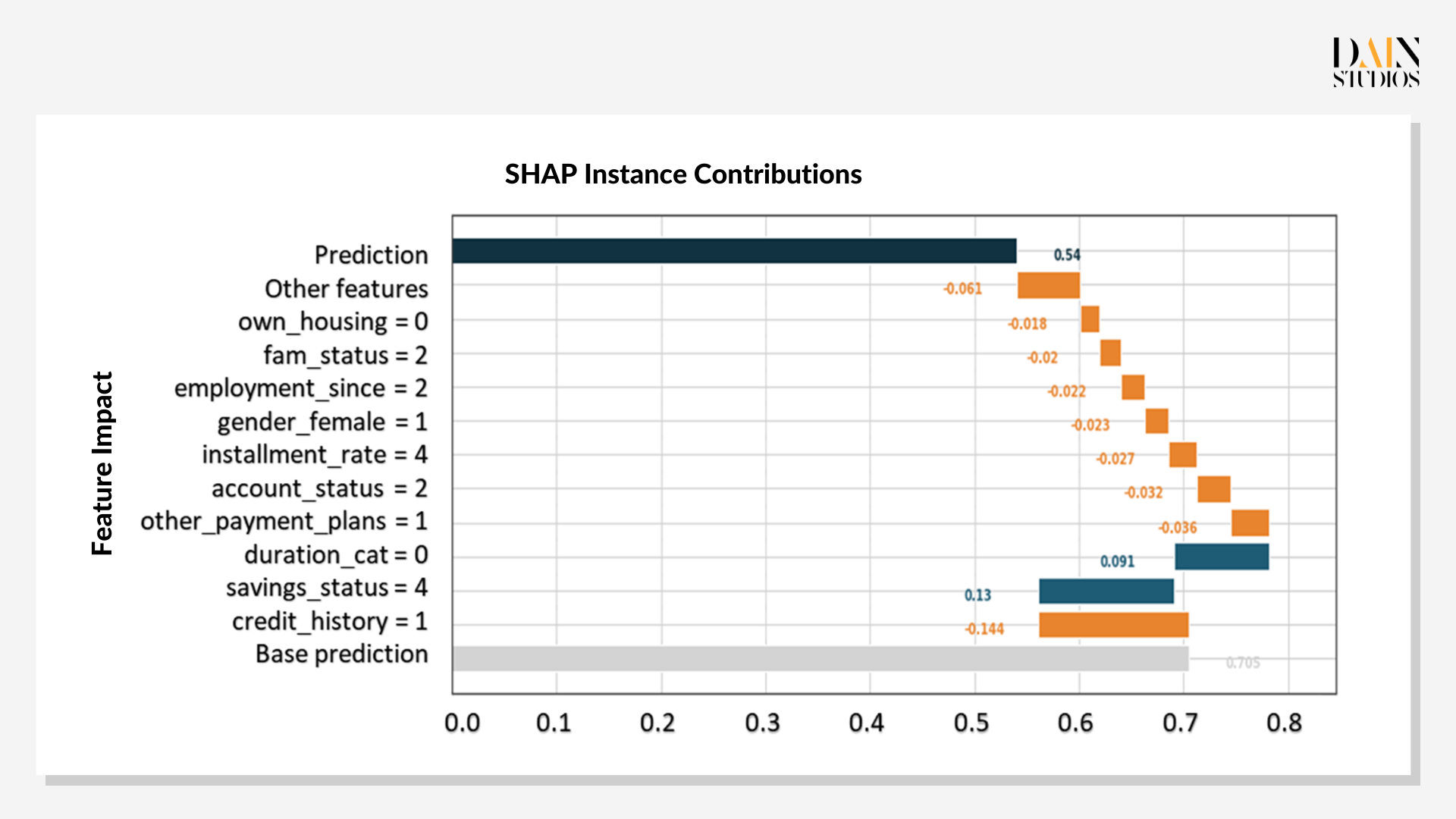
Im Fall des Kreditantrags zeigt das Diagramm blaue Balken für Merkmale, die ihre Chance auf einen Kredit verbessert haben, und orangefarbene Balken für diejenigen, die ihre Kreditwürdigkeit im Verhältnis zum grauen Balken der Basisvorhersage verringert haben. Es zeigt, dass die Kredithistorie der Antragstellerin der größte Faktor ist, der gegen einen Kredit spricht, wodurch ihre Punktzahl im Alleingang von der Basis 0,7 auf 0,56 gesenkt wird. Während ihre Ersparnisse und die Laufzeit des Darlehens diesen ersten Schlag auf ihre Kreditwürdigkeit mehr als ausgleichen würden, senken alle anderen Merkmale die Punktzahl wieder auf 0,54.
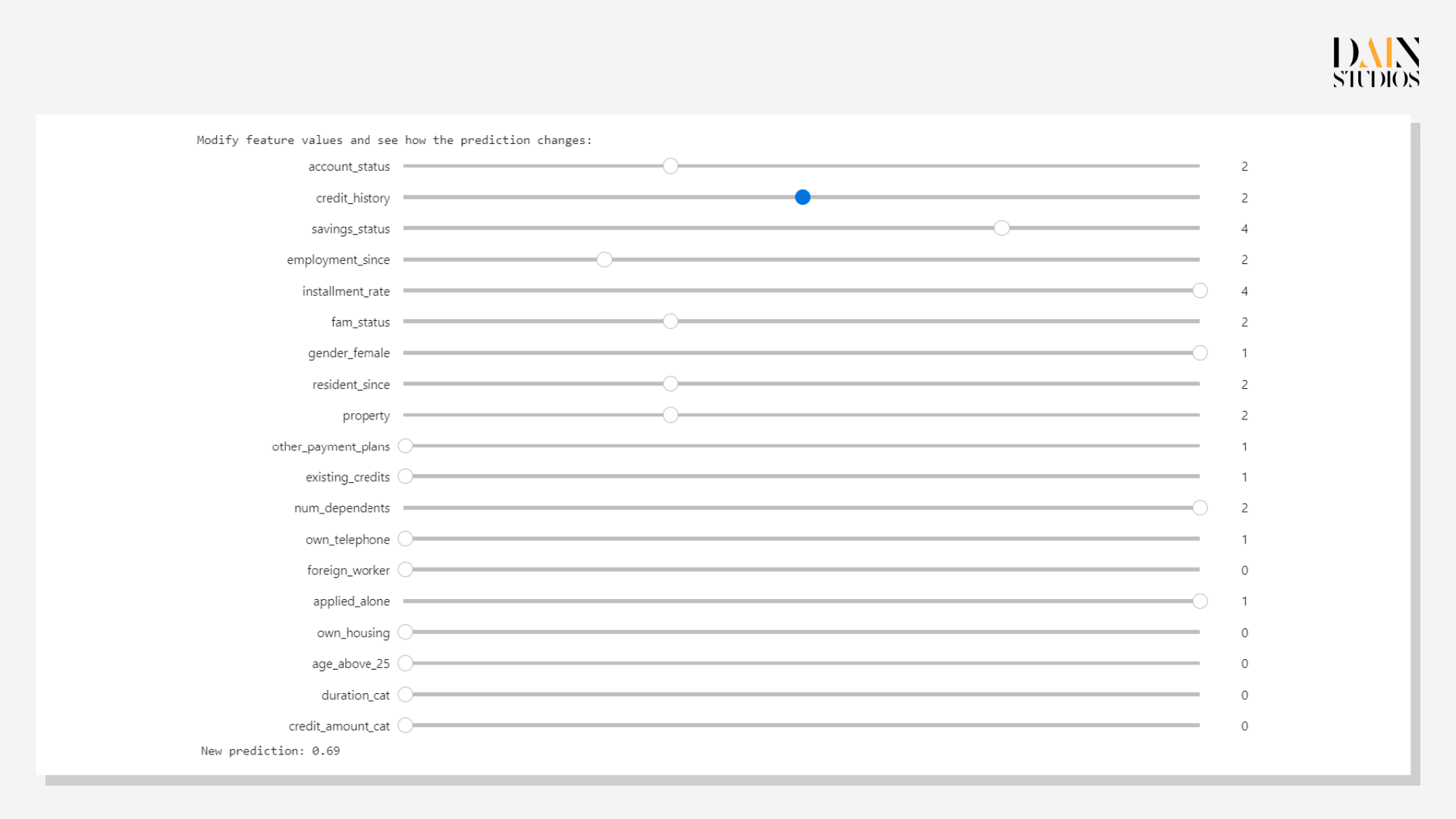
Die vielen negativen Shapley-Werte der Antragstellerin deuten darauf hin, dass die Bank sich zu Recht gegen die Gewährung eines Darlehens entschieden hat. Das Modell kann ihr aber auch in Form einer Was-wäre-wenn-Analyse helfen, die zeigt, wie Änderungen ihrer Eigenschaften die Vorhersage verändern würden. Wenn Sie ihre Kreditwürdigkeit um eine Klasse verbessern, erhöht sich die Wahrscheinlichkeit, dass sie den Kredit zurückzahlt, um 0,69. Sie könnte auch andere Faktoren leichter ändern – eine Bewerbung mit einem Partner oder Elternteil ("alleine beworben=1") oder eine Erhöhung ihres Einkommens ("Kontostand" 3 statt 2) würde ihre Chancen auf 0,6 erhöhen.
Anstelle dieses Ansatzes von Versuch und Irrtum ist es oft effizienter zu fragen, welche Faktoren am besten geändert werden sollten, um die Vorhersage des Modells umzukehren oder auf das gewünschte Niveau zu heben. In XAI werden diese als kontrafaktische Erklärungen bezeichnet, da sie berücksichtigen, was das Ergebnis gewesen wäre, wenn die Fakten anders gewesen wären. Die einfachste Methode besteht darin, nach Prototypen oder anderen Instanzen in den Daten zu suchen, die dem untersuchten Fall ähneln, sich aber im Ergebnis unterscheiden – die andere nutzt einen genetischen Algorithmus, um Datenpunkte und Ergebnisse auf der Grundlage dieses Falles zu generieren.
Kontrafaktische Erklärungen
Prototypen kontrafaktischer Daten sind nützlich, wenn sie mit Fairness-Problemen konfrontiert werden. Dieser Antragsteller hat keinen Kredit erhalten, aber gibt es einen mit ähnlichen Merkmalen, der einen Kredit erhalten hat? Wenn ja, welche Eigenschaften hatte die andere Person, die die erste nicht hatte? Es stellt sich heraus, dass es zwei Instanzen in unserem Datensatz gibt, die sehr ähnliche Merkmale wie unser Kreditantragsteller aufweisen – außer dass in diesen Fällen Kredite vergeben wurden. Der Vergleich mit dem untersuchten Fall gibt Aufschluss darüber, ob die Entscheidungskriterien sinnvoll sind. Die Shapley-Werte zeigen, dass die Kredithistorie der wichtigste Faktor ist.
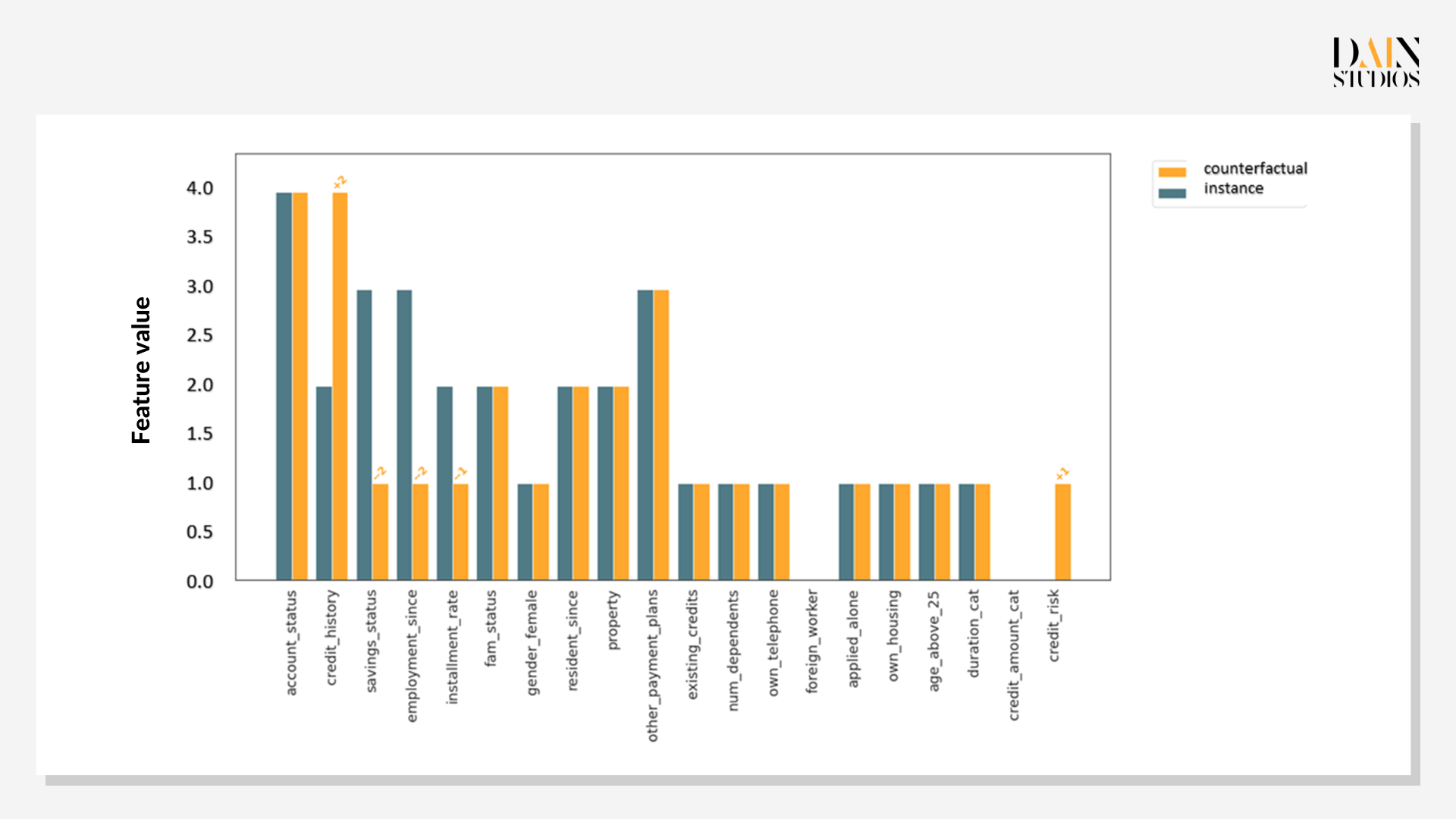
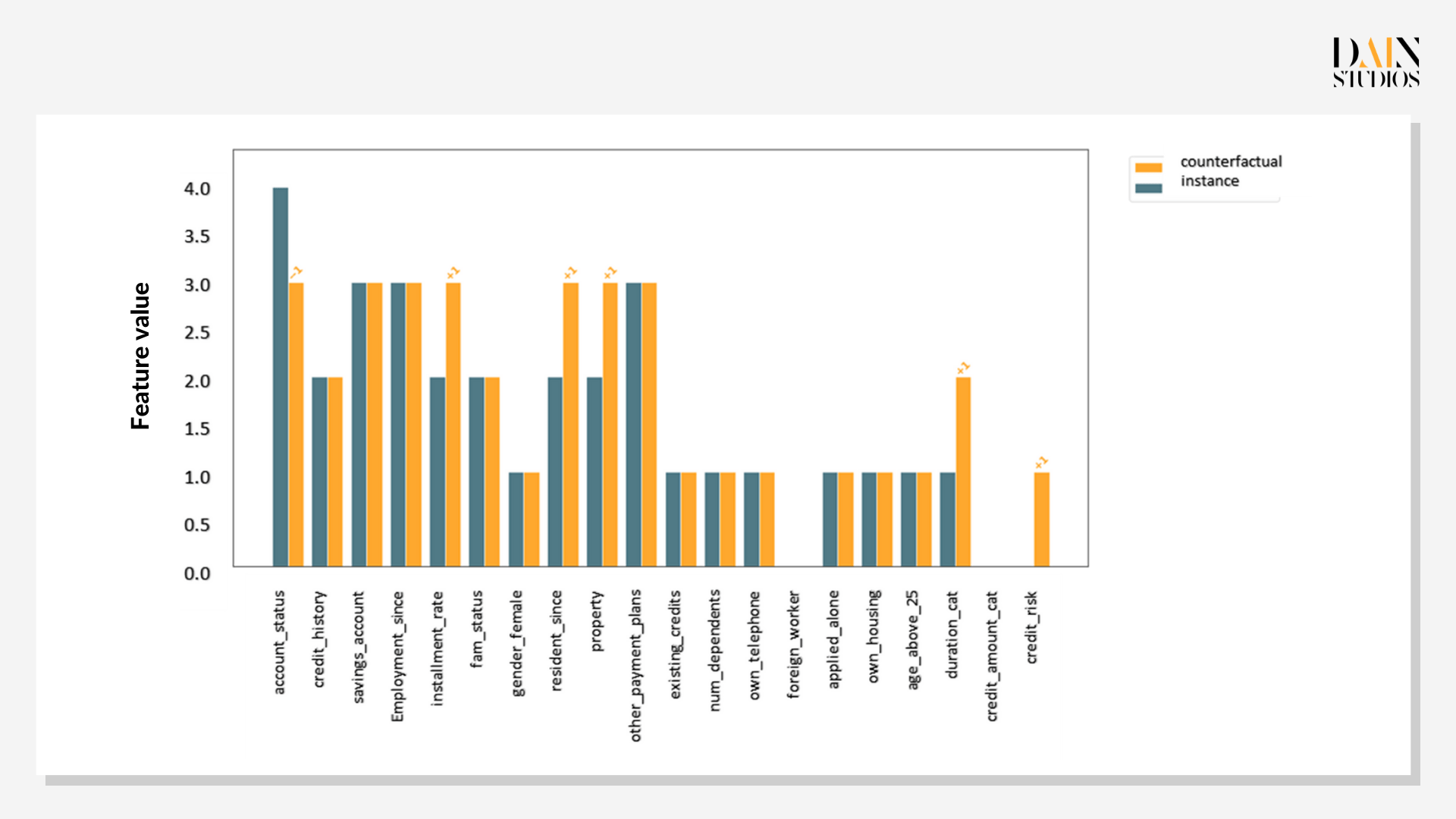
Genetische Kontrafaktik
Wenn kein kontrafaktischer Prototyp gefunden werden kann, wählt XAI den genetischen Ansatz. Mit Hilfe von Mutation, Crossover und anderen aus der Biologie bekannten Methoden generiert es synthetische Daten und berechnet Ergebnisse. Es beruht auf der gleichzeitigen Optimierung mehrerer Funktionen, die die Ergebnisse, die sich aus der Vorhersage synthetischer Daten ergeben, einschränken. Dadurch wird sichergestellt, dass die generierten Daten der ursprünglichen Instanz ähneln, innerhalb ihrer Datenverteilung liegen, sich so wenig wie möglich in den Merkmalen unterscheiden und einen vorhergesagten Wert erzeugen, der in einem gewünschten Bereich nahe am ursprünglichen Wert liegt.
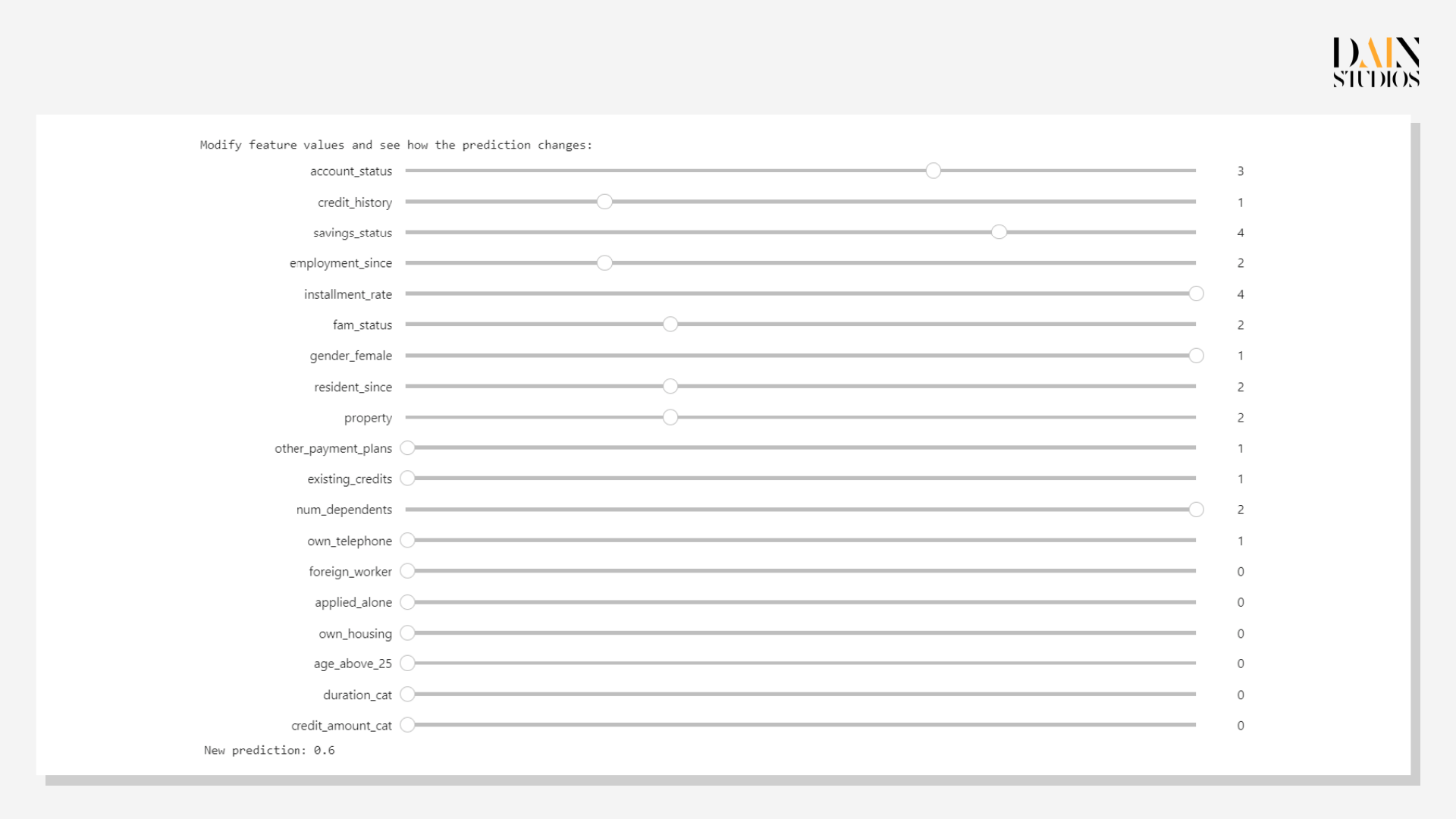
Das erste genetische Kontrafaktische für die untersuchte Kundin zeigt, dass eine Verbesserung ihrer Kredithistorie um eine Klasse die Wahrscheinlichkeit, dass sie einen Kredit erhält, auf 0,7 erhöhen würde. Aber wie bereits gezeigt, ist die Kredithistorie nicht alles. Das zweite kontrafaktische Szenario zeigt, dass mehr Ersparnisse, eine längere Erwerbstätigkeit und die Versorgung mit weniger Mitarbeitern ihre Chancen auf 0,6 erhöhen würden. Während sich die Kredithistorie nur langsam ändert, konnte die Antragstellerin innerhalb eines Jahres ihre Ersparnisse aufbauen und sich um eine Person weniger kümmern, was ihre Chancen auf einen Kredit verbesserte.
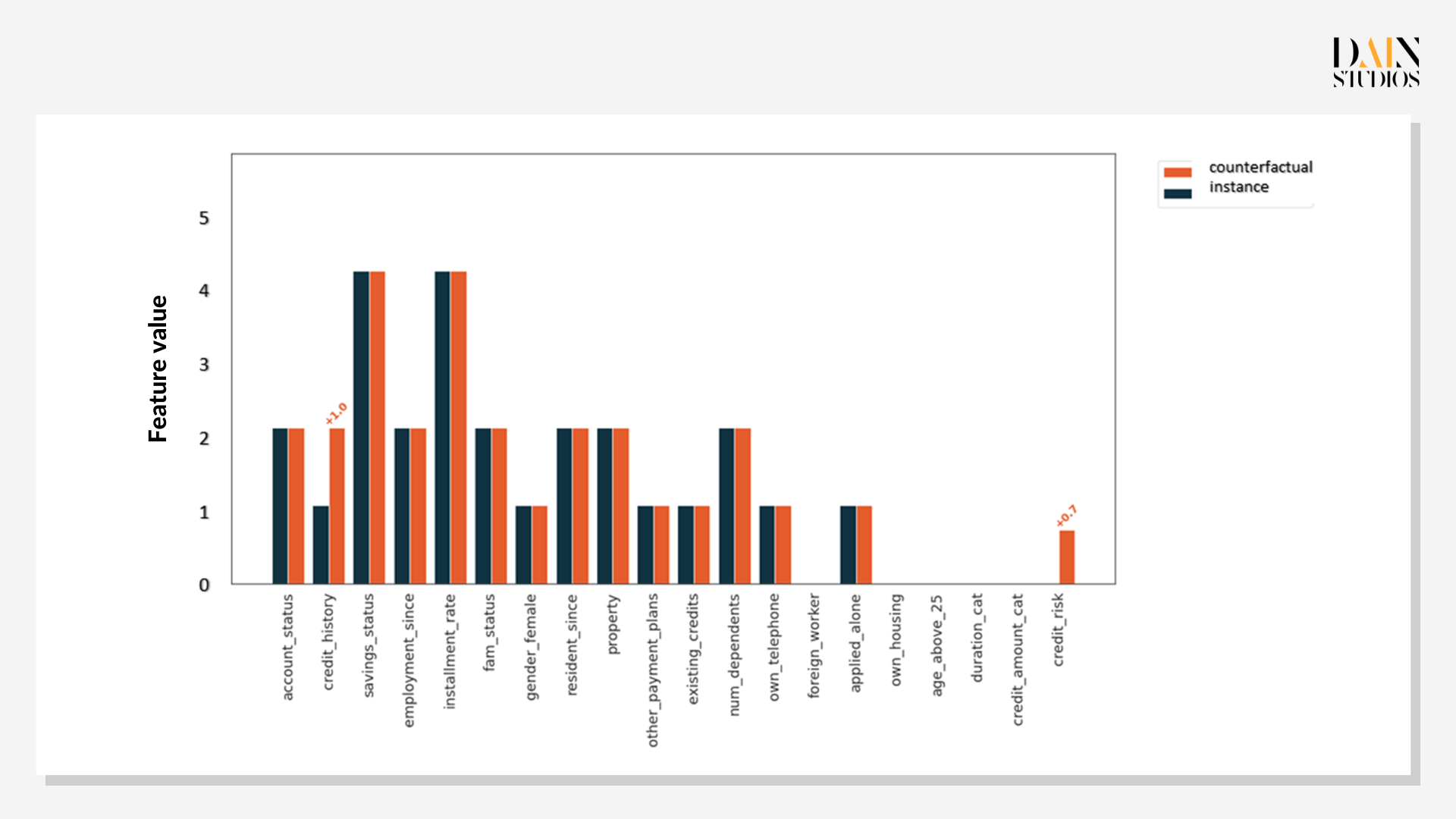

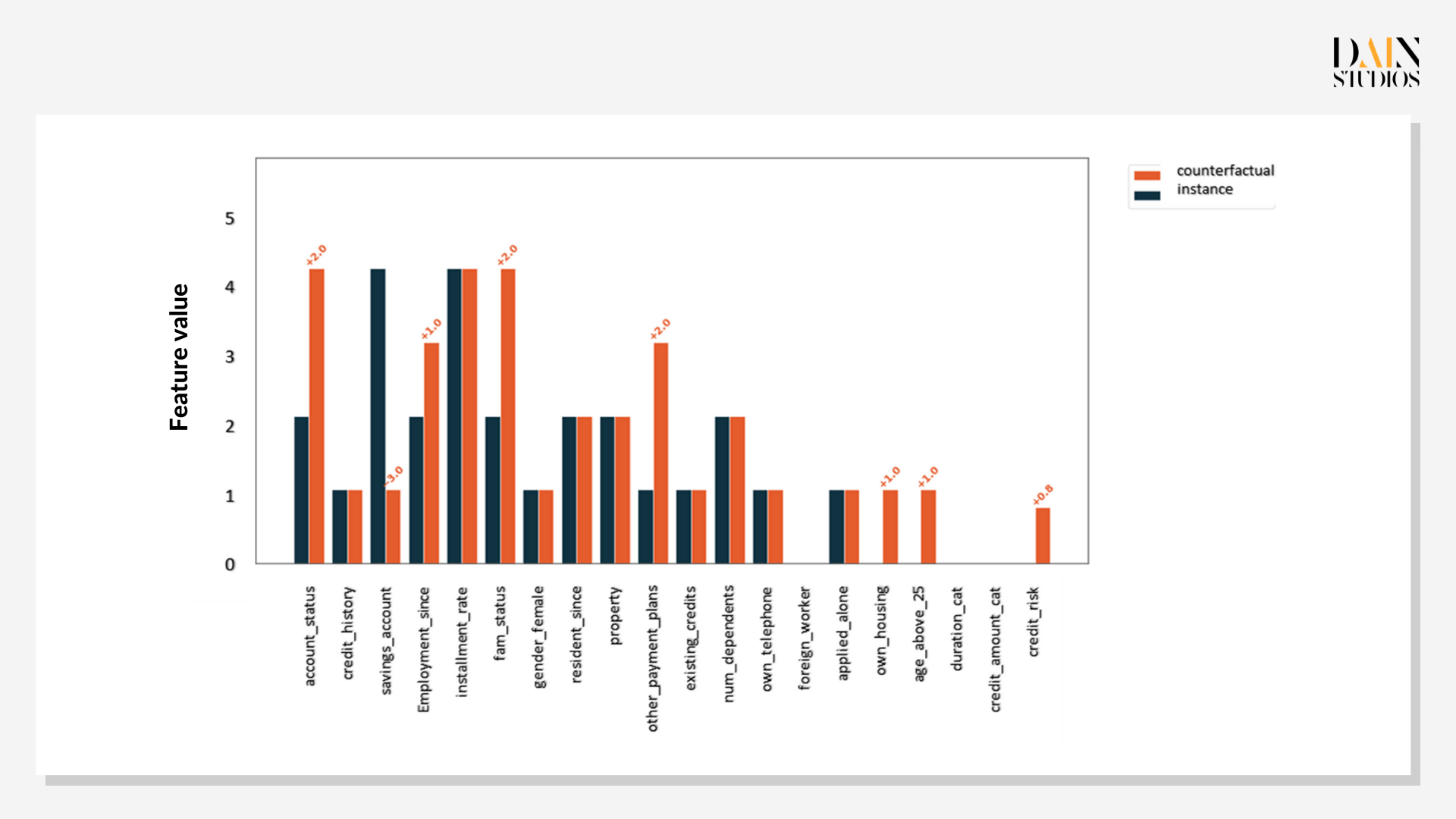
Da nicht alle Wege gleichermaßen gangbar sind, ist es sinnvoll, mit mehreren genetischen Kontrafakten zu arbeiten. In diesem Fall deutete das erste Beispiel auf eine Verbesserung der Kreditwürdigkeit hin, die relativ einfach erreicht werden kann (z. B. durch Reduzierung ihrer Schulden) und ausreichen würde, um sie zu einer stärkeren Kandidatin zu machen. Die letzten beiden Beispiele würden viel mehr Zeit und Dinge erfordern, die nicht vollständig in der Kontrolle von irgendjemandem liegen, wie z. B. die Gründung einer Familie. Dennoch wären sie für die Bank von unschätzbarem Wert, um der Kreditantragstellerin klar zu erklären, warum sie sich entschieden hat, ihr keinen Kredit zu gewähren.
Die Fähigkeit, ML-Modelle zu erklären, kommt den Menschen zugute, die sie verwenden, und denen, über die der Computer entscheidet. Es ermöglicht Unternehmen, ihre Entscheidungen besser zu erklären, die Kommunikation mit Kunden zu verbessern und Klagen über Entscheidungen zu vermeiden, die seltsam erscheinen. Die analysierten Personen können ihre Ergebnisse verbessern – und sogar in der KI-"Blackbox" Gewinnmuster und -strategien in bestimmten Merkmalskombinationen finden. Zu guter Letzt können Data Scientists Hypothesen testen und ihre Modelle debuggen, um sicherzustellen, dass fairere und genauere Lösungen überhaupt erst kommerziell genutzt werden.

{kind=link}
{kind=link}
{kind=link}
{kind=link}