Die Anforderungen zum Erstellen einer API für maschinelles Sehen sind einfach. Sie benötigen ein Google-Konto, um auf Ihr Google Drive zugreifen und Google Colab nutzen zu können.
1. Erstellen Sie Ihren Bilddatensatz
Wir werden Blumen klassifizieren, aber anstatt vorhandene Datensätze aus dem Internet zu verwenden, werden wir unseren eigenen beschrifteten Bilddatensatz mit Google Bilder erstellen.
Öffnen Sie zunächst Ihr neues Notebook Google Colab und verbinden Sie es mit dem folgenden Code mit Ihrem Laufwerk:
from google.colab import drive
drive.flush_and_unmount()
drive.mount('/content/gdrive', force_remount=True)
root_dir = "/content/gdrive/My Drive/"Sie werden aufgefordert, auf einen Link zu klicken und den Code, der Ihnen zur Verfügung gestellt wird, in das Feld in der Ausgabe der Zelle zu kopieren und einzufügen.
Jetzt können Sie von Ihrem Notebook aus auf die Daten in Google Drive zugreifen.
Laden Sie die Bilder herunter und speichern Sie sie in Google Drive. Gehen Sie dazu auf Google Image und suchen Sie nach den Objekten, die Sie klassifizieren möchten. In unserem Fall wollen wir Sonnenblume, gelbes Gänseblümchen und gelbe Tulpe klassifizieren. Fangen wir mit den Sonnenblumen an. Suchen Sie Sonnenblumen auf dem Google-Bild und scrollen Sie nach unten, bis Sie weitere Ergebnisse anzeigen sehen. Öffnen Sie dann den Entwicklermodus Ihres Browsers und rufen Sie die Webkonsole auf.
Fügen Sie dort den folgenden Code ein, um eine CSV-Datei mit allen Bild-URLs herunterzuladen:
urls = Array.from(document.querySelectorAll('.rg_di .rg_meta')).map(el=>JSON.parse(el.textContent).ou);window.open('data:text/csv;charset=utf-8,' + escape(urls.join('\n')));Dies löst den Download der Datei aus. Speichern Sie es, und laden Sie es mit dem Widget auf der linken Seite des Notizbuchs hoch: Dateien > Hochladen. Mache das Gleiche mit den anderen Blumen.
Wir werden nun die fast.ai Bibliothek verwenden. Erstellen Sie eine Zelle und fügen Sie Folgendes ein:
!curl -s https://course.fast.ai/setup/colab | bashDadurch wird die Bibliothek installiert und Ihr Colab-Notebook so konfiguriert, dass es reibungslos damit ausgeführt wird. Aktivieren Sie dann die GPU und gehen Sie zur Laufzeit > ändern Sie den Laufzeittyp > GPU.
2. Daten herunterladen
Importieren Sie nun die Bibliothek und laden Sie die Bilder herunter:
from fastai.vision import *
from fastai.metrics import error_rate
In [0]:
folders_files = [('sunflowers', 'sunflowers.csv'), ('yellow_daisy', 'yellow_daisy.csv'), ('yellow_tulips', 'yellow_tulips.csv')]
for (folder, file) in folders_files:
path = Path('/content/gdrive/My Drive/DeepLearning/Datasets/')
folder = (path/folder)
folder.mkdir(parents=True, exist_ok=True)
download_images(path/file, folder, max_pics=200)
verify_images(folder, delete=True, max_size=500)Hier erstellen wir einen Ordner und laden 200 Bilder für jede Klasse herunter und überprüfen, ob sie nicht beschädigt sind.
Als Nächstes erstellen wir ein ImageDataBunch aus den heruntergeladenen Bildern. Dieses Objekt stellt unsere Daten mit ihren Beschriftungen dar. Um den Prozess zu optimieren, haben wir außerdem:
- Teilen Sie die Daten auf, um 20 % der Validierung zu erhalten
- Ändern Sie die Größe der Daten in Quadraten von 224 Bildern
- Betreiben Sie die Bildvergrößerung mit get_transforms
- Normalisieren der Daten
np.random.seed(42)
data = ImageDataBunch.from_folder(path, train=".", valid_pct=0.2,
ds_tfms=get_transforms(), size=224, num_workers=4).normalize(imagenet_stats)3. Daten anzeigen
Visualisieren wir unsere Daten:
data.show_batch(rows=3, figsize=(7,6))
Alles scheint korrekt zu sein. Um jedoch eine optimale Leistung zu gewährleisten, sollten Sie die Bilder manuell überprüfen und die inkonsistenten Bilder aus Ihrem Dataset entfernen. Die Google Drive-Benutzeroberfläche ist sehr praktisch, um Bilder manuell zu validieren und zu filtern.
4. Modell trainieren
Jetzt werden wir unser Modell trainieren. Die fast.ai Bibliothek ist prägnant und mit guten Standardfunktionen ausgestattet.
learn = cnn_learner(data, models.resnet34, metrics=error_rate)
learn.fit_one_cycle(4)Downloading: “https://download.pytorch.org/models/resnet34-333f7ec4.pth” to /root/.cache/torch/checkpoints/resnet34-333f7ec4.pth 100%|██████████| 87306240/87306240 [00:00<00:00, 109355856.48it/s]
| Epoche | train_loss | valid_loss | error_rate | Zeit |
| 0 | 0.890968 | 0.387459 | 0.138528 | 0:28 |
| 1 | 0.527052 | 0.283305 | 0.064935 | 0:18 |
| 2 | 0.378353 | 0.281448 | 0.064935 | 0:18 |
| 3 | 0.282371 | 0.271847 | 0.060606 | 0:18 |
Mit diesen Zeilen laden wir ein vortrainiertes Modell ResNet34 herunter, übergeben unsere Daten und legen die Metrik als Fehlerrate fest.
Dann passen wir das Modell an die Ein-Zyklus-Politik an, da diese Art des Ansatzes in der Regel gut funktioniert.
Wir haben eine Fehlerquote von 6%, was nicht schlecht ist, aber wir könnten es besser machen. Wir trainierten die obersten Schichten des vortrainierten Modells. Lassen Sie uns die Fixierung aller Ebenen aufheben, damit ihre Parameter während der Trainingsphase geändert werden können.
learn.unfreeze()fast.ai Bibliothek bietet lr_find , die einen LR-Reichweitentest startet, der Ihnen hilft, eine gute Lernrate auszuwählen. Zeichnen der Kurve:
learn.lr_find()
learn.recorder.plot()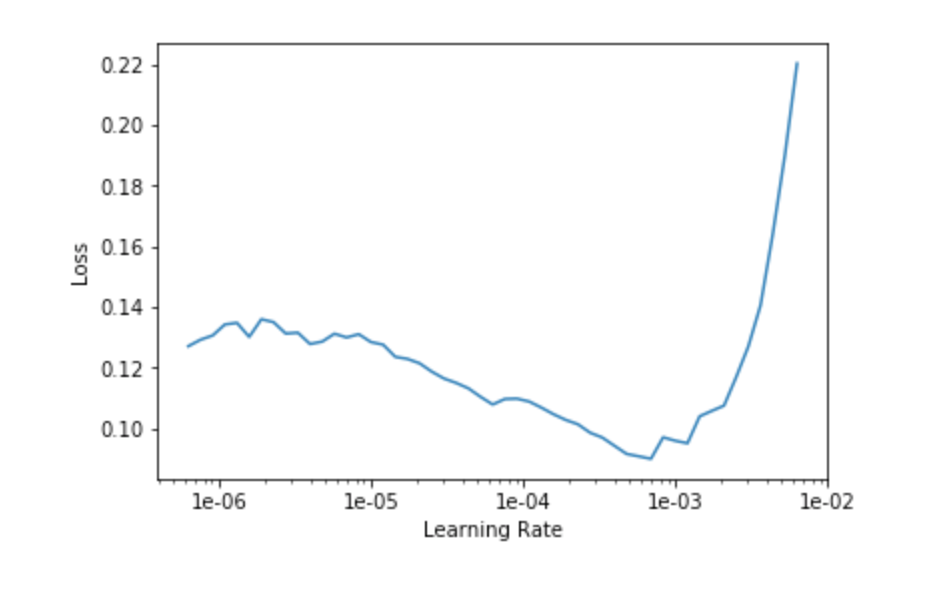
Als Faustregel gilt, die stärkste Neigung nach unten zu erkennen. Daher wählen wir den Anfang des Bereichs bei 1e-5 und entscheiden uns dafür, bei 1e-4 aufzuhören, da wir bereits standardmäßig bei 1e-3 trainiert haben. Auf diese Weise werden die ersten Schichten mit einer Lernrate von 3e-5 und die letzten mit 3e-4 trainiert.
learn.fit_one_cycle(10, max_lr=slice(3e-5,3e-4))| Epoche | train_loss | valid_loss | error_rate | Zeit |
| 0 | 0.13375 | 0.250481 | 0.056277 | 0:18 |
| 1 | 0.094298 | 0.215684 | 0.038961 | 0:19 |
| 2 | 0.068966 | 0.253927 | 0.038961 | 0:19 |
| 3 | 0.052962 | 0.270199 | 0.034632 | 0:18 |
| 4 | 0.039442 | 0.25092 | 0.034632 | 0:19 |
| 5 | 0.032108 | 0.251597 | 0.034632 | 0:18 |
| 6 | 0.028615 | 0.254128 | 0.034632 | 0:19 |
| 7 | 0.022683 | 0.250784 | 0.034632 | 0:19 |
| 8 | 0.018629 | 0.257523 | 0.034632 | 0:18 |
| 9 | 0.015092 | 0.253845 | 0.034632 | 0:18 |
3,5 % Fehler, was besser ist.
Analysieren wir die Klassifizierungsfehler:
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix(figsize=(12,12), dpi=60)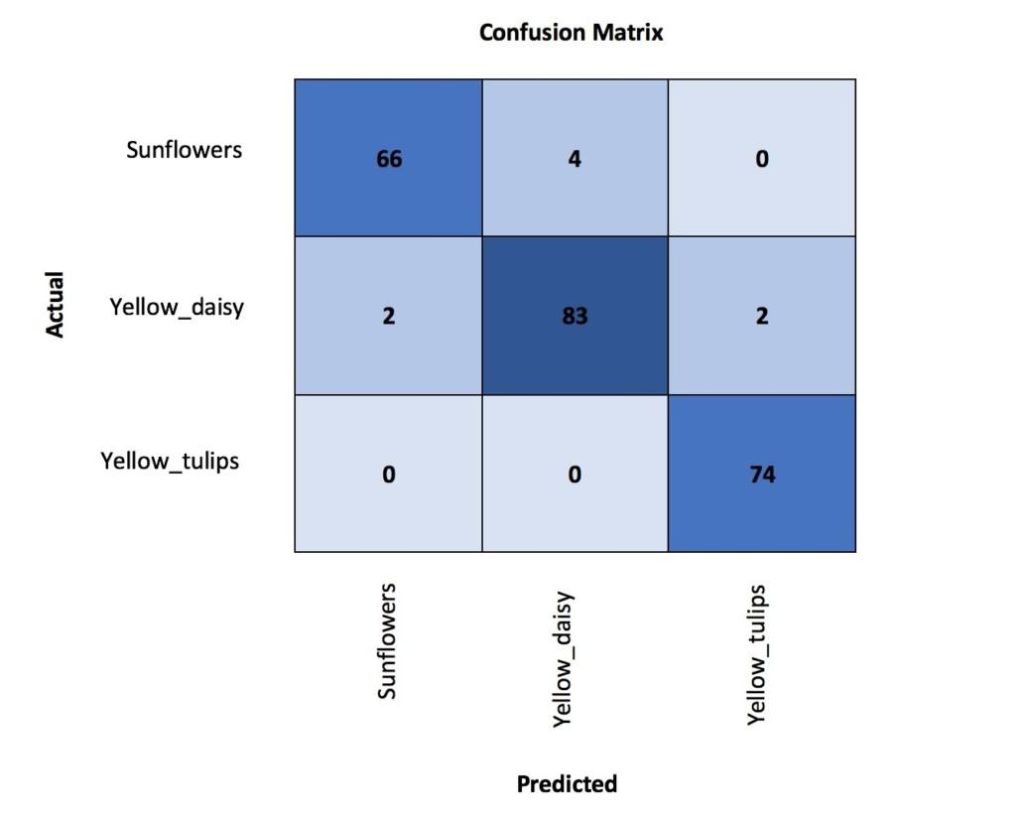
Wir sehen, dass die meisten Fehler auf die Verwechslung von gelben Gänseblümchen und Sonnenblumen zurückzuführen sind, die aufgrund ihrer visuellen Ähnlichkeiten verständlich sein können. Das Zeichnen der Fehler, die den größten Top-Verlust hatten, kann uns helfen, die Ursachen des Fehlers besser zu verstehen.
interp.plot_top_losses(9, figsize=(15,11))
Einige normale Bilder wurden falsch klassifiziert, aber andere sehen überhaupt nicht wie Blumen aus. Dieser Prozess zeigt, dass wir den Datensatz nicht in dem Maße bereinigt haben, wie wir es hätten tun sollen. Um die Leistung zu verbessern, sollten wir daher das Bilddataset bereinigen und den Prozess erneut ausführen, um eine konsistente Bewertung zu erhalten.
Nachdem wir unser Modell gereinigt und neu trainiert haben, sollte es eine Schande sein, es im Notebook zu behalten, lassen Sie es uns in die Produktion bringen!
5. Exportieren des API-Modells in die Produktion
Speichern Sie Ihr Modell:
learn.export()Laden Sie es herunter und speichern Sie es am unteren Rand Ihres lokalen API-Ordners. Wir werden jetzt eine grundlegende API erstellen, die es dem Benutzer ermöglicht, ein Bild hochzuladen und die Vorhersage zu erhalten.
Erstellen Sie eine virtuelle Umgebung mit Python 3 mit Flask und fast.ai Bibliothek.
Erstellen Sie api_endpoint.py und fügen Sie den folgenden Code ein:
import os
from flask import Flask, flash, request, redirect, url_for, send_from_directory, jsonify
from werkzeug.utils import secure_filename
from fastai.vision import *
app = Flask(__name__)
UPLOAD_FOLDER = os.getcwd() + '/files/'
ALLOWED_EXTENSIONS = {'png', 'jpg', 'jpeg', 'gif'}
app = Flask(__name__)
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
def allowed_file(filename):
return '.' in filename and \
filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
# check if the post request has the file part
if 'file' not in request.files:
flash('No file part')
return redirect(request.url)
file = request.files['file']
# if user does not select file, browser also
# submit an empty part without filename
if file.filename == '':
flash('No selected file')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
img = open_image(file)
pred, _, losses = learner.predict(img)
print(pred)
file.save(os.path.join(app.config['UPLOAD_FOLDER'], filename))
return jsonify(str(pred))
return '''
<!doctype html>
<title>Upload new File</title>
<h1>Upload new File</h1>
<form method=post enctype=multipart/form-data>
<input type=file name=file>
<input type=submit value=Upload>
</form>
'''
@app.route('/uploads/<filename>')
def uploaded_file(filename):
# return send_from_directory(app.config['UPLOAD_FOLDER'],
# filename)
return 'File updated!'
if __name__ == '__main__':
defaults.device = torch.device('cpu')
learner = load_learner('.')
print('OK')
app.run(host="0.0.0.0", port=int("80"), debug=True)Starten Sie Ihre API mit Python-api_endpoint.py und greifen Sie mit http://0.0.0.0/ zu
Dort können Sie Ihr Bild hochladen und Ihre Klassifizierung erhalten. Zum Beispiel mit diesem Bild:

Als Rückgabeergebnis haben wir den folgenden JSON-Code:
{
"sunflower"
}6. Nächste Schritte
Um tiefer in Computer Vision und API-Erstellung einzusteigen, empfehle ich Ihnen dringend, die hervorragenden Kurse von https://www.fast.ai/ auszuprobieren.
Sie können den Code in der DAIN Studios' GitHub-Repository
Geschrieben von Thomas Nguyen, Data Engineer bei DAIN Studios mit Sitz in BerlinDeutschland.