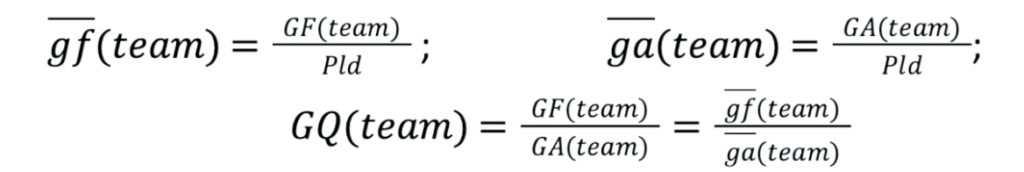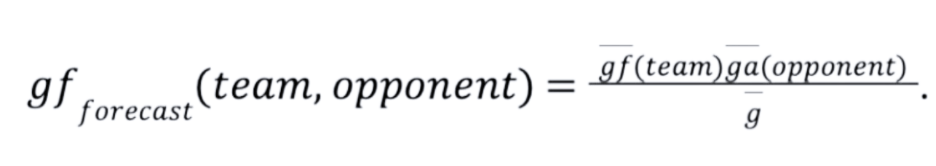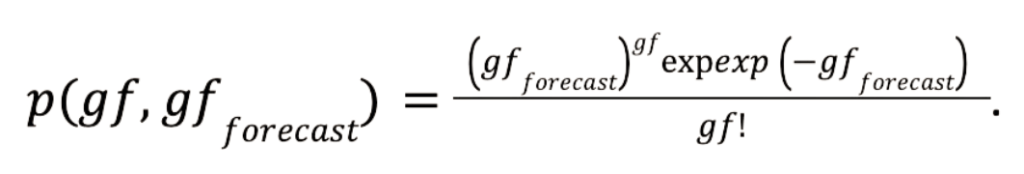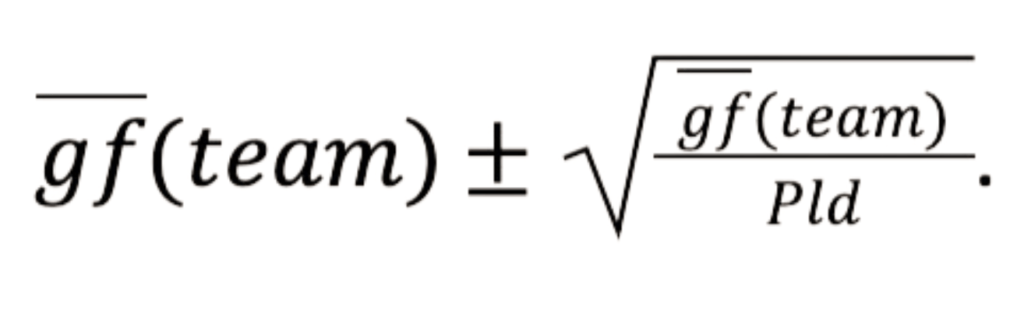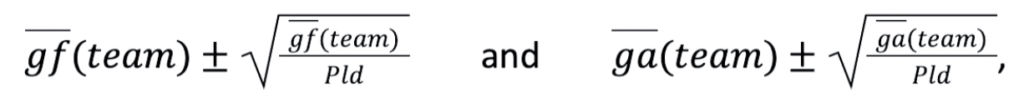Die meisten Fans wissen, dass Fußballmannschaften oft starken Leistungsschwankungen ausgesetzt sind. In der einen Saison scheint eine Qualifikation für die Champions League möglich, was Besuche in einigen der legendärsten Fußballstadien Europas und zusätzliche Einnahmen in Millionenhöhe bedeutet. In der nächsten Saison droht möglicherweise der Abstieg, ein finanzieller Schock, den viele Vereine nur schwer verkraften können. In einer solchen Saison kann der Manager mehrmals ausgetauscht werden. Diese Schwankungen werfen die Frage auf, ob es wirklich möglich ist, die Leistung anhand einiger weniger Spiele zu beurteilen. Im Folgenden erörtern wir eines der einfachsten Modelle zur Vorhersage des Ausgangs von Spielen und einer ganzen Saison. Wir stützen unsere Modellierung auf nur zwei Merkmale, die Tore für (GF) und gegen (GA) jede Mannschaft während einer Saison. Diese Merkmale sind in der Regel in Fußball-Ergebnistabellen aufgeführt.
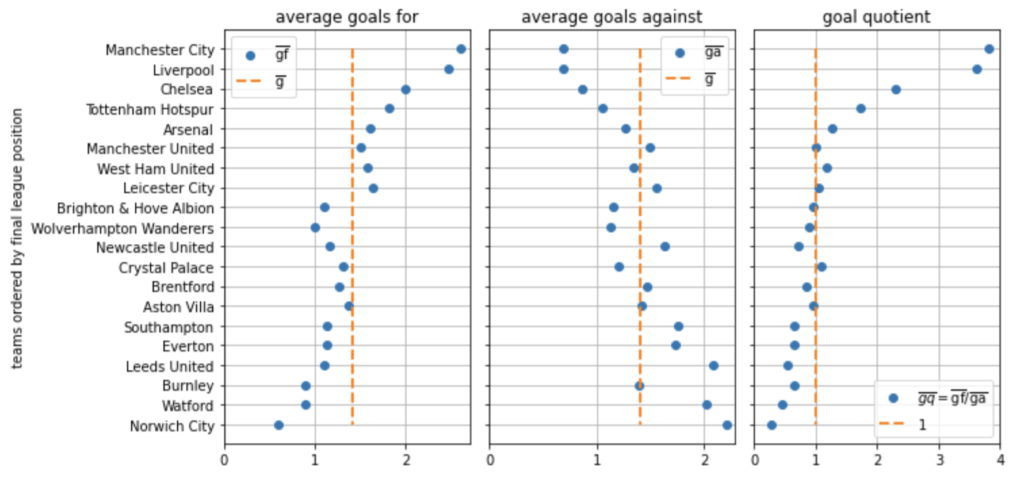
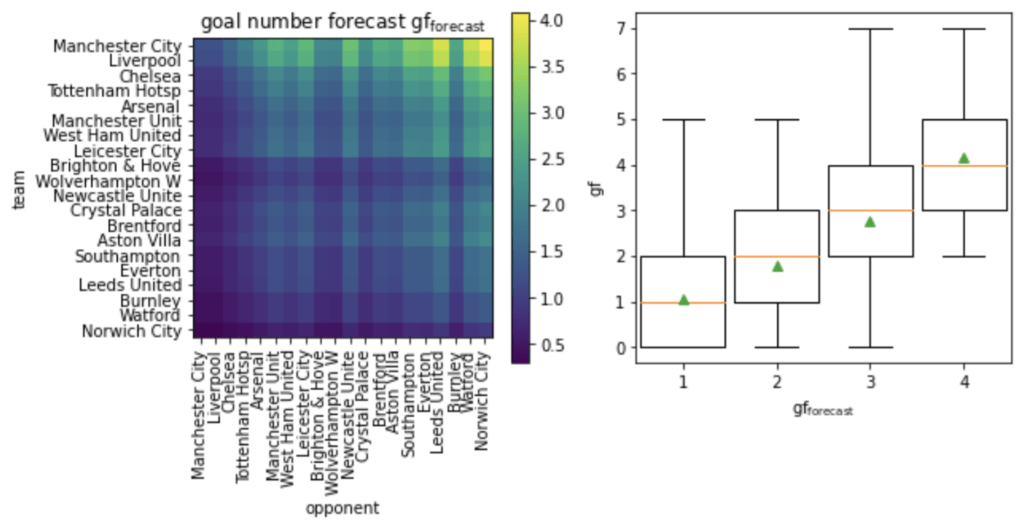
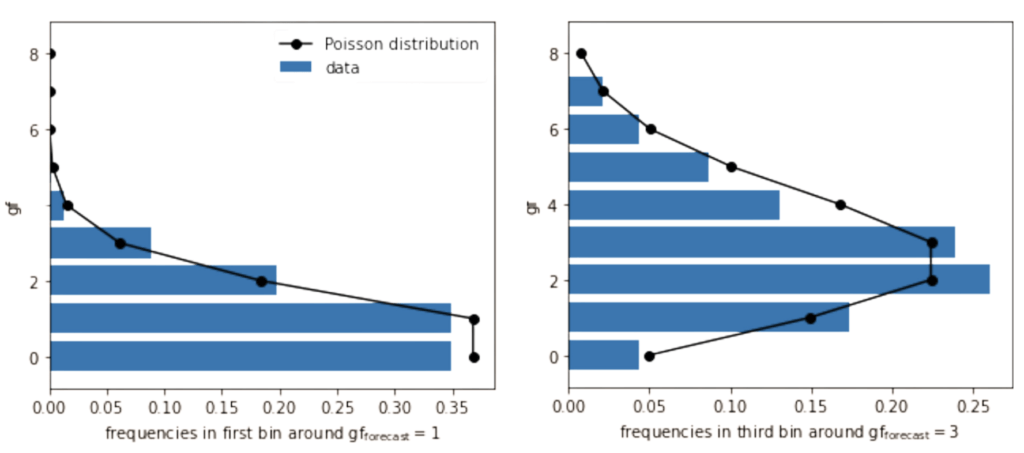
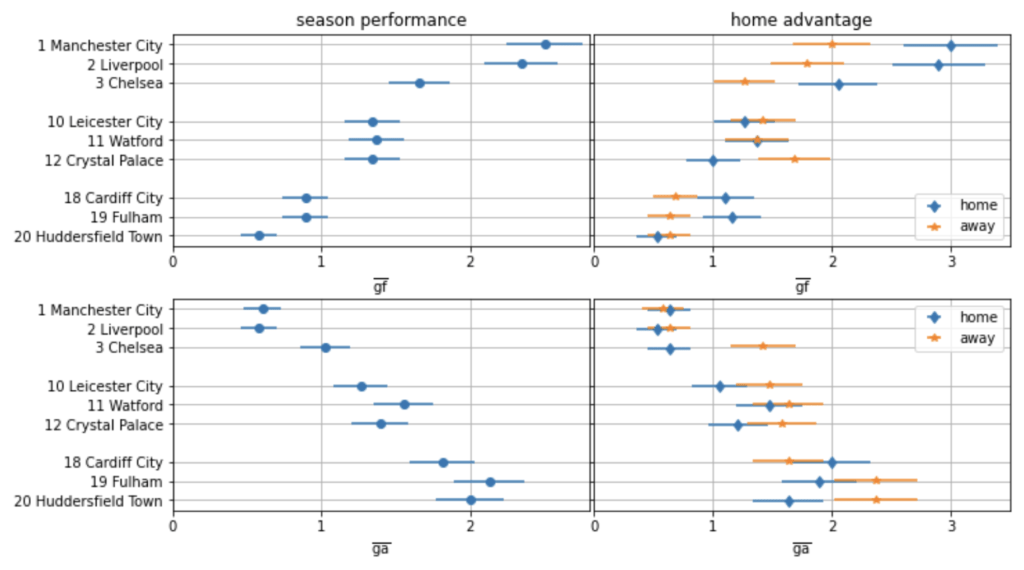
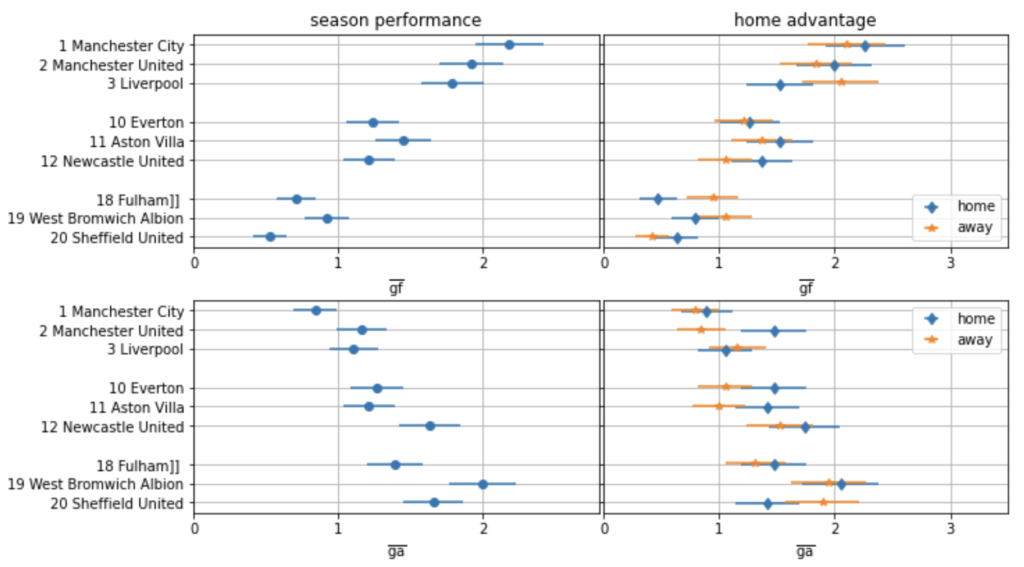
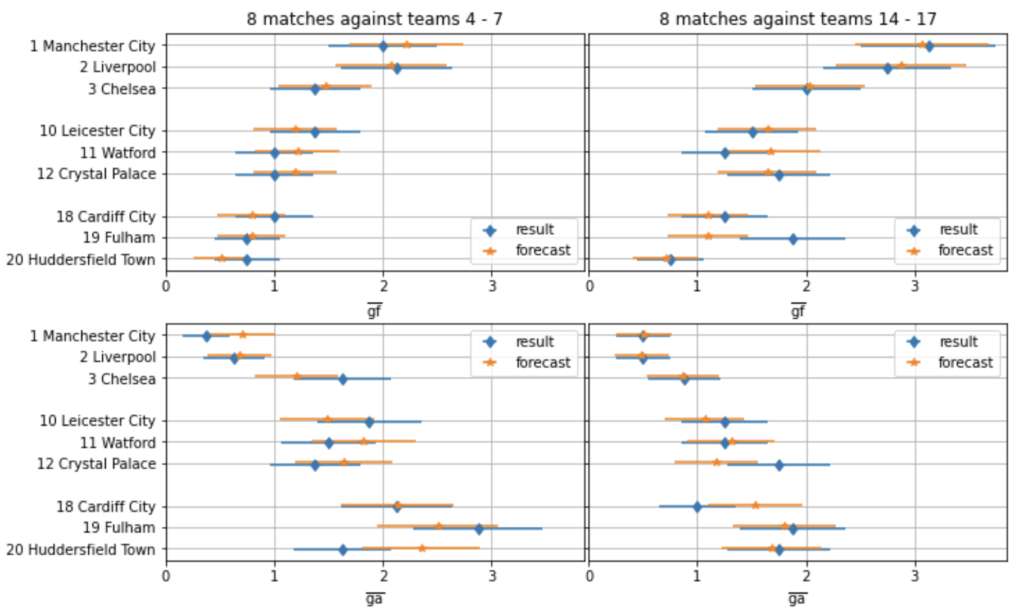
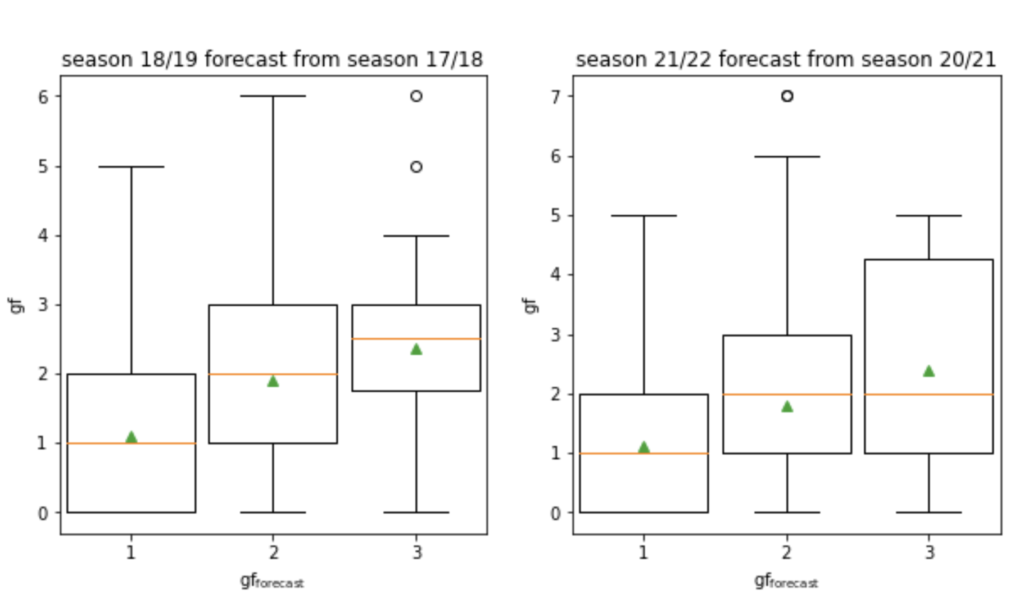
Die Beispieltabelle auf der linken Seite der folgenden Abbildung bezieht sich auf die Saison 2021/22 der Premier League, an der zwanzig Mannschaften teilnahmen. Das Modell ermöglicht es uns, zu beurteilen, ob eine Mannschaft über mehrere Spiele hinweg zu wenig oder zu viel geleistet hat, indem es die Torwahrscheinlichkeiten für jede Mannschaft über alle gespielten Spiele hinweg vorhersagt.
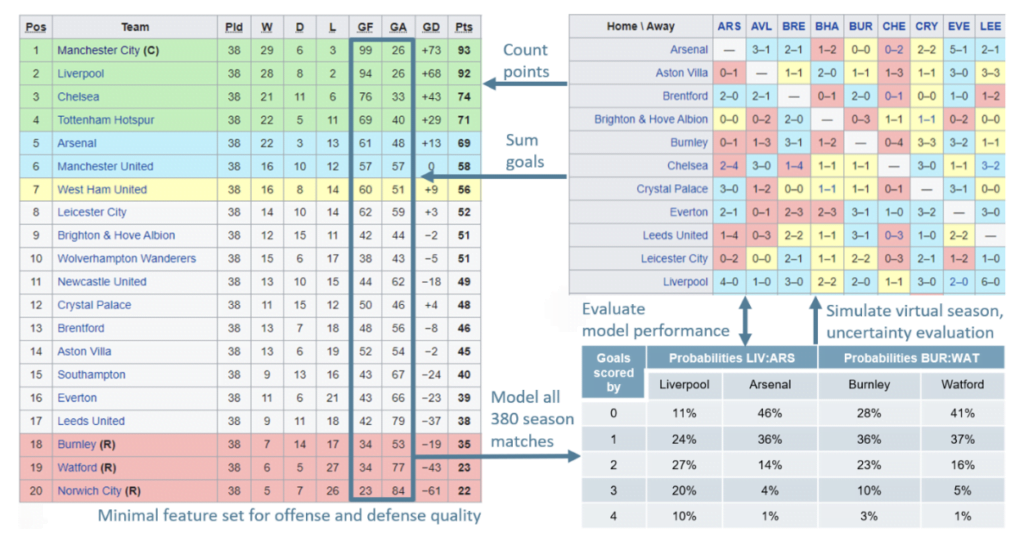
Datenaufbereitung und Modellierungslogik
Bevor wir mit der Modellierung beginnen, sollten wir zunächst die Eingabedaten vorbereiten. Das Modell sollte für jede Liga funktionieren, unabhängig von der Anzahl der ausgetragenen Spiele. Daher konstruieren wir skalierbare Messgrößen wie die durchschnittlichen Tore für(gf) und gegen ein Team(ga) pro Spiel und einen Torquotienten (GQ), das Verhältnis von erzielten zu kassierten Toren jeder Mannschaft. Diese Merkmale sind liga- und stichprobenübergreifend vergleichbar (d. h. über einige Spiele oder mehrere Spielzeiten hinweg):