Die Technologie steht im Mittelpunkt jeder Daten- und KI-Transformation. Während wir in den bisherigen Artikeln strategische und menschliche Faktoren erörtert haben, ist es nun an der Zeit, unsere Aufmerksamkeit auf die Technologie selbst zu richten. Sie ermöglicht es den Unternehmen von heute, Daten in Erkenntnisse zu verwandeln. Technologie bedeutet im Zusammenhang mit Daten und KI nicht nur die Algorithmen und Funktionen, die den Modell-Output generieren, sondern umfasst im Wesentlichen auch die zugehörigen Datenbestände und die Gesamtarchitektur, in die die Lösung eingebettet ist. Das Zusammenspiel dieser drei Elemente ist entscheidend dafür, dass Daten und KI für Sie funktionieren.
Dies ist Teil 4 unserer vierteiligen Artikelserie, in der wir erklären, wie wir unsere Kunden bei ihrer Daten- und KI-Transformationsreise beraten und das DAIN Data & AI Maturity Model vorstellen.
- Teil 1 gibt einen Überblick über das DAIN Data & AI Maturity Model (DAMM).
- Teil 2 befasst sich eingehender mit den strategischen Einflussfaktoren.
- In Teil 3 werden die organisatorischen und menschlichen Voraussetzungen erläutert.
- Teil 4 (dieser Artikel) befasst sich mit den Kerntechnologien der Daten- und KI-Transformationen.
Alle Unternehmen verfügen bereits über Daten und Datenbanken, und viele haben Data Warehouses, in denen die Daten für Berichte und Analysen verarbeitet und gespeichert werden. Was ist also so anders an der Arbeit mit Big Data, dass neue Ansätze für Datenbestände, Architektur und Technologie erforderlich sind? Wir beginnen damit, zu verstehen, was ein Analyse- und KI-Portfolio ist, bevor wir darauf eingehen, wie die zugrunde liegenden Datenbestände verwaltet werden sollen, und werfen schließlich einen Blick auf die gängigen Architektur- und Technologiekomponenten, die zur Unterstützung von Daten- und KI-Anwendungsfällen verwendet werden.
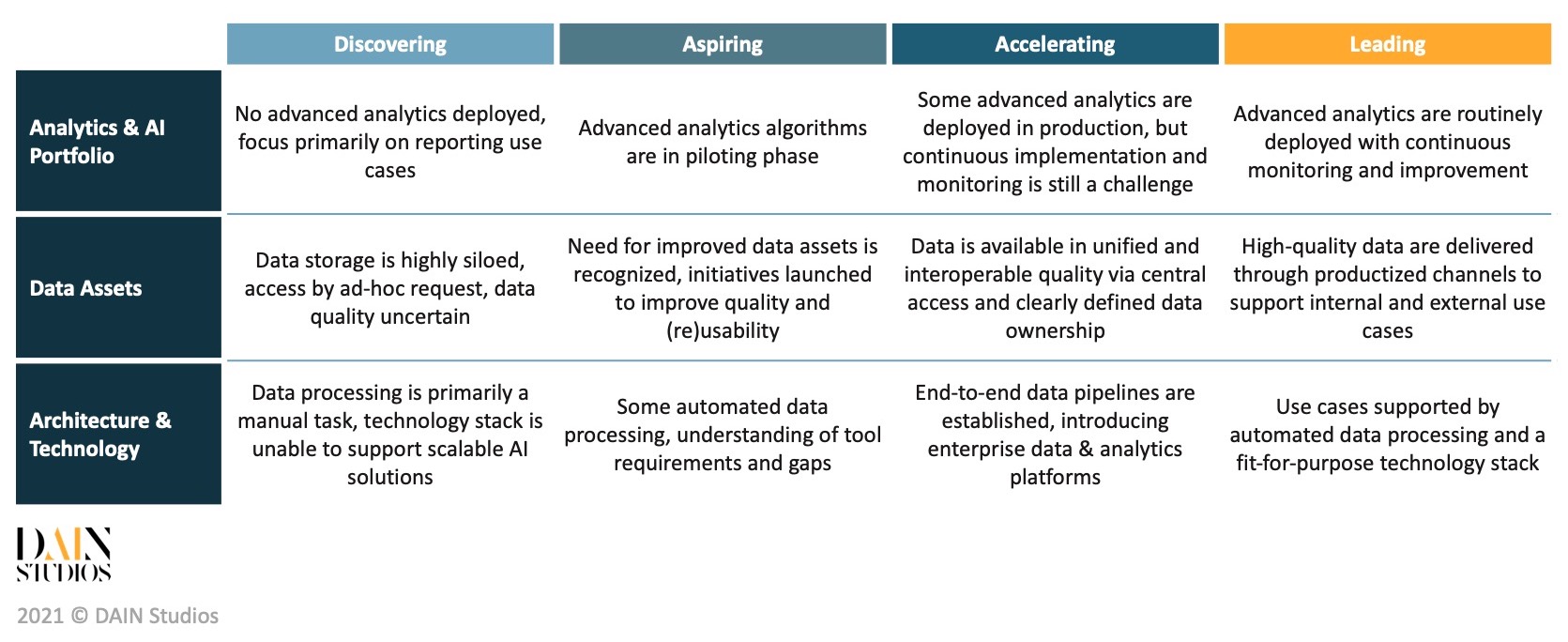
Wie sieht ein ausgereiftes Analytik- und KI-Portfolio aus?
Das Analyse- und KI-Portfolio umfasst eine breite Palette von Analyselösungen, angefangen von einfachen Berichten, Visualisierungen über automatisierte Dashboards bis hin zu angewandten Lösungen für maschinelles Lernen, die Vorhersagen und Entscheidungen für verschiedene Geschäftsprobleme liefern.
Traditionell konzentrierten sich Unternehmensanalysten auf die Berichterstattung darüber, was geschehen ist, und hatten in der Regel nur einen Überblick über eine oder einige wenige Geschäftsfunktionen. Moderne Analysen gehen weit über die Berichterstattung über das Bekannte hinaus und versuchen, unbekannte Attribute (sei es die Zukunft oder einfach nur unentdeckte Werte) vorherzusagen, wobei Daten verwendet werden, die weit in die Vergangenheit zurückreichen und oft verschiedene Geschäftsbereiche umfassen. Um die Nutzung von Daten über Silos hinweg zu ermöglichen, sollten Unternehmen den Anwendungsbereich der Analytik erweitern und versuchen, ein breites Spektrum unterschiedlicher Datenquellen zu nutzen und ein umfassendes Bild des Geschäftsgeschehens zu entwickeln.
Reife bedeutet, dass das Unternehmen in der Lage ist, fortgeschrittene Techniken einzusetzen, wenn es das Problem erfordert, und nicht, dass Deep Learning auf jedes Problem angewandt wird, mit dem es konfrontiert wird. Ein systematischer Ansatz für das Verständnis, die Auswahl und die Bewertung der richtigen Lösung führt mit größerer Wahrscheinlichkeit zu einer Wertschöpfung für das Unternehmen als das Erzwingen von hochmodernen Algorithmen für einfache Problemstellungen.
Ein weiterer wichtiger Indikator für den Reifegrad ist die Art und Weise, wie sich das Analyse- und KI-Portfolio über die Bereitstellung hinaus entwickelt. Überwachung, Tests und Upgrades der Analyselösungen sind notwendig, um die Modellleistung aufrechtzuerhalten (aufgrund von Daten- und Modellabweichungen). Führende Unternehmen sind in der Lage, die neuesten Funktionen reibungslos, zeitnah und zuverlässig in ihre bestehenden Lösungen zu integrieren und die Modelle nicht nur zu warten, sondern auch kontinuierlich zu testen und zu optimieren, um ihre Leistung zu verbessern. Ähnlich wie die weit verbreitete, lebenszyklusorientierte Softwareentwicklungspraxis DevOps ist MLOps eine angeleitete Methodik, die die Grundsätze der kontinuierlichen Integration/kontinuierlichen Bereitstellung (CI/CD) auf das erneute Training und die Bereitstellung von Lösungen für maschinelles Lernen ausweitet.
Einer der wichtigsten Aspekte, der die Entwicklung von Software und Hardware unterscheidet, ist die Wiederverwendbarkeit. In ähnlicher Weise können und sollten viele Analyselösungen innerhalb des Unternehmens wiederverwendet werden - zumindest teilweise. Dies setzt voraus, dass die Analyseteams eine Portfoliomentalität beibehalten und intern gut verpackte Lösungen erstellen, die sie selbst oder andere Teile des Unternehmens mit ähnlichen Fähigkeiten wiederverwenden können. Die Wiederverwendbarkeit schafft Vorteile, indem sie die Entwicklung beschleunigt, die Kosten und die Zeit bis zur Markteinführung reduziert und auch die Zuverlässigkeit verbessert, da bereits getestete Methoden verwendet werden. Um die Wiederverwendbarkeit zu verbessern, sollten Unternehmen entwickelte Algorithmen speichern und eine Kultur der Wiederverwendung von Methoden aus dem Portfolio schaffen, wenn sie dies für sinnvoll halten. Analyseteams können gemeinsame Paketbibliotheken, gemeinsame Entwicklungs-Notebooks, Feature-Repositories und viele andere Tools und Praktiken nutzen, um diesen Wissensaustausch zu fördern.
Erkennen Sie Ihre Daten an und behandeln Sie sie wie ein zentrales Gut
Jede Analyselösung ist nur so gut wie die Daten, die ihr zugrunde liegen. In einem ersten Schritt wird die Erkenntnis, dass Daten ein zentrales Gut für Ihr Unternehmen sind, den Ehrgeiz im Umgang mit diesem neuen Gut erhöhen. Die Gewährleistung der Datenqualität und -verwendbarkeit ist eine echte Herausforderung, mit der viele Unternehmen heute zu kämpfen haben.
Probleme mit der Datenqualität sind vielleicht leicht zu erkennen, aber die Gesamtqualität ist eine Kombination aus mehreren Faktoren. Ein Beispiel: Für eine erfolgreiche Marketingkampagne müssen die Kundendaten eindeutig, genau und zeitnah sein. Die Dimensionen der Datenqualität erfassen die Attribute, die für Ihren Geschäftskontext spezifisch sind. Im Allgemeinen gibt es sechs Merkmale, die Sie bei der Datenqualität finden: Die Daten müssen genau, vollständig, konsistent, zeitnah, gültig und eindeutig sein.
Insgesamt haben Datenbestände mehr Dimensionen als die oben genannten Qualitätsattribute, da sie auch die Nutzbarkeit aufweisen müssen. Wir bewerten die Nutzbarkeit von Datenbeständen häufig nach den FAIR-Prinzipien(https://www.go-fair.org/fair-principles/). Sind die Daten Findbar, d. h. verfügen die Daten über eine ausreichende Dokumentation und Metadaten, die sie unterstützen? Lassen sich die Daten leicht Auf die Daten kann leicht zugegriffen werden, sind die Zugriffs- und Authentifizierungsverfahren transparent und effizient? Sind die Daten Interoperabel, lassen sie sich mit anderen Datenquellen kombinieren und mühelos in Datenpipelines integrieren? Und sind die Daten Reutzbar, d. h. werden sie in einem Format präsentiert, das eine breite Nutzung ohne umfangreiche Datenumwandlung und Neuformatierung ermöglicht? Anhand der oben genannten Dimensionen können Sie sich ein objektives Bild von der Qualität und Nutzbarkeit Ihrer vorhandenen Datenbestände machen.
Die Breite der neuen Datenerfassung ist der nächste wichtige Aspekt. Die meisten Organisationen erfassen in erster Linie Daten, die intern durch ihre Kerntätigkeiten entstehen, und sie gehen dabei nicht sehr systematisch vor. Viele beginnen ihre Datenreise nach dem Motto: "Wir müssen zuerst sicherstellen, dass wir alle möglichen Daten sammeln, später werden wir herausfinden, was wir damit machen". Es ist zwar richtig, dass nicht Daten sammeln nicht zu sammeln, aber das Sammeln großer Datenmengen ohne Zweck kann erhebliche Kopfschmerzen und Speicherkosten verursachen. Je länger diese Praxis anhält, desto wahrscheinlicher ist es, dass die Daten nie zur Wertschöpfung für das Unternehmen genutzt werden. Wir raten unseren Kunden stets, sich frühzeitig Gedanken über ihre wichtigsten Dateneinheiten (z. B. Kunden, Produkte, Lieferanten) zu machen und ihre Datenerfassung auf diese Einheiten auszurichten. Führende Unternehmen sind in der Lage, eine so genannte 360°-Sicht auf ihre wichtigsten Einheiten einzurichten, wobei die Daten sowohl aus internen Aktivitäten als auch aus externen Quellen auf einheitliche und konsistente Weise erfasst werden. Dies macht die Datenbestände wirklich reichhaltig und nützlich für Analysezwecke.
Das Sammeln, die Pflege und die Verwaltung von Daten in ausreichender Qualität für die Analyse von Nutzern und Anwendungen sind die wichtigsten Ziele des Datenmanagements. Die Festlegung der Grundsätze und Praktiken von Data Governance , die Zuweisung klarer Datenzuständigkeiten (Eigentum, Verwaltung usw.) und die Einrichtung von Entscheidungsgremien sind grundlegende Schritte bei der Schaffung einer gut funktionierenden Datenmanagementorganisation. Ein guter Indikator für die Reife des Datenmanagements ist eine klar definierte Datenontologie, ein transparenter Datenkatalog, unternehmensweit einheitlich genutzte Metadaten und klar geschichtete Daten, die in geeigneten Lösungen gespeichert werden. Führende Unternehmen verfolgen einen datenorientierten Ansatz und sind bestrebt, ihre Datenbestände so zu produzieren, dass sie jederzeit über standardisierte Protokolle (z. B. dokumentierte APIs) auch außerhalb des Unternehmens ausgetauscht werden können (falls erforderlich).
Datenverflechtung ist ein neu aufkommendes Paradigma, das großen Organisationen mit disparaten Datensätzen für viele Anwendungen und Endnutzer zugute kommt. Entgegen der landläufigen Meinung handelt es sich bei Data Mesh nicht um eine Technologie. Es handelt sich vielmehr um eine Reihe von Grundsätzen, die Ihnen helfen, Ihre Datenbestände in einer föderierten Weise zu organisieren und zu verwalten. Das bedeutet, dass Sie Ihre Daten in entsprechende Datendomänen aufteilen und die Verantwortung an dedizierte Datenprodukteigentümer delegieren, die dafür verantwortlich sind, ihr eigenes Datenprodukt an ihre Kunden innerhalb oder außerhalb des Unternehmens zu bringen. Die Hauptaufgabe des zentralen Dateninfrastrukturteams besteht darin, die Technologie einzurichten und zu warten, die es den Datenprodukteigentümern und ihren Teams ermöglicht, ihren Stakeholdern produktisierte Datenbestände zur Verfügung zu stellen.
Zalando, ein stark datengetriebener europäischer Modehändler, ist eines der führenden Beispiele für die Einführung von Data Mesh, um seine Datenbestände zu organisieren. Die Reise des Unternehmens im Bereich der Analytik geht von einer grundsätzlichen Zentralisierung der Datenbestände in Data Warehouses bis hin zur Einrichtung eines Data Lake. Das zentrale Dateninfrastrukturteam erkannte jedoch, dass es mit zwei grundlegenden Mängeln konfrontiert war: (1) es wurde zum Engpass bei der ausreichenden Skalierung seiner Datenbestände und (2) es gab unklare Eigentumsverhältnisse bei den Daten, die bereitgestellt wurden. Durch die Schaffung einer Geschäftsdomäne für die Daten konnte Zalando beide Probleme lösen. Das zentrale Dateninfrastrukturteam ist nun für die Wartung der Plattform verantwortlich, die die Eigentümer der Datenprodukte nutzen, um ihre Daten über produktbezogene Kanäle zur Verfügung zu stellen. Durch die Verlagerung der Verantwortung in die Nähe des Unternehmens liegt die Verantwortung für die Datenbestände in den Händen derjenigen, die das meiste Verständnis und den größten Einfluss auf die Qualität der Daten haben.
Gestaltung zukunftssicherer Technologieumgebungen für die Analytik
Die Aufgabe der Datenarchitektur besteht darin, das technologische Rückgrat für eine angemessene Erfassung, Verarbeitung und Bereitstellung von Daten für Berichtsansichten, Dashboards, Endbenutzeranwendungen und Modelle in der Produktion zu schaffen und Datenwissenschaftlern und -analysten eine Sandbox für Sondierungsarbeiten und Modellentwicklung zu bieten. Wenn sich ein Unternehmen noch in einem frühen Entwicklungsstadium befindet, sind die meisten Daten-E/A-Prozesse manuelle oder halbmanuelle Aufgaben. An diesem Punkt sollte die Erhöhung des Automatisierungsgrads und die Einrichtung der ersten Datenpipelines das vorrangige Ziel sein. Wenn dies richtig gemacht wird, entfällt mühsame menschliche Arbeit, die Zuverlässigkeit wird verbessert und die ersten analytischen Anwendungsfälle können in die Produktion einfließen. Die ersten Datenpipelines werden sich herausbilden, ebenso wie die Notwendigkeit, sie zu pflegen.
Da sich die Anbieterlandschaft schnell weiterentwickelt und die Zukunft nur schwer vorhersehbar ist, wird es von entscheidender Bedeutung sein, sich mit dem ständigen Wandel der Anforderungen und der Technologien, die diese Anforderungen erfüllen, auseinanderzusetzen. Evolutionäre Architekturen sind auf diesen ständigen Wandel ausgerichtet, und viele führende Unternehmen sind heute in der Lage, modulare, flexible Systeme zu entwickeln, bei denen sich Datenpipelines leichter aktualisieren, testen und neu ausführen lassen, ohne dass dies negative Auswirkungen auf die übrige Architektur hat.
Als Nächstes kommt der Technologiebereich, der die Datenarchitektur und die Analyseanforderungen des Unternehmens erfüllt. Angemessene Speicher- und Datenverarbeitungslösungen werden den aktuellen und künftigen Anforderungen an die Erfassung, Speicherung und Bereitstellung der Daten in verschiedenen Bereichen gerecht. Die heutigen Cloud-Anbieter bieten eine Fülle von Diensten an, die eine einfache Skalierung und Einführung neuer Funktionen nach Bedarf ermöglichen. In der Realität werden jedoch viele Unternehmen aufgrund von Altsystemen und aus Gründen der Informationssicherheit eine Mischung aus lokalem Speicher, eigener privater Cloud oder hybriden Cloud-Lösungen einsetzen müssen.
Mit dem Aufkommen moderner Plattformen für Daten und maschinelles Lernen können Datenexperten zusätzlich zu den bereitgestellten Speicher- und Rechenressourcen auf integrierte Entwicklungsumgebungen und Bereitstellungsdienste zugreifen. Unternehmen, die in den Aufbau und die Pflege dieser Plattformen investieren, werden positive Auswirkungen auf ihre Datenorganisationen erleben. Sie werden neue Anwendungsfälle ermöglichen, die besten Datentalente anziehen und insgesamt die Zeit bis zur Produktion ihrer Analyselösungen verkürzen. Um dem Ziel, datengesteuert zu werden, gerecht zu werden, müssen sich die Unternehmen jedoch darauf konzentrieren, die Analytik allen Mitarbeitern näher zu bringen, nicht nur den Datenexperten. Self-Service-Business-Intelligence (BI)-Anwendungen ermöglichen es jedem Benutzer mit Grundkenntnissen, Daten für seinen Entscheidungsprozess zu nutzen.
Schließlich sollten Analyselösungen nicht isoliert existieren. Die Daten- (oder Informations-) Architektur ist Teil der gesamten IT-Architektur. Ein häufiger Fallstrick bei Daten- und KI-Projekten ist die ausschließliche Konzentration auf die Bereitstellung von Vorhersageergebnissen aus Daten, ohne zu berücksichtigen, wie diese Ergebnisse von anderen nachgelagerten Anwendungen genutzt werden. Der Einsatz einer Analyselösung in anderen Anwendungen erfordert in der Regel zusätzliche Arbeit auf der Anwendungsseite, die Zusammenarbeit und Vorbereitungen erfordert, da die Quellanwendungen oft ihre eigenen Entwicklungsteams mit separaten Rückständen und Entwicklungsprioritäten haben. Wenn man also erst sehr spät an die Bereitstellung denkt, kann die Entwicklung für einen beträchtlichen Zeitraum auf Eis gelegt werden, was besonders frustrierend sein kann, da das Unternehmen bereits viel Zeit und Mühe in die Lösungsentwicklung investiert hat. Unabhängig davon lassen sich greifbare geschäftliche Auswirkungen nur mit einer vollständig integrierten End-to-End-Lösung erzielen. Um dies zu verhindern, ermutigen wir unsere Kunden immer wieder, die End-to-End-Lösungsarchitektur bereits in den frühen Phasen des Entwicklungsprozesses einer Analyselösung zu berücksichtigen. Das bedeutet, dass sich das Entwicklungsteam auf die Erstellung eines einfachen, funktionierenden End-to-End-Prototyps konzentrieren sollte, bevor es sich weiter mit der Entwicklung und Leistungsoptimierung des Analysemodells befasst.
Das DAIN Daten- und KI-Reifegradmodell
Dieser Artikel schließt unsere Serie zur Einführung des DAIN Data & AI Maturity Model (DAMM) ab. Wir haben zunächst einen Überblick über das Modell gegeben und sind dann auf die strategischen, menschlichen und technologischen Elemente eingegangen.
Um unseren ersten Beitrag zu diesem Thema zu zitieren: Der Einstieg in die Nutzung von Daten und KI in einem Unternehmen ist schwierig. Wir haben gesehen, wie viele Unternehmen bei ihrer Datentransformation gescheitert sind, und sind uns der häufigen Fallstricke bewusst geworden. Um Ihr Unternehmen auf den richtigen Weg zu bringen, müssen Sie zunächst verstehen, wo Sie stehen. Um Ihnen bei der Bewertung Ihres aktuellen Stands zu helfen, veröffentlichen wir ein Data & AI Maturity Model.
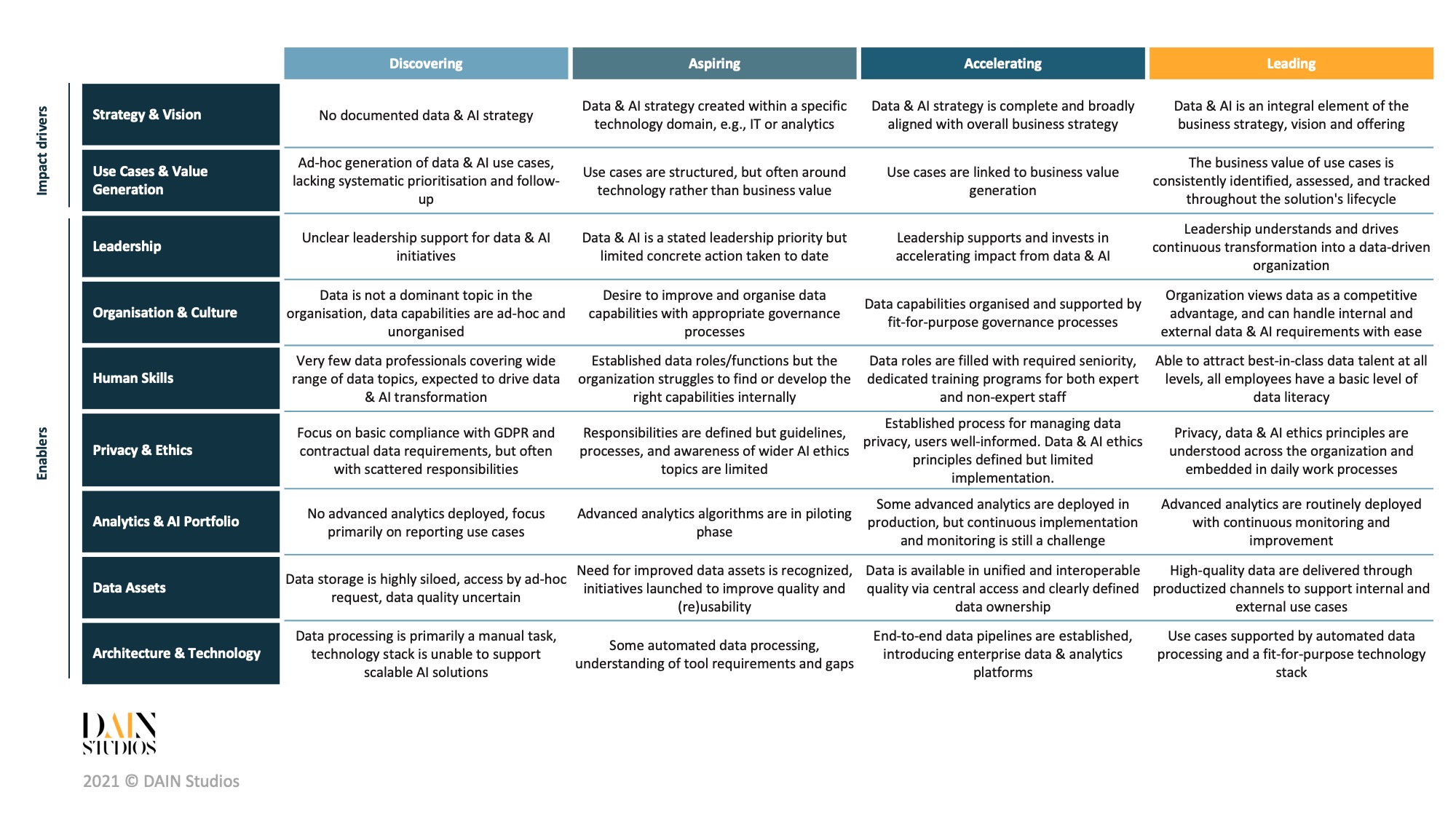
Sie können dieses Modell als Rahmen verwenden, der Sie durch Ihre Daten- und KI-Reise führt. Es hebt die wichtigsten Elemente hervor, auf die Sie achten sollten, und hilft Ihnen, sich zu orientieren, wo Ihr Unternehmen im Moment steht. Dies wiederum hilft Ihnen bei der Festlegung eines Ziels, so dass Sie daraus einige konsequente Maßnahmen ableiten und einen Fahrplan zur Erreichung dieses Zielzustands erstellen können.
Dies ist der Abschluss unserer Serie, in der wir die Elemente unseres DAIN Data & AI Maturity Model beschreiben. Schauen Sie sich auch unsere anderen Artikel in unserem DAIN Insights Bereich an, wo wir regelmäßig unsere Gedanken zu strategischen und technischen Themen rund um Daten und künstliche Intelligenz teilen.